Este post fue difundido como parte del Blogatón de ciencia de datos
Introducción
para comprender mejor sus datos, lo que ayuda en un mayor preprocesamiento de datos. Y la visualización de datos es clave, dado que agiliza el procedimiento de análisis de datos exploratorios y analiza los datos fácilmente a través de gráficos y gráficos maravillosos.

Tabla de contenido
- Visualización de datos
- Análisis exploratorio de datos
- Análisis univariado
- Datos categóricos
- Datos numéricos
- Análisis bivariado / multivariado
- Numérico y numérico
- Numérico y categórico
- Categórico y categórico
- Notas finales
Visualización de datos
La visualización de datos representa el texto o los datos numéricos en un formato visual, lo que facilita la comprensión de la información que expresan los datos. Nosotros, los humanos, recordamos las imágenes más fácilmente que el texto legible, por lo que Python nos proporciona varias bibliotecas para la visualización de datos como matplotlib, seaborn, plotly, etc. En este tutorial, usaremos Matplotlib y seaborn para realizar varias técnicas para explorar datos usando varios parcelas.
Análisis exploratorio de datos
Crear hipótesis, probar varias suposiciones comerciales mientras se trata con cualquier declaración de problema de aprendizaje automático es muy importante y esto es lo que EDA ayuda a lograr. Hay varias herramientas y técnicas para comprender sus datos, y la necesidad básica es que debe tener el conocimiento de Numpy para operaciones matemáticas y Pandas para manipulación de datos.
Usaremos un conjunto de datos de Titanic muy popular con el que todo el mundo está familiarizado y puede descargarlo de aquí.
Ahora comencemos a explorar datos y estudiar diferentes gráficos de visualización de datos con diferentes tipos de datos. Y para demostrar algunas de las técnicas, además usaremos un conjunto de datos incorporado de seaborn como datos de consejos que explican los consejos que cada camarero recibe de diferentes clientes.
comencemos importando bibliotecas y cargando datos
import numpy as np
import pandas pd
import matplotlib.pyplot as plt
import seaborn as sns
from seaborn import load_dataset
#titanic dataset
data = pd.read_csv("titanic_train.csv")
#tips dataset
tips = load_dataset("tips")
Análisis univariado
El análisis univariado es la forma más simple de análisis donde exploramos una sola variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos..... Se realiza un análisis univariado para describir los datos de una mejor manera. realizamos análisis univariados de variables numéricas y categóricas de manera distinto debido a que el trazado utiliza gráficos diferentes.
Datos categóricos
Una variable que tiene información basada en texto se conoce como variables categóricas. veamos varios gráficos que podemos utilizar para visualizar datos categóricos.
1) CountPlot
Countplot es simplemente un gráfico de recuento de frecuencias en forma de gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad..... Traza el recuento de cada categoría en una barra separada. Cuando usamos la función de recuento de valores de los pandas en cualquier columna, es la misma forma visual de la función de recuento de valores. En nuestra variable de destino de datos se sobrevive y es categórica, por lo tanto tracemos una gráfica de conteo de esto.
sns.countplot(data['Survived'])
plt.show()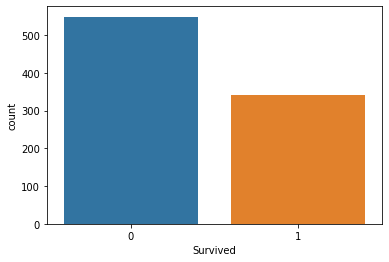
2) gráfico circularEl gráfico circular, también conocido como diagrama de sectores, es una representación visual que muestra la proporción de diferentes partes respecto a un todo. Se utiliza comúnmente en estadísticas para ilustrar la distribución de datos categóricos. Cada sección del gráfico representa un porcentaje del total, facilitando la comparación entre categorías. Su diseño claro y conciso lo convierte en una herramienta efectiva para la presentación de información cuantitativa....
El gráfico circular además es el mismo que el gráfico de conteo, solo le brinda información adicional sobre el porcentaje de presencia de cada categoría en los datos, lo que significa qué categoría obtiene la cantidad de ponderación en los datos. veamos en la columna Sexo, cuál es el porcentaje de miembros masculinos y femeninos que viajan.
data['Sex'].value_counts().plot(kind="pie", autopct="%.2f")
plt.show()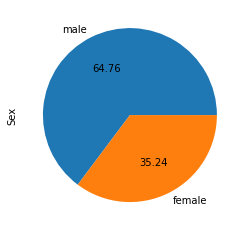
Datos numéricos
El análisis de datos numéricos es esencial debido a que comprender la distribución de variables ayuda a procesar más los datos. La mayoría de las veces encontrará mucha inconsistencia con los datos numéricos, por lo tanto explore las variables numéricas.
