Mientras trabajaba en el problema de ajuste de la aplicación Spark, dediqué una cantidad considerable de tiempo a tratar de dar sentido a las visualizaciones de la interfaz de usuario web de Spark. Spark Web UI es una herramienta muy útil para esta tarea. Para los principiantes, se vuelve muy difícil obtener intuiciones de un problema solo a partir de estas visualizaciones. Aunque hay muy buenos recursos sobre el rendimiento de Spark, la información estaba dispersa. Por lo tanto, sentí la necesidad de documentar y compartir mis aprendizajes.
Público objetivo y conclusiones
Esta publicación asume que los lectores tienen una comprensión básica de los conceptos de Spark. Esta publicación ayudará a los principiantes a identificar probables problemas de rendimiento en sus aplicaciones que se ejecutan desde una interfaz de usuario web de Spark. La atención se centra solo en la información que no es obvia a partir de la interfaz de usuario y las inferencias que se pueden extraer de esta información no obvia. Tenga en cuenta que no contiene una lista exhaustiva de información para interpretar de Spark Web UI, sino solo las que encontré relevantes para mi proyecto y, sin embargo, lo suficientemente generales para que la audiencia las conozca.
Interfaz de usuario web Spark
La interfaz de usuario web de Spark solo está disponible cuando la aplicación se está ejecutando. Para analizar ejecuciones pasadas, el servidor de historia debe estar habilitado para almacenar los registros de eventos que luego se pueden usar para completar la interfaz de usuario web.
Spark Web UI muestra información útil sobre su aplicación en las pestañas, a saber
- Ejecutores
- Medio ambiente
- Trabajos
- Etapas
- Almacenamiento
La publicación restante describe las intuiciones de cada una de las pestañas, en el orden mencionado.
Pestaña de ejecutores
Da información sobre las tareas ejecutadas por cada ejecutor.
Fig 1: Resumen de la pestaña Ejecutor
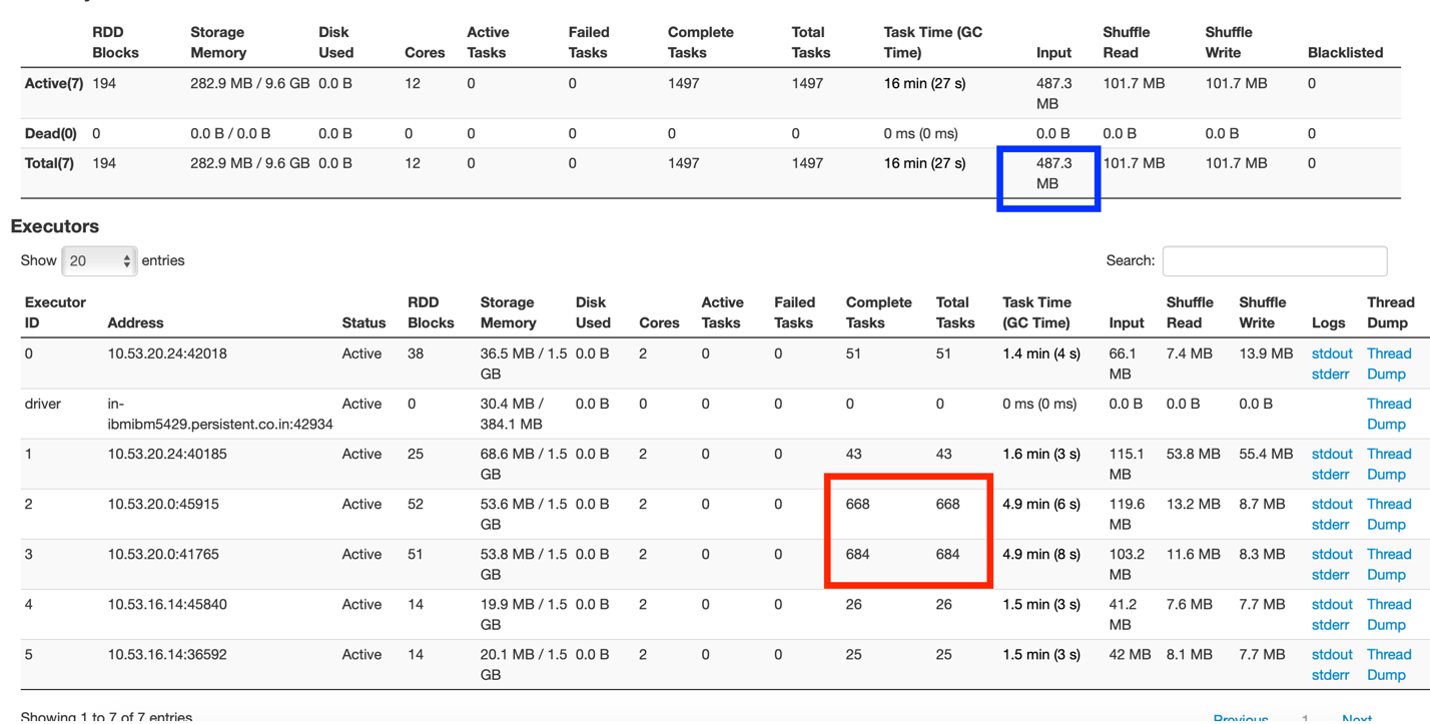
A partir de la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... 1, se puede entender que hay un controlador y 5 ejecutores, cada uno de los cuales se ejecuta con 2 núcleos y 3 GB de memoria.
