Considere el siguiente hecho:
Facebook tiene en este momento más de mil millones de usuarios activos cada mes
Dediquemos unos segundos a pensar qué información suele almacenar Facebook sobre sus usuarios. Algo de esto es:
- Datos demográficos básicos (a modo de ejemplo, fecha de nacimiento, sexo, ubicación actual, ubicación anterior, universidad)
- Pacto de actividades y actualizaciones de los usuarios (sus fotos, comentarios, me gusta, aplicaciones que ha utilizado, juegos que ha jugado, mensajes, chats, etc.)
- Tu red social (tus amigos, sus círculos, cómo estás relacionado, etc.)
- Intereses de los usuarios (libros leídos, películas vistas, lugares, etc.)

Usando esta y mucha otra información (a modo de ejemplo, en qué hizo clic un usuario, qué leyó y cuánto tiempo pasó en él), Facebook realiza lo siguiente en tiempo real:
- Recomendar personas que pueda conocer y conexiones mutuas con ellas.
- Utilice sus actividades actuales y pasadas para comprender lo que le interesa
- Diríjase a usted con actualizaciones, actividades y anuncios que podrían interesarle más.
Al mismo tiempo de estas, hay actividades de tiempo cercano (actualizadas en lotes y no en tiempo real) como la cantidad de personas que hablan sobre una página, las personas a las que se llega en una semana.
Ahora, imagine el tipo de infraestructura de datos necesaria para ejecutar Facebook, el tamaño de su centro de datos, la potencia de procesamiento necesaria para satisfacer los requerimientos del usuario. La magnitud puede ser emocionante o aterradora, según cómo se mire.
La próxima infografía de IBM resalta la magnitud de los requerimientos / procesamiento de datos para algunas instituciones similares:

Este tipo de tamaño y escala no fue escuchado por ningún analista hasta hace unos años y la infraestructura de datos en la que algunas de estas instituciones habían invertido no estaba preparada para manejar esta escala. Esto se suele denominar problema de Big Data.
Entonces, ¿qué es Big Data?
Big Data son datos que son demasiado grandes, complejos y dinámicos para que cualquier herramienta de datos convencional los capture, almacene, administre y analice. Las herramientas tradicionales se diseñaron teniendo en cuenta una escala. A modo de ejemplo, cuando una organización quisiera invertir en una solución de Business Intelligence, el socio de implementación vendría, estudiaría los requerimientos comerciales y posteriormente crearía una solución para satisfacer estos requerimientos.
Si el requisito de esta organización aumenta con el tiempo o si desea ejecutar un análisis más granular, tuvo que reinvertir en infraestructura de datos. El costo de los recursos involucrados en la ampliación de los recursos que regularmente se usan para incrementar exponencialmente. Al mismo tiempo, habría una limitación en el tamaño al que podría escalar (a modo de ejemplo, tamaño de la máquina, CPU, RAM, etc.). Estos sistemas tradicionales no podrían soportar la escala requerida por algunas de las compañías de Internet.
¿En qué se diferencia el big data de los datos tradicionales?
Por suerte o desafortunadamente, no existe un límite de tamaño / paramétrico para elegir si los datos son «big data» o no. Los macrodatos se caracterizan típicamente sobre la base de lo que se conoce popularmente como 3 Vs:
- Volumen – En la actualidad, hay instituciones que producen terabytes de datos en un día. Con el aumento de datos, deberá dejar algunos datos sin analizar, si desea usar herramientas tradicionales. A medida que el tamaño de los datos aumente aún más, dejará más y más datos sin analizar. Esto significa dejar valor sobre la mesa. Tiene toda la información sobre lo que el cliente está haciendo y diciendo, ¡pero no puede comprender! – una señal segura de que está tratando con datos más grandes que los que admite su sistema.
- Variedad – Aunque el volumen es solo el comienzo, la variedad es lo que dificulta mucho las herramientas tradicionales. Las herramientas tradicionales funcionan mejor con datos estructurados. Requieren que los datos tengan una estructura y formato particulares para que tengan sentido. A pesar de esto, la avalancha de datos provenientes de correos electrónicos, comentarios de clientes, foros de redes sociales, el recorrido del cliente en el portal web y los centros de llamadas no están estructurados por naturaleza o, en el mejor de los casos, están semiestructurados.
- Velocidad – El ritmo al que se generan los datos es tan crítico como los otros dos factores. La velocidad con la que una compañía puede analizar los datos eventualmente se convertiría en una ventaja competitiva para ellos. Es su velocidad de análisis lo que posibilita a Google predecir la ubicación de los pacientes con gripe casi en tiempo real. Por eso, si no puede analizar datos a una velocidad más rápida que su flujo de entrada, es factible que necesite una solución de big data.
Individualmente, cada una de estas V aún se puede arreglar con la ayuda de soluciones tradicionales. A modo de ejemplo, si la mayoría de sus datos están estructurados, aún puede obtener del 80% al 90% del valor comercial por medio de herramientas tradicionales. A pesar de esto, si se enfrenta a un desafío con las tres V, sabrá que se trata de «big data».

