Este artículo fue publicado como parte del Blogatón de ciencia de datos
Una anomalía es una observación que se desvía significativamente de todas las demás observaciones. Un sistema de detección de anomalías es un sistema que detecta anomalías en los datos. Una anomalía también se denomina valor atípico.
Ejemplo: Digamos que una columna de datos consta de los ingresos mensuales de los ciudadanos y esa columna también contiene el salario de Bill Gates. Entonces, el salario de Bill Gates es un valor atípico en estos datos.
Algoritmos de detección de anomalías
En este blog, veamos los siguientes algoritmos de detección de anomalías.
Estos son algunos de los muchos algoritmos disponibles y nunca se abstenga de explorar más algoritmos distintos a estos.
Importe las bibliotecas necesarias y escriba las funciones de la utilidad
# python outlier detection
!pip install pyod
import warnings
import numpy as np
import pandas as pd
from pyod.models.mad import MAD
from pyod.models.knn import KNN
from pyod.models.lof import LOF
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# data for anomaly detection
data_values = [['2021-05-1', 45000.0],
['2021-05-2', 70000.0],
['2021-05-3', 250000.0],
['2021-05-4', 70000.0],
['2021-05-5', 45000.0],
['2021-05-6', 55000.0],
['2021-05-7', 35000.0],
['2021-05-8', 60000.0],
['2021-05-9', 45000.0],
['2021-05-10', 25000.0],
['2021-05-11', 142936.0],
['2021-05-12', 138026.0],
['2021-05-13', 28347.0],
['2021-05-14', 40962.66],
['2021-05-15', 34543.0],
['2021-05-16', 40962.66],
['2021-05-17', 25207.0],
['2021-05-18', 37502.0],
['2021-05-19', 29589.0],
['2021-05-20', 78404.0],
['2021-05-21', 26593.0],
['2021-05-22', 123267.0],
['2021-05-23', 46880.0],
['2021-05-24', 65361.0],
['2021-05-25', 46042.0],
['2021-05-26', 48209.0],
['2021-05-27', 44461.0],
['2021-05-28', 90866.0],
['2021-05-29', 46886.0],
['2021-05-30', 33456.0],
['2021-05-31', 46251.0],
['2021-06-1', 29370.0],
['2021-06-2', 165620.0],
['2021-06-3', 20317.0]]
data = pd.DataFrame(data_values , columns=['date', 'amount'])
def fit_model(model, data, column='amount'):
# fit the model and predict it
df = data.copy()
data_to_predict = data[column].to_numpy().reshape(-1, 1)
predictions = model.fit_predict(data_to_predict)
df['Predictions'] = predictions
return df
def plot_anomalies(df, x='date', y='amount'):
# categories will be having values from 0 to n
# for each values in 0 to n it is mapped in colormap
categories = df['Predictions'].to_numpy()
colormap = np.array(['g', 'r'])
f = plt.figure(figsize=(12, 4))
f = plt.scatter(df[x], df[y], c=colormap[categories])
f = plt.xlabel(x)
f = plt.ylabel(y)
f = plt.xticks(rotation=90)
plt.show()
Los datos anteriores constan de dos columnas, a saber, fecha y monto, podemos asumir que los datos contienen el monto de ventas de una empresa de exhibición de panadería.
¿Qué hace la función fit_model?
- La función fit_model toma el modelo y los datos como entrada, aquí estamos encontrando anomalías en la columna de cantidad.
- Después de eso, cambia la forma de los datos en datos unidimensionales y se ajusta al modelo proporcionado y predice las anomalías en los datos y los almacena en la columna de predicciones del marco de datos proporcionado, y lo devuelve.
Rango intercuartil
Percentiles:
Cuartiles:
-
1er cuartil = percentil 25
-
2do cuartil = percentil 50
-
3.er cuartil = percentil 75
Rango intercuartil (IQR):
IQR = 3er cuartil – 1er cuartil
Anomalías = [1st Quartile – (1.5 * IQR)] o [3rd Quartile + (1.5 * IQR)]
Las anomalías se encuentran debajo [1st Quartile – (1.5 * IQR)] y por encima [3rd Quartile + (1.5 * IQR)] estos valores.