La casilla marcada en rojo muestra la distribución desigual de las tareas en las que un nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... del clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... está exagerando las tareas, mientras que otros están relativamente inactivos.
La casilla marcada en azul muestra que el tamaño de los datos de entrada fue de 487,3 MB. Ahora, esta aplicación se ejecutó en un tamaño de conjunto de datos de 83 MB. El tamaño de los datos de entrada comprende la lectura del conjunto de datos original y las transferencias de datos aleatorios entre los nodos. Esto muestra que se han barajado muchos datos (aproximadamente 400+ MB) en la aplicación.
Pestaña de entorno
Hay muchos propiedades de chispa para controlar y ajustar la aplicación. Estas propiedades se pueden establecer al enviar el trabajo o al crear el objeto de contexto. A menos que la propiedad se agregue explícitamente, no se aplica. Nos equivocamos al asumir que las propiedades se aplican con sus valores predeterminados, cuando no se establecen explícitamente. Todas las propiedades aplicadas se pueden ver en la pestaña Entorno. Si la propiedad no se ve allí, significa que la propiedad no se ha aplicado en absoluto.
Pestaña trabajos
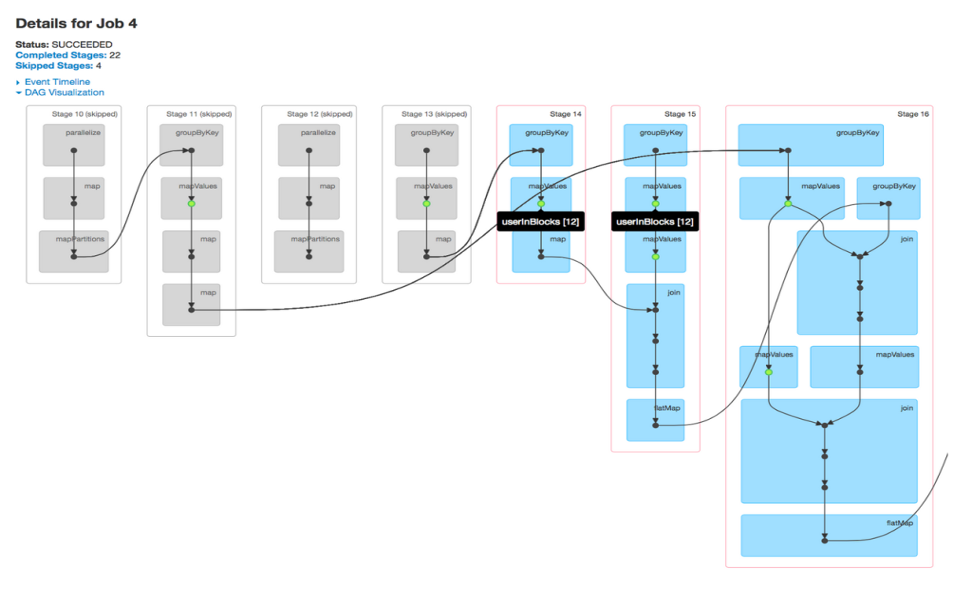
Un trabajo está asociado con una cadena de dependencias Resilient Distributed DatasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.... organizadas en un gráfico acíclico directo (DAG) que se parece a la Fig. 2. A partir de las visualizaciones de DAG, se pueden encontrar las etapas ejecutadas y el número de etapas omitidas. De forma predeterminada, la chispa no reutiliza sus pasos calculados en las etapas, a menos que se persista o se almacene en caché explícitamente. Las etapas omitidas son etapas en caché marcadas en gris, donde los valores de cálculo se almacenan en la memoria y no se vuelven a calcular después de acceder a HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información.... Un vistazo a la visualización de DAG es suficiente para saber si los cálculos RDD se realizan repetidamente o si se utilizan etapas en caché.