1) Histograma
Un histograma es una gráfica de distribución de valores de columnas numéricas. Simplemente crea bins en varios rangos de valores y los traza donde podemos visualizar cómo se distribuyen los valores. Podemos ver dónde se encuentran más valores, como positivo, negativo o en el centro (media). Echemos un vistazo a la columna Edad.
plt.hist(data['Age'], bins=5)
plt.show()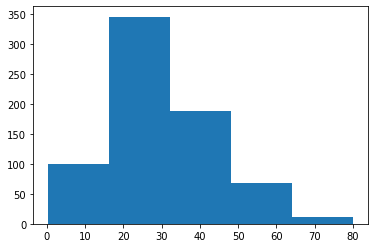
2) Distplot
Distplot además se conoce como el segundo histograma porque se trata de una versión ligeramente mejorada del histograma. Distplot nos da un KDE (Estimación de densidad de kernel) sobre histograma que explica PDF (Función de densidad de probabilidad), lo que significa cuál es la probabilidad de que ocurra cada valor en esta columna. Si ha estudiado estadísticas antes, definitivamente debería conocer la función PDF.
sns.distplot(data['Age']) plt.show()
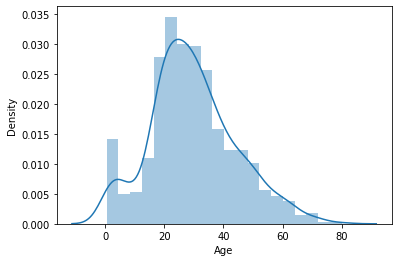
3) Diagrama de caja
Boxplot es una trama muy interesante que simplemente traza un resumen de 5 números. Para obtener un resumen de 5 números, necesitamos describir algunos términos.
- MedianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos....: valor medio en la serie después de ordenar
- Percentil: da cualquier número que sea el número de valores presentes antes de este percentil como, a modo de ejemplo, 50 por debajo del percentil 25, por lo que explica el total de 50 valores que están por debajo del percentil 25
- Mínimo y Máximo: estos no son valores mínimos y máximos, sino que describen el límite inferior y superior de la desviación estándar que se calcula usando el rango intercuartílico (IQR).
IQR = Q3 - Q1 Lower_boundary = Q1 - 1.5 * IQR Upper_bounday = Q3 + 1.5 * IQR
Aquí Q1 y Q3 son el primer cuantil (percentil 25) y el tercer cuantil (percentil 75)
Análisis bivariado / multivariado
Hemos estudiado varias parcelas para explorar datos categóricos y numéricos únicos. El Análisis Bivariado se utiliza cuando tenemos que explorar la vinculación entre 2 variables diferentes y tenemos que hacerlo debido a que, al final, nuestra tarea principal es explorar la vinculación entre las variables para construir un modelo poderoso. Y cuando analizamos más de 2 variables juntas, se conoce como análisis multivariado. trabajaremos en diferentes gráficos para Bivariate así como en Análisis Multivariante.
Numérico y numérico
Primero, exploremos las gráficas cuando ambas variables son numéricas.
1) Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....
Trazar la vinculación entre dos gráficos de dispersión de variables numéricas es un gráfico simple de hacer. Veamos la vinculación entre la cuenta total y la propina proporcionada a través de un diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada.....
sns.scatterplot(tips["total_bill"], tips["tip"])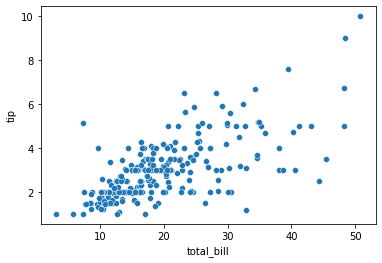
Análisis multivariado con diagrama de dispersión
además podemos graficar relaciones de 3 variables o 4 variables con un diagrama de dispersión. supongamos que queremos hallar la proporción separada de hombres y mujeres con la cuenta y la propina totales proporcionadas.
sns.scatterplot(tips["total_bill"], tips["tip"], hue=tips["sex"])
plt.show()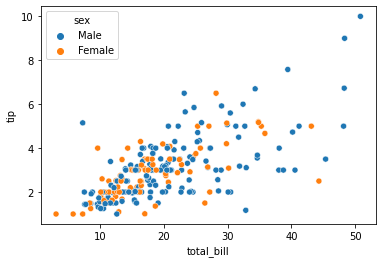
Además podemos ver análisis multivariados de 4 variables con diagramas de dispersión usando argumentos de estilo. Supongamos que ahora, junto con el género, además quiero saber si el cliente era fumador o no para que podamos hacer esto.