def find_anomalies(value, lower_threshold, upper_threshold):
if value < lower_threshold or value > upper_threshold:
return 1
else: return 0
def iqr_anomaly_detector(data, column='amount', threshold=1.1):
df = data.copy()
quartiles = dict(data[column].quantile([.25, .50, .75]))
quartile_3, quartile_1 = quartiles[0.75], quartiles[0.25]
iqr = quartile_3 - quartile_1
lower_threshold = quartile_1 - (threshold * iqr)
upper_threshold = quartile_3 + (threshold * iqr)
print(f"Lower threshold: {lower_threshold}, nUpper threshold: {upper_threshold}n")
df['Predictions'] = data[column].apply(find_anomalies, args=(lower_threshold, upper_threshold))
return df
iqr_df = iqr_anomaly_detector(data)
plot_anomalies(iqr_df)
# output
# Lower threshold: -2944.050000000003,
# Upper threshold: 106441.55
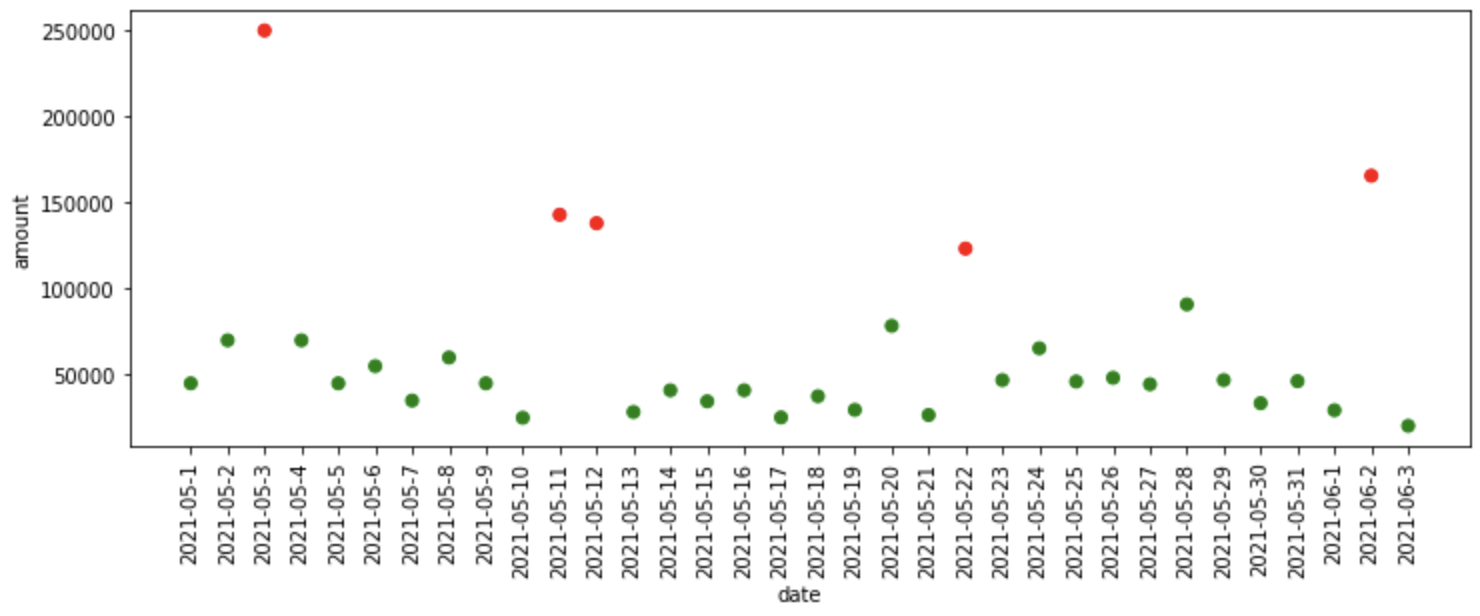
¿Qué sucedió en el código anterior?
- En primer lugar, averigua el percentil 25 y 75, es decir, se encontraron el 1er y 3er cuartil.