Fig 2: Visualización DAG de un trabajo
Pestaña etapas
Ofrece una visión más profunda de la aplicación que se ejecuta a nivel de tarea. Una etapa representa un segmento de trabajo realizado en paralelo por tareas individuales. Hay un mapeo 1-1 entre tareas y particiones de datos, es decir, 1 tarea por partición de datos. Uno puede profundizar en un trabajo, en etapas específicas y hasta cada tarea en una etapa desde la interfaz de usuario web de Spark.
La etapa ofrece una buena descripción general de las ejecuciones: visualizaciones de DAG, líneas de tiempo de eventos, métricas de resumen / agregación de sus tareas.
Prefiero mirar las líneas de tiempo de los eventos para analizar las tareas. Dan una representación pictórica de los detalles del tiempo invertido en la ejecución del escenario. Con un solo vistazo, podríamos hacer inferencias rápidas sobre qué tan bien se desempeñó la etapa y cómo podríamos mejorar aún más el tiempo de ejecución.
Fig 3 – Muestra de la línea de tiempo del evento
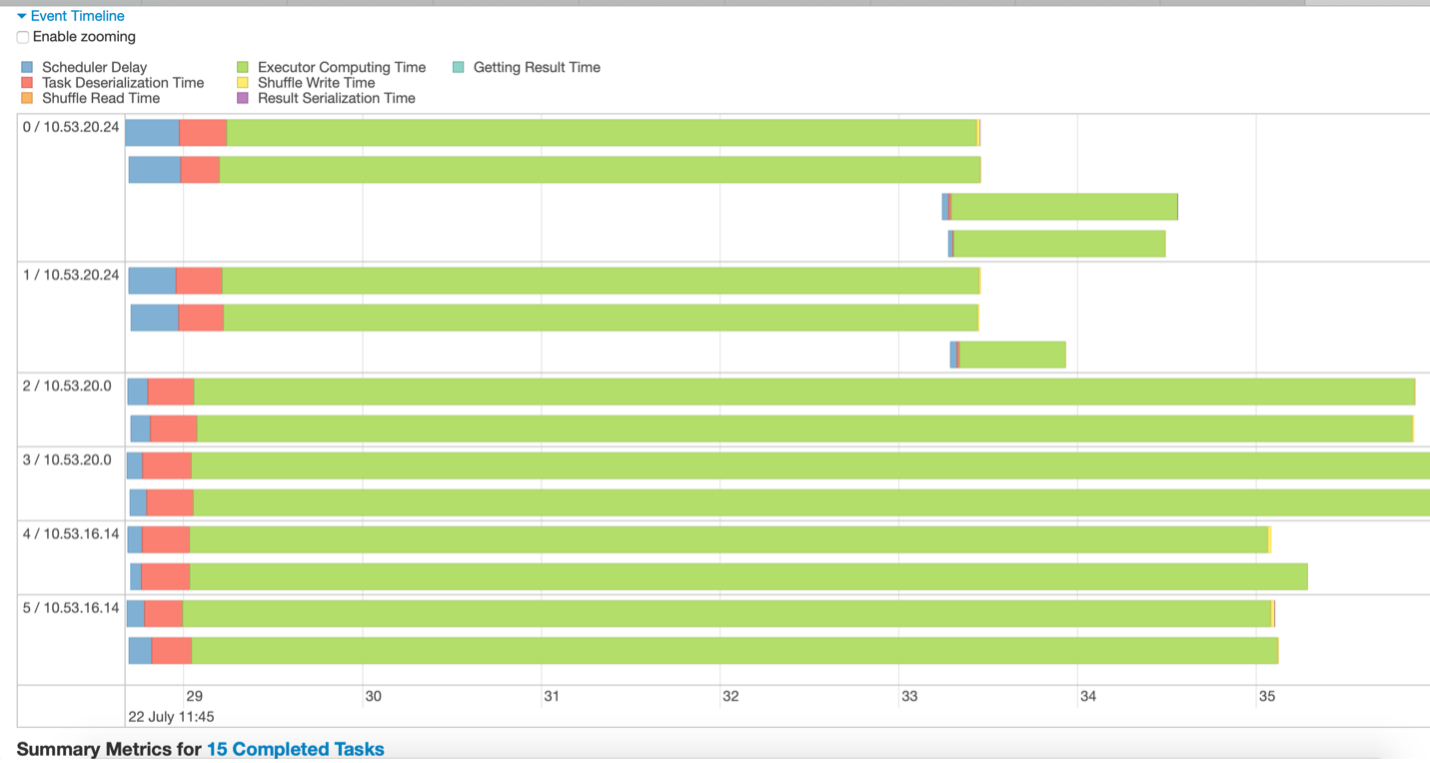
Por ejemplo, las inferencias extraídas de la figura 3 podrían ser:
- Los datos se dividen en 15 particiones. Por lo tanto, se están ejecutando 15 tareas (representadas con 15 líneas verdes).