sns.scatterplot(tips["total_bill"], tips["tip"], hue=tips["sex"], style=tips['smoker'])
plt.show()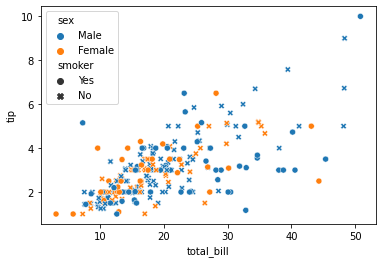
Numérico y categórico
Si una variable es numérica y la otra es categórica, existen varias gráficas que podemos utilizar para el análisis bivariado y multivariado.
1) Gráfico de barras
El diagrama de barras es un diagrama simple que podemos utilizar para trazar una variable categórica en el eje xy una variable numérica en el eje y y explorar la vinculación entre ambas variables. La punta negra en la parte de arriba de cada barra muestra el intervalo de confianza. exploremos P-Class con la edad.
sns.barplot(data['Pclass'], data['Age'])
plt.show()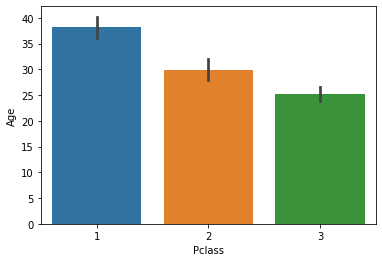
Análisis multivariante a través de gráfico de barras
El argumento de Hue es muy útil y ayuda a analizar más de 2 variables. Ahora, junto con la vinculación anterior, queremos ver con el género.
sns.barplot(data['Pclass'], data['Fare'], hue = data["Sex"])
plt.show()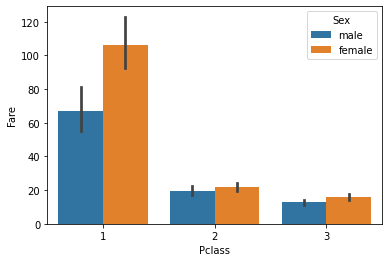
2) Diagrama de caja
Ya hemos estudiado sobre diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... en el análisis univariante anterior. podemos dibujar una gráfica de caja separada para ambas variables. Exploremos el género con la edad usando un diagrama de caja.
sns.boxplot(data['Sex'], data["Age"])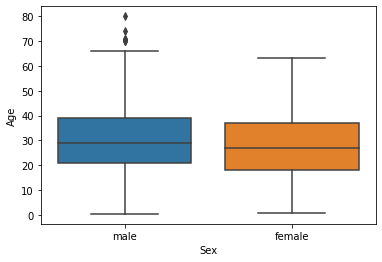
Análisis multivariado con diagrama de caja
Junto con la edad y el género, veamos quién ha sobrevivido y quién no.
sns.boxplot(data['Sex'], data["Age"], data["Survived"])
plt.show()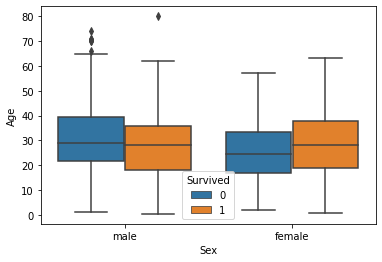
3) Distplot
Distplot explica la función PDF a través de la estimación de la densidad del kernel. Distplot no tiene un parámetro de tono, pero podemos crearlo. Supongamos que queremos ver la probabilidad de personas con un rango de edad de probabilidad de supervivencia y averiguar cuya probabilidad de supervivencia es alta para el rango de edad de la tasa de mortalidad.
sns.distplot(data[data['Survived'] == 0]['Age'], hist=False, color="blue")
sns.distplot(data[data['Survived'] == 1]['Age'], hist=False, color="orange")
plt.show()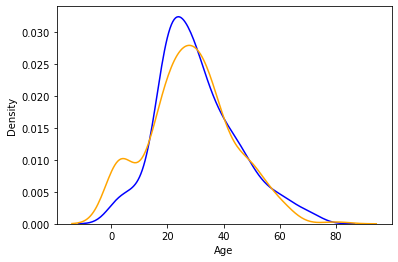
Como podemos ver, el gráfico es verdaderamente muy interesante. el azul muestra la probabilidad de morir y el gráfico naranja muestra la probabilidad de supervivencia. Si lo observamos podemos ver que la probabilidad de supervivencia de los niños es mayor que la muerte y que es todo lo contrario en el caso de los ancianos. Este pequeño análisis dice a veces algunas cosas importantes sobre los datos y ayuda al momento de preparar historias de datos.