- Y luego, se encuentra el rango intercuartil que es la diferencia entre el tercer y primer cuartil.
- Después de eso, estamos encontrando el umbral superior e inferior por encima y por debajo del cual se encuentran las anomalías, respectivamente.
- La función find_anomalies anterior encuentra las anomalías en los datos de acuerdo con los umbrales proporcionados.
- Finalmente, estamos trazando las anomalías encontradas.
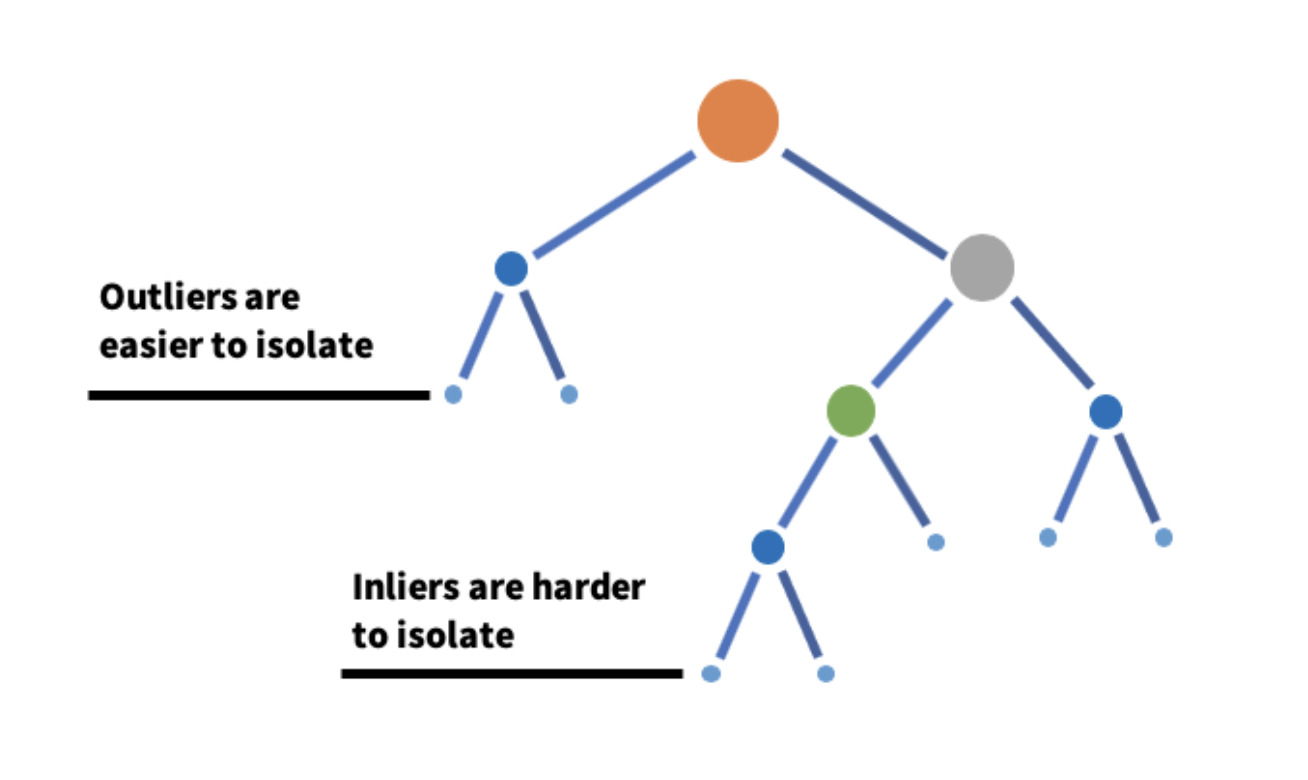
Bosque de aislamiento
Isolation Forest es un algoritmo que detecta anomalías tomando un subconjunto de datos y construyendo muchos árboles de aislamiento a partir de él.