- Las tareas se ejecutan en 3 nodos, cada uno con 2 ejecutores
- La etapa se completa solo cuando finaliza la tarea de ejecución más larga. Otros ejecutores permanecen inactivos hasta que finaliza la tarea más larga.
- Hay pocas tareas de ejecución prolongada, mientras que pocas tareas se ejecutan durante muy poco tiempo, lo que indica que los datos no están bien particionados.
- No se ha invertido mucho tiempo en el retraso del programador o la serialización en esta etapa, lo cual es bueno.
Fig. 4 – Cronología del evento de una etapa con muchas particiones de datos.
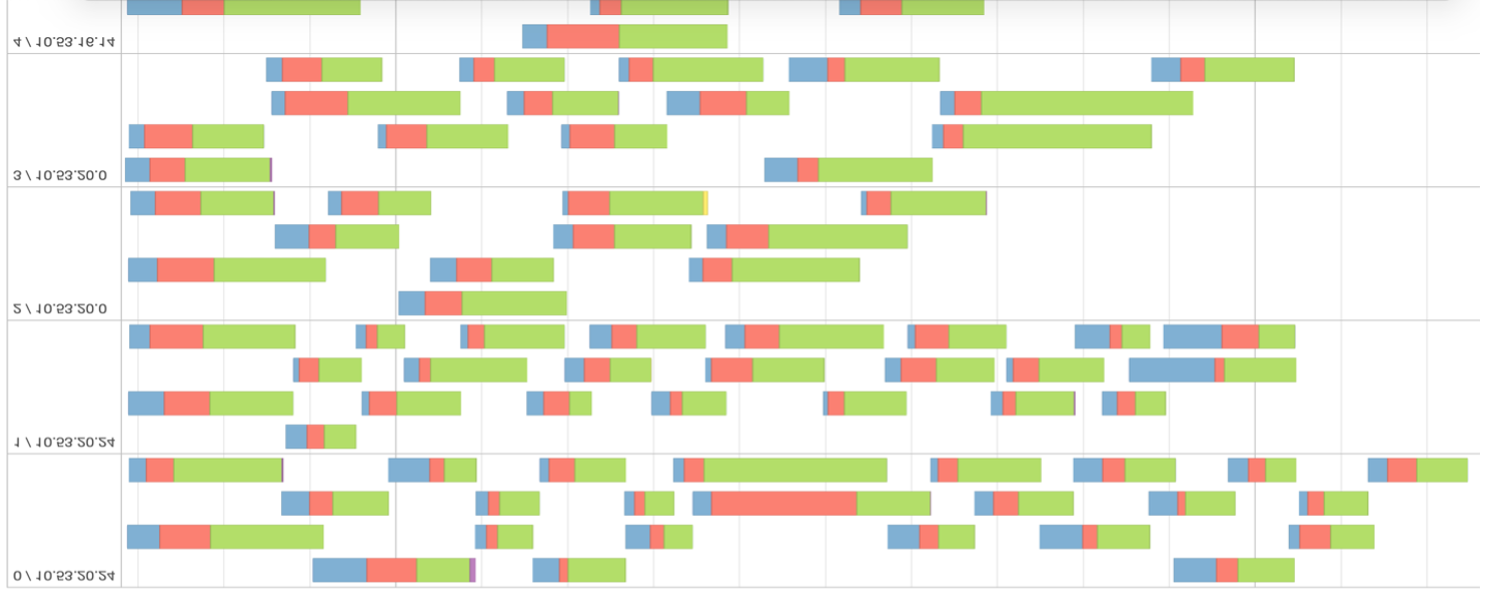
Observando la figura 4, podemos inferir que los datos no están bien distribuidos y particionados innecesariamente. A partir de la métrica de evaluación, se puede confirmar que la programación de tareas tomó más tiempo que el tiempo de ejecución real. Cuanto mayor sea el porcentaje de verde en la línea de tiempo, más eficiente será el cálculo de la etapa.
Es deseable tener un menor número de etapas en los trabajos. Siempre que los datos se mezclan, se crea una nueva etapa. Barajar es costoso y, por lo tanto, intente reducir la cantidad de etapas que necesita su programa.
Tamaño de datos de entrada