Categórico y categórico
Ahora trabajaremos en columnas categóricas y categóricas.
1) Mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas....
Si en algún momento ha utilizado una función de tabla de referencias cruzadas de pandas, Heatmap es una representación visual equivalente de eso únicamente. Simplemente, muestra cuánta presencia de una categoría en vinculación con otra categoría está presente en el conjunto de datos. permítanme mostrar primero con la tabla de referencias cruzadas y posteriormente con el mapa de calor.
pd.crosstab(data['Pclass'], data['Survived'])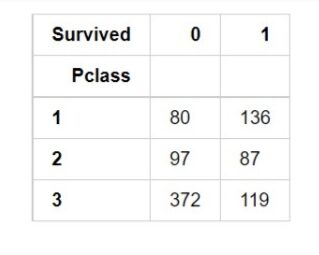
Ahora, con el mapa de calor, tenemos que hallar cuántas personas sobrevivieron y murieron.
sns.heatmap(pd.crosstab(data['Pclass'], data['Survived']))
2) Mapa de conglomerados
además podemos usar un mapa de conglomerados para comprender la vinculación entre dos variables categóricas. Un mapa de conglomerados simplemente traza un dendrograma que muestra las categorías de comportamiento equivalente juntas.
sns.clustermap(pd.crosstab(data['Parch'], data['Survived']))
plt.show()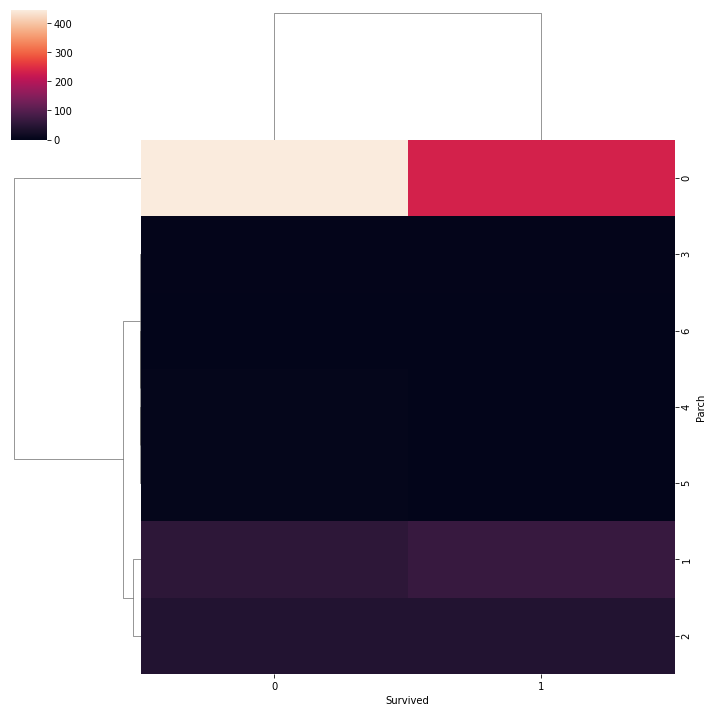
Si conoce los algoritmos de agrupación en clústeres principalmente sobre DBSCAN, entonces debería conocer el dendrograma. Entonces, estos son todos los gráficos que se usan principalmente al hacer análisis exploratorios. Hay algunas tramas más que puede dibujar como trama violenta, trama de líneas, una trama conjunta que no se usan principalmente.
El Cuaderno completo para más práctica en EDA y visualización de datos está habilitada en mis Cuadernos de kaggle, acceda a él desde aquí.
Notas finales
EDA es solo una clave para comprender y representar sus datos de una mejor manera, lo que, como consecuencia, lo ayuda a construir un modelo poderoso y más generalizado. La visualización de datos es fácil de realizar EDA, lo que facilita que otros comprendan nuestro análisis.
Espero que haya sido fácil ponerse al día con todas las tramas que hemos trazado. Si tiene alguna duda, menciónela en la sección de comentarios a continuación. Estaré feliz de poder ayudarte.
Sobre el Autor
Raghav Agrawal
Estoy cursando mi licenciatura en informática. Me gusta mucho la ciencia de datos y el big data. Me encanta trabajar con datos y aprender nuevas tecnologías. Por favor, siéntete libre de conectarte conmigo en Linkedin.