-
La idea central es que las anomalías son mucho más fáciles de aislar que las observaciones normales y las anomalías existen en profundidades mucho más pequeñas de un árbol de aislamiento. Un árbol de aislamiento se construye seleccionando aleatoriamente una característica y seleccionando aleatoriamente un valor de esa característica. Un bosque se construye agregando todos los árboles de aislamiento.
iso_forest = IsolationForest(n_estimators=125) iso_df = fit_model(iso_forest, data) iso_df['Predictions'] = iso_df['Predictions'].map(lambda x: 1 if x==-1 else 0) plot_anomalies(iso_df)
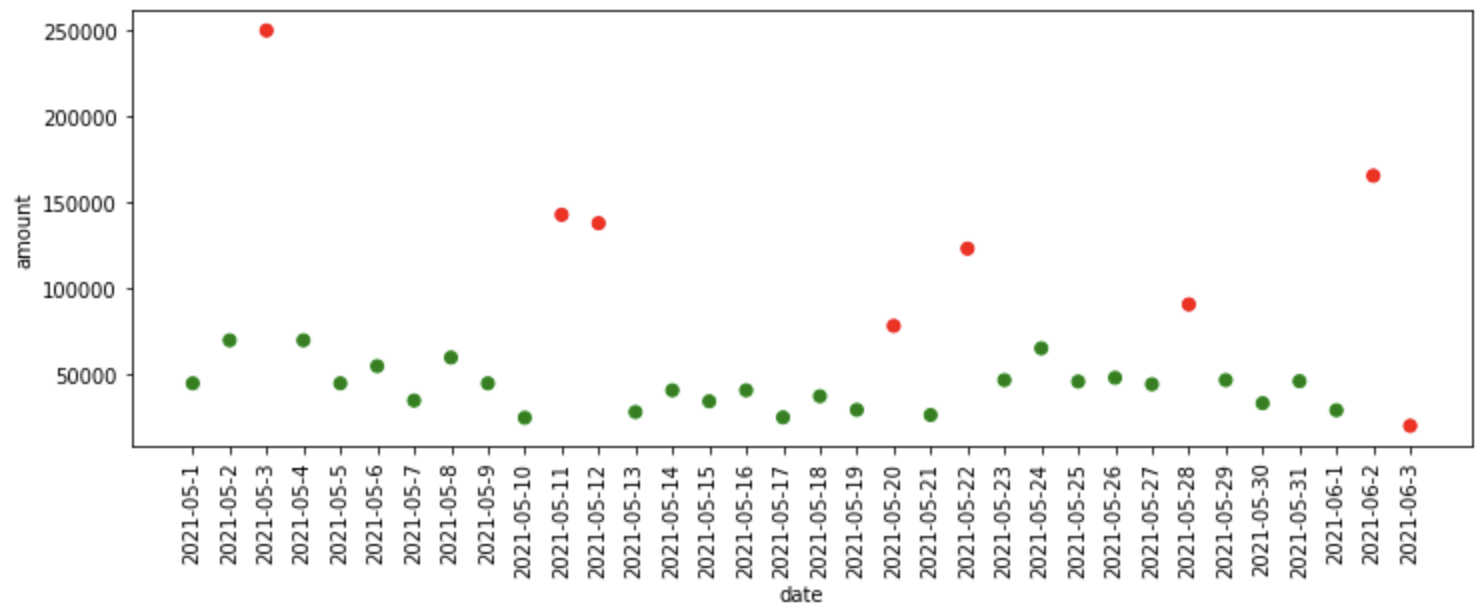
¿Qué sucedió en el código anterior?
- Primero, definimos el modelo Isolation Forest con 125 árboles de aislamiento, luego pasamos el modelo, los datos como entradas a la función fit_model, donde ajusta el modelo a los datos y nos proporciona predicciones.
- El bosque de aislamiento asigna -1 a los datos anómalos y 1 a los datos normales, por lo que para simplificar, convertimos la predicción de datos normales (1) a 0 y la predicción de datos anómalos (-1) a 1.
- Finalmente, trazamos las anomalías predichas por Isolation Forest.
Desviación absoluta mediana
La desviación absoluta media es la diferencia entre cada observación y la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... de esas observaciones. Una observación que se desvía más del resto de la observación se considera una anomalía.