Otra información importante es observar el tamaño de entrada de los datos que se han barajado. Uno de los objetivos también es reducir el tamaño de estos datos aleatorios.
Fig. 5 – Descripción general de la pestaña Stages.
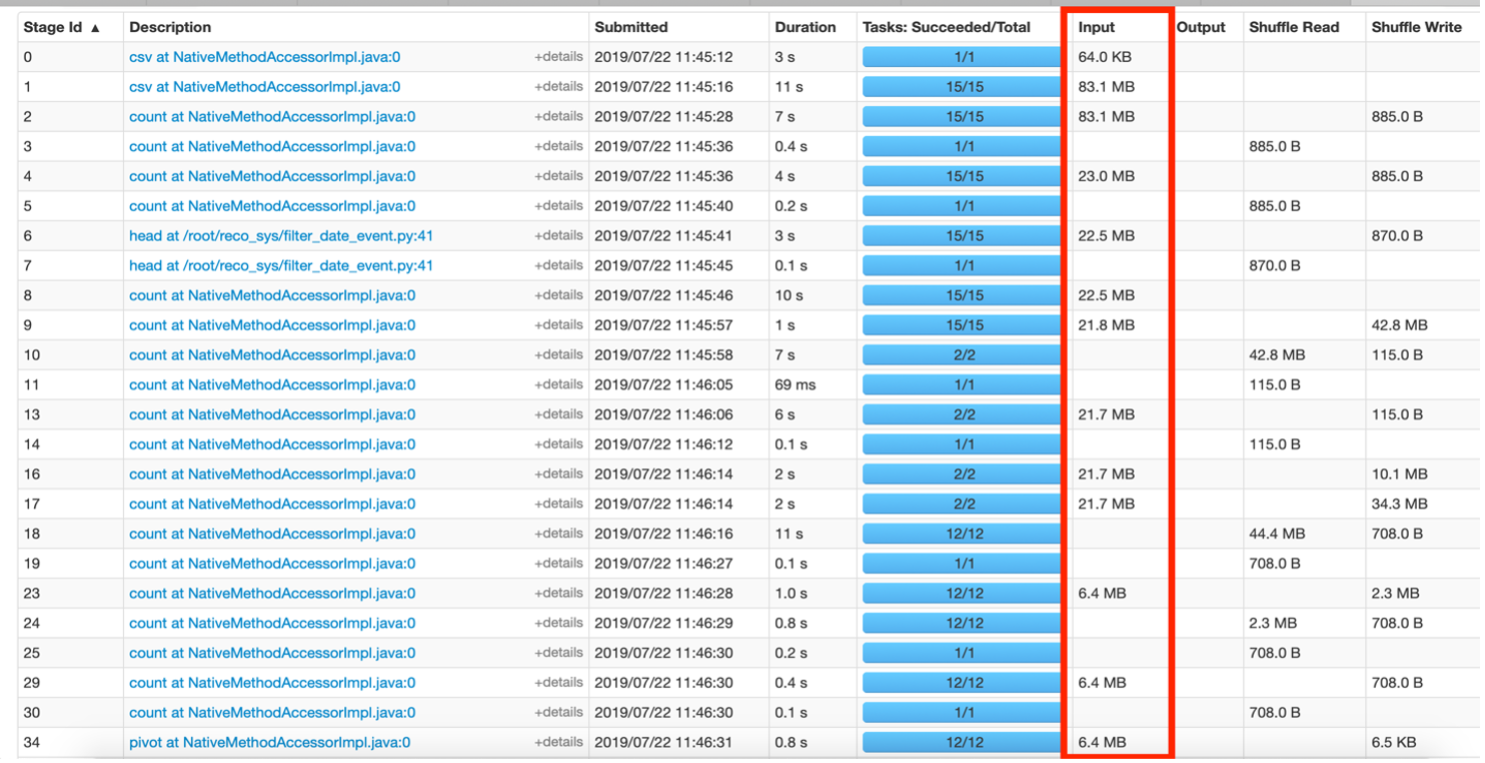
La figura 5 anterior muestra las etapas en las que los datos se mueven en MB. Esto sugiere que el código se puede mejorar para reducir el tamaño de los datos que se han intercambiado entre las etapas. Por ejemplo, digamos que si se aplicó un filtro en algunos datos para un evento ‘x’ dado, entonces en el RDD resultante, la columna “evento” se vuelve redundante ya que técnicamente todas las filas son del evento ‘x’. Esta columna podría eliminarse de futuros RDD creados a partir de estos datos filtrados para guardar información adicional transferida durante las operaciones de reproducción aleatoria.
FichaLa "Ficha" es un término utilizado en diversos contextos, generalmente para referirse a un documento o tarjeta que contiene información específica sobre un tema, persona o producto. En ámbitos académicos, se utiliza para registrar datos relevantes sobre investigaciones o fuentes bibliográficas. En el ámbito empresarial, las fichas pueden ser herramientas útiles para organizar datos de clientes o productos, facilitando la gestión y el acceso a la información.... de almacenamiento
Muestra solo los RDD que se han conservado, es decir, que utilizan persist () o cache (). Para hacerlo más legible, puede asignar un nombre al RDD mientras lo almacena usando setName (). Solo los RDD que desea conservar deben mostrarse en la pestaña Almacenamiento y podrían ser fácilmente reconocibles con los nombres personalizados proporcionados.
Resumen
Este artículo ayuda a proporcionar información para identificar los problemas de la interfaz de usuario web de Spark, como el tamaño de los datos que se han barajado, el tiempo de ejecución de las etapas, el recálculo de RDD debido a la falta de almacenamiento en caché. Si uno comprende sus datos y su aplicación, entonces la distribución de datos ideal y el número deseado de particiones podrían medirse infiriendo de la IU de ejecución. La sobrecarga de un nodo frente a otros en el clúster es otra área de mejora que podría verse en esta interfaz de usuario. La resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... de algunos de estos problemas se discute más en el Artículo de ajuste de rendimiento de Apache Spark.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