¿Cuándo necesita una solución de big data?
Aunque las 3 V le dirán si está tratando con “big data” o no, es factible que necesite o no una solución de big data según sus necesidades. A continuación se muestran escenarios en los que las soluciones de big data son intrínsecamente más adecuadas:
- Cuando se trata de grandes datos semiestructurados o no estructurados de múltiples fuentes
- Necesita analizar todos sus datos y no puede trabajar con muestrearlos.
- El procedimiento es de naturaleza iterativa (a modo de ejemplo, búsquedas en el buscador de Google, búsqueda de gráficos en Facebook)
¿Cómo funciona la respuesta de big data?
Aunque las limitaciones de las soluciones tradicionales son claras, ¿cómo las resuelven las soluciones de big data? Las soluciones de Big Data funcionan en una arquitectura fundamentalmente distinto que se basa en las siguientes características (ilustrativas a continuación):
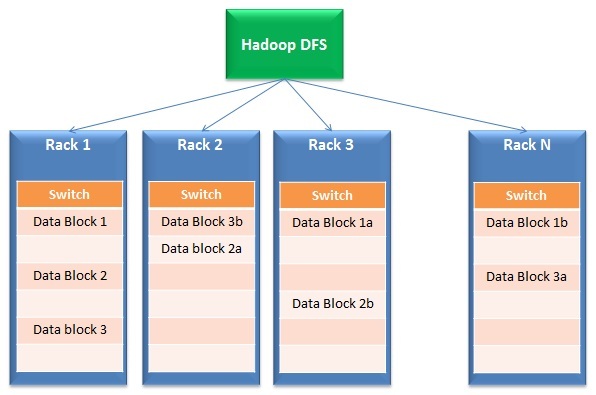
- Distribución de datos y procesamiento paralelo: Las soluciones de big data funcionan en almacenamiento distribuido y procesamiento paralelo. Resumidamente, los archivos se dividen en varios bloques pequeños y se almacenan en diferentes unidades (llamadas bastidores). Después, el procesamiento ocurre en paralelo en estos bloques y los resultados se fusionan nuevamente. La primera parte de la operación se denomina típicamente Sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... (DFS) mientras que la segunda parte se llama Mapa reducido.
- Tolerancia al fracaso: Por la naturaleza de su diseño, la respuesta de big data tiene redundancia integrada. A modo de ejemplo, Hadoop crea 3 copias de cada bloque de datos en al menos 2 racks. Por eso, inclusive si un bastidor completo falla o no está habilitada, la respuesta sigue funcionando. ¿Por qué está incorporado? Esta función posibilita que las soluciones de big data se amplíen inclusive en hardware básico económico en lugar de costosos discos SAN.
- Escalabilidad y flexibilidad: Esta es la génesis del paradigma completo de soluciones de big data. Puede agregar o quitar racks fácilmente del clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... sin preocuparse por el tamaño para el que se diseñó esta solución.
- Rentabilidad: Debido al uso de hardware básico, el costo de crear esta infraestructura es mucho menor que comprar servidores costosos con discos resistentes a fallas (a modo de ejemplo, SAN)
En resumen, ¿y si todo esto estuviera en la nube?
Aunque desarrollar una arquitectura de big data es rentable, hallar los recursos adecuados es difícil, lo que aumenta el costo de implementación.
Imagine una situación en la que un proveedor de servicios en la nube además se encarga de todas sus preocupaciones de TI / infraestructura. Usted se concentra en realizar análisis y entregar resultados a la compañía en lugar de organizar los racks y preocuparse por el alcance de su uso.
Todo lo que debe hacer es pagar según su uso. En la actualidad, existen soluciones de extremo a extremo disponibles en el mercado, donde no solo puede almacenar sus datos en la nube, sino además consultarlos y analizarlos en la nube. ¡Puede consultar terabytes de datos en cuestión de segundos y dejar toda la preocupación por esta infraestructura para otra persona!
Aunque he proporcionado una descripción general de las soluciones de big data, esto de ninguna manera cubre todo el espectro. El propósito es iniciar el viaje y estar preparados para la revolución que está en camino.