¿Por qué mediana en lugar de media?
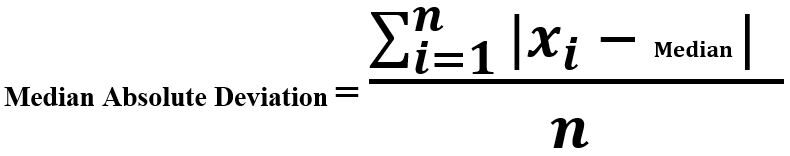
"""Median Absolute Deviation""" mad_model = MAD() mad_df = fit_model(mad_model, data) plot_anomalies(mad_df)
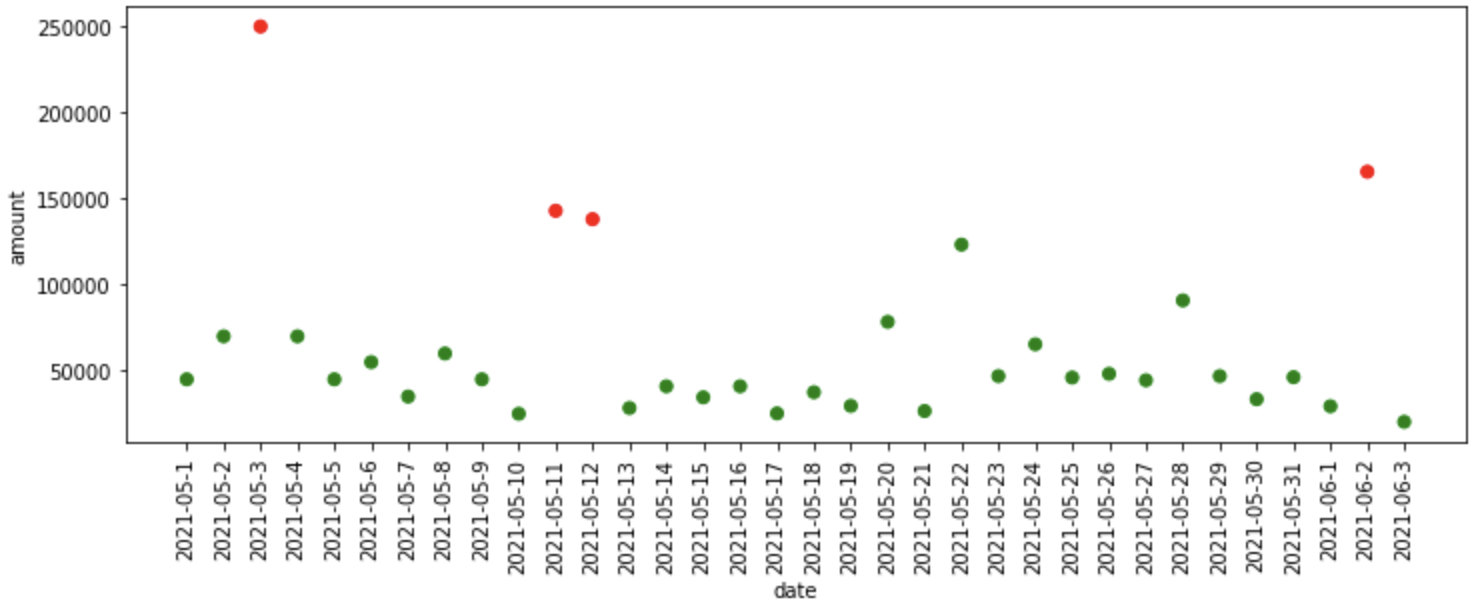
¿Qué sucedió en el código anterior?
- Primero, definimos el modelo de Desviación Absoluta Mediana que está disponible en la biblioteca pyod, luego pasamos el modelo, los datos como entradas a la función fit_model, donde ajusta el modelo a los datos y nos proporciona predicciones.
- Finalmente, trazamos las anomalías predichas por el modelo MAD.
Algoritmo de vecinos más cercanos K
El algoritmo de K-vecinos más cercanos detecta anomalías utilizando las distancias de los k vecinos más cercanos como puntuaciones de anomalía. La idea es que si una observación está muy lejos de las otras observaciones, entonces esa observación se considera una anomalía.
