Este post fue difundido como parte del Blogatón de ciencia de datos
¿Qué es la coincidencia de cadenas difusas?
La coincidencia difusa de cadenas es la técnica de hallar cadenas que coincidan con una cadena determinada de forma parcial y no exacta. Cuando un usuario escribe mal una palabra o ingresa una palabra parcialmente, la coincidencia de cadenas difusa ayuda a hallar la palabra correcta, como vemos en los motores de búsqueda.
El algoritmo detrás de la coincidencia de cadenas difusas no se limita a observar la equivalencia de dos cadenas, sino que cuantifica qué tan cerca están dos cadenas entre sí. Esto de forma general se hace usando una métrica de distancia conocida como ‘distancia de edición’. Esto determina la cercanía de dos cadenas al identificar las alteraciones mínimas imprescindibles para convertir una cadena en otra. Existen diferentes tipos de distancias de edición que se pueden utilizar como la distancia de Levenshtein, la distancia de Hamming, la distancia de Jaro, etc.
Ilustremos cómo se calcula la distancia de Levenshtein.
Ejemplo 1:
Cadena 1 = ‘Poner’
Cadena 2 = ‘Pat’
La distancia de Levenshtein sería 1, puesto que podemos convertir la cadena 1 en la cadena 2 reemplazando ‘u’ con ‘a’.
Ejemplo 2:
Cadena 1 = ‘Sol’
Cadena 2 = ‘Saturno’
La distancia de Levenshtein sería 3, puesto que podemos convertir la cadena 1 en la cadena 2 a través de 3 inserciones: ‘a’, ‘t’ y ‘r’.
Coincidencia de cadenas difusas en Python:
Comparando cadenas en Python
Para comparar dos cadenas en Python, podemos ejecutar el siguiente código:
Str1 = "Back" Str2 = "Book" Result = Str1 == Str2 print(Result)
El código anterior dará un resultado como ‘Falso’ puesto que las dos cadenas no son iguales.
Distancia de Levenshtein en Python
Distancia de Levenshtein en Python usando el paquete de Python ‘Levenshtein’.
import Levenshtein as lev Str1 = "Back" Str2 = "Book" lev.distance(Str1.lower(),Str2.lower())
El código anterior dará una salida de 2, podemos convertir la cadena 1 en la cadena 2 por 2 reemplazos.
FuzzyWuzzy en Python
FuzzyWuzzy es un paquete de Python que se puede usar para la coincidencia de cadenas. Podemos ejecutar el siguiente comando para instalar el paquete:
pip install fuzzywuzzy
Del mismo modo que el paquete Levenshtein, FuzzyWuzzy cuenta con una función de vinculación que calcula la vinculación de similitud de distancia de Levenshtein estándar entre dos secuencias.
from fuzzywuzzy import fuzz Str1 = "Back" Str2 = "Book" Ratio = fuzz.ratio(Str1.lower(),Str2.lower()) print(Ratio)
La salida del siguiente código da 50, puesto que la vinculación de Levehshtein se calcula dividiendo la distancia de Levenshtein por el máximo de la longitud de la cadena 1 y la cadena 2.
Calculemos el motivo para otro conjunto de cadenas.
from fuzzywuzzy import fuzz Str1 = "My name is Ali" Str2 = "Ali is my name" Ratio = fuzz.ratio(Str1.lower(),Str2.lower()) print(Ratio)
La salida del código da 50, lo que indica que aún cuando las palabras son las mismas, el orden de las palabras importa al calcular la proporción.
Vinculación parcial usando FuzzyWuzzy
La vinculación parcial nos ayuda a realizar una coincidencia de subcadenas. Esto toma la cadena más corta y la compara con todas las subcadenas de la misma longitud.
Str1 = "My name is Ali" Str2 = "My name is Ali Abdaal" print(fuzz.partial_ratio(Str1.lower(),Str2.lower()))
La salida del código da 100 como parcial_ratio () solo verifica si alguna de las cadenas es una subcadena de la otra.
Esta vinculación podría ser muy útil si, a modo de ejemplo, estamos tratando de hacer coincidir el nombre de una persona entre dos conjuntos de datos. En el primer conjunto de datos, la cadena tiene el nombre y apellido de la persona, y en el segundo conjunto de datos, la cadena tiene el nombre, el segundo nombre y el apellido de la persona. La proporción sería 100 debido a que la primera cadena es una subcadena de la segunda cadena.
Proporción de clasificación de tokens usando FuzzyWuzzy
En la proporción de clasificación de tokens, las cadenas se tokenizan y preprocesan convirtiéndolas a minúsculas y eliminando la puntuación. Posteriormente, las cadenas se ordenan alfabéticamente y se unen. Publique esto, la vinculación de similitud de distancia de Levenshtein se calcula entre las cadenas.
Str1 = "My name is Ali" Str2 = "Ali is my name" print(fuzz.token_sort_ratio(Str1,Str2))
La salida del código da 100, puesto que la proporción de clasificación del token se encuentra después de ordenar las cadenas alfabéticamente y, por eso, el orden original de las palabras no importa.
Proporción de conjunto de tokens usando FuzzyWuzzy
La proporción de conjunto de tokens realiza una operación de conjunto que extrae los tokens comunes en lugar de simplemente tokenizar las cadenas, ordenar y después pegar los tokens nuevamente. Las palabras extra o repetidas iguales no importan.
Str1 = "My name is Ali" Str2 = "Ali is my name name" print(fuzz.token_sort_ratio(Str1,Str2)) print(fuzz.token_set_ratio(Str1,Str2))
La salida de la vinculación de clasificación de tokens llega a ser 85, mientras que la de la vinculación de conjunto de tokens llega a 100, puesto que la vinculación de conjunto de tokens no tiene en cuenta las palabras repetidas.
Ilustremos otro ejemplo de la vinculación de conjunto de tokens para una explicación más profunda.
Str_A = 'Read the sentence - My name is Ali' Str_B = 'My name is Ali' ratio = fuzz.token_set_ratio(Str_A, Str_B) print(ratio)
La salida del código anterior nos da 100. Esto se debe a que, bajo el capó, la vinculación de conjunto de tokens tiene un enfoque más flexible. Después de borrar las cadenas comunes (‘Mi nombre es Ali’), descubre la vinculación de fuzz para los siguientes pares y después devuelve el valor máximo entre los tres:
- cadena común y la cadena común con el resto de la cadena uno
- cadena común y la cadena común con el resto de la cadena dos
- cadena común con el resto de uno y cadena común con el resto de dos
Módulo de procedimiento usando FuzzyWuzzy
Si tenemos una lista de cadenas y queremos hallar la cadena coincidente más cercana de la lista con una cadena dada, podemos aprovechar el módulo ‘procedimiento’.
from fuzzywuzzy import process query = 'My name is Ali' choices = ['My name Ali', 'My name is Ali', 'My Ali'] # Get a list of matches ordered by score, default limit to 5 process.extract(query, choices)
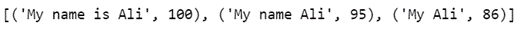
Si queremos extraer la coincidencia superior, podemos ejecutar el siguiente código:
process.extractOne(query, choices)
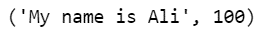
sobre el autor
Nibedita completó su maestría en Ingeniería Química de IIT Kharagpur en 2014 y hoy en día trabaja como consultora senior en AbsolutData Analytics. En su puesto actual, trabaja en la creación de soluciones sustentadas en IA / ML para clientes de una gama de industrias.
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