"""KNN Based Outlier Detection""" knn_model = KNN() knn_df = fit_model(knn_model, data) plot_anomalies(knn_df)
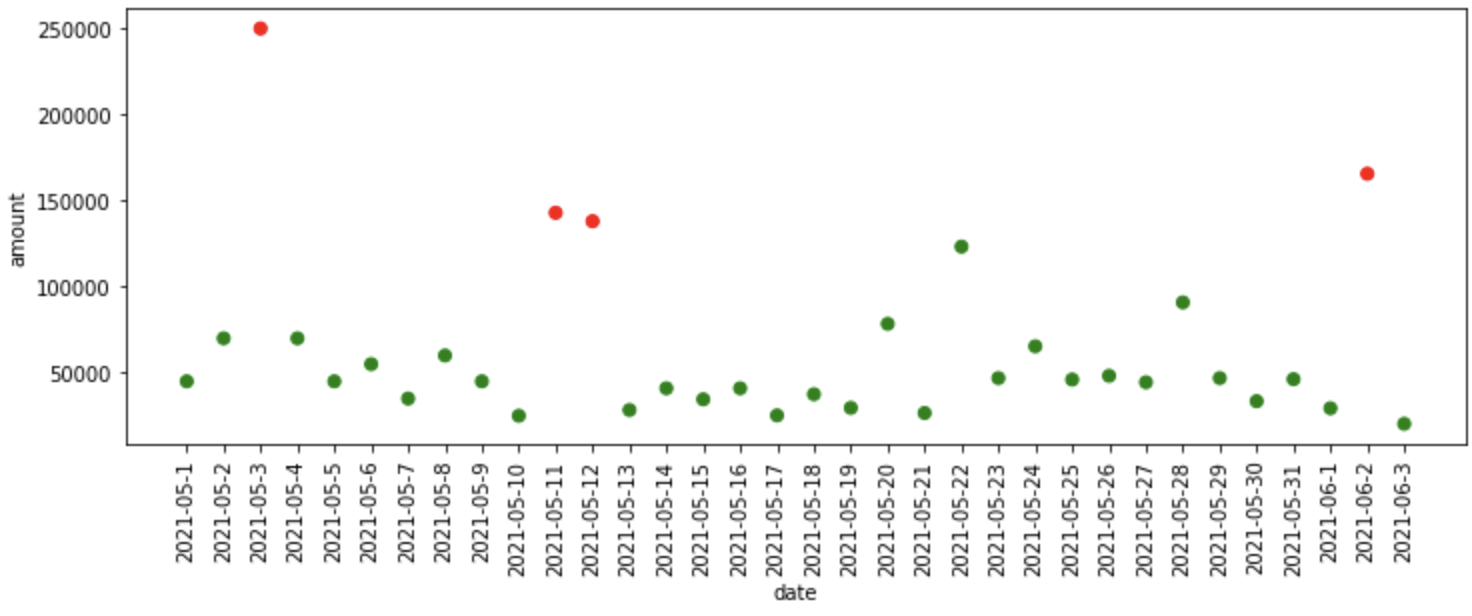
¿Qué sucedió en el código anterior?
- Primero, definimos el modelo de vecino más cercano K que está disponible en la biblioteca pyod, luego pasamos el modelo, los datos como entradas a la función fit_model, donde ajusta el modelo a los datos y nos proporciona predicciones.
- Finalmente, trazamos las anomalías predichas por el modelo KNN.
Hay una gran cantidad de modelos disponibles en la biblioteca PyOD como,
- CBLOF (factor de valor atípico local basado en clústeres)
- LOF (factor de valor atípico local)
- HBOS (detección de valores atípicos basada en histograma)
- OCSVM (SVM de una clase)
Nunca se abstenga de experimentar con más algoritmos disponibles en PyOD.
Las implementaciones prácticas de los algoritmos anteriores se implementan en el siguiente cuaderno
Referencias
[1] PyOD, biblioteca de detección de valores atípicos de Python
¡Gracias!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





