Este artículo fue publicado como parte del Blogatón de ciencia de datos
Visión general
Este artículo discutirá brevemente las CNN, una variante especial de redes neuronales diseñadas específicamente para tareas relacionadas con imágenes. El artículo se centrará principalmente en la parte de implementación de CNN. Se han realizado los máximos esfuerzos para que este artículo sea interactivo y sencillo. Espero que lo disfrutes ¡¡Feliz aprendizaje !!

Introducción
Las redes neuronales convolucionales fueron introducidas por Yann LeCun y Yoshua Bengio en el año 1995 que más tarde demostró mostrar resultados excepcionales en el dominio de las imágenes. Entonces, ¿qué los hizo especiales en comparación con las redes neuronales ordinarias cuando se aplicaron en el dominio de la imagen? Explicaré una de las razones con un ejemplo sencillo. Tenga en cuenta que se le ha encomendado la tarea de clasificar las imágenes de dígitos escritos a mano y que a continuación se muestran algunos ejemplos de conjuntos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.....

Si observa correctamente, puede encontrar que todos los dígitos aparecen en el centro de las imágenes respectivas. Entrenar un modelo de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... normal con estas imágenes puede dar un buen resultado si la imagen de prueba es de un tipo similar. Pero, ¿y si la imagen de prueba es como la que se muestra a continuación?

Aquí el número nueve aparece en la esquina de la imagen. Si usamos un modelo de red neuronal simple para clasificar esta imagen, nuestro modelo puede fallar abruptamente. Pero si se le da la misma imagen de prueba a un modelo de CNN, es muy probable que se clasifique correctamente. La razón del mejor rendimiento es que busca características espaciales en la imagen. Para el caso anterior en sí, incluso si el número nueve se encuentra en la esquina izquierda del marco, el modelo de CNN entrenado captura las características en la imagen y probablemente predice que el número es el dígito nueve. Una red neuronal normal no puede hacer este tipo de magia. Ahora analicemos brevemente los principales componentes básicos de CNN.
Componentes principales de la arquitectura de un modelo CNN
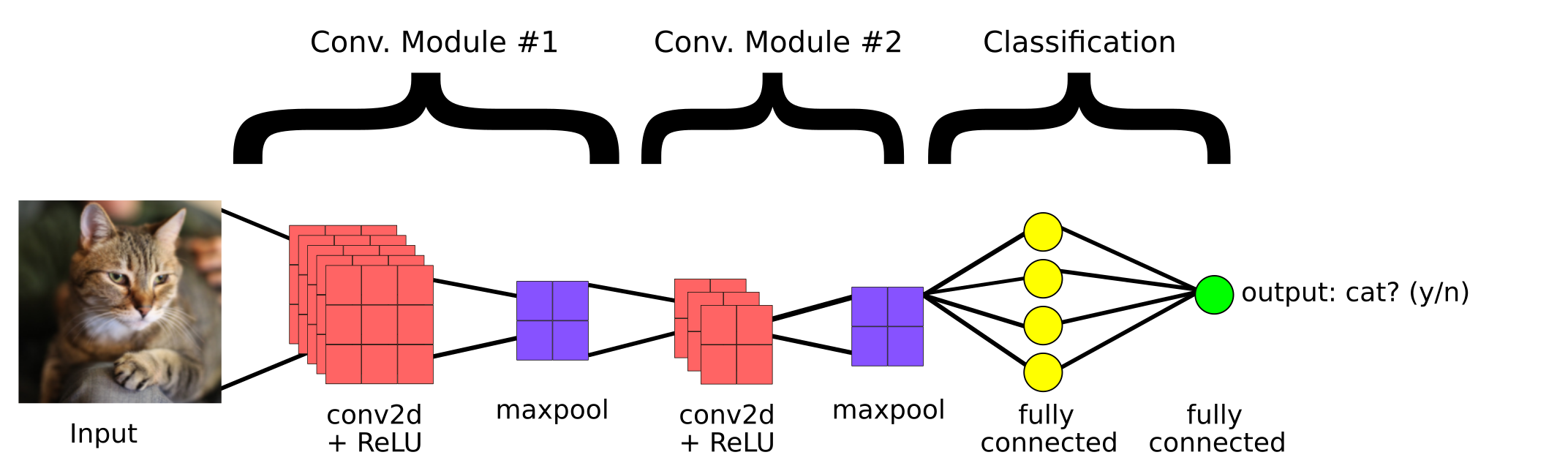
Este es un modelo de CNN simple creado para clasificar si la imagen contiene un gato o no. Entonces, los componentes principales de una CNN son:
1. Capa convolucionalLa capa convolucional, fundamental en las redes neuronales convolucionales (CNN), se utiliza principalmente para el procesamiento de datos con estructuras en forma de cuadrícula, como imágenes. Esta capa aplica filtros que extraen características relevantes, como bordes y texturas, permitiendo que el modelo reconozca patrones complejos. Su capacidad para reducir la dimensionalidad de los datos y mantener información esencial la convierte en una herramienta clave en tareas de visión por computadora...
2. Capa de agrupación
3.Capa totalmente conectada
Capa convolucional
Las capas convolucionales nos ayudan a extraer las características que están presentes en la imagen. Esta extracción se logra con la ayuda de filtros. Observe la siguiente operación.
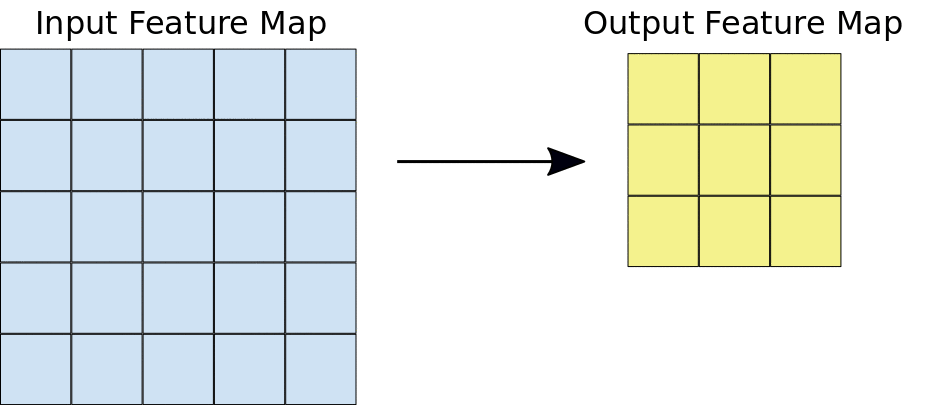
Aquí podemos ver que una ventana se desliza sobre toda la imagen donde la imagen se representa como una cuadrícula (¡Esa es la forma en que la computadora ve las imágenes donde las cuadrículas están llenas de números!). Ahora veamos cómo se realizan los cálculos en la operación de convolución.
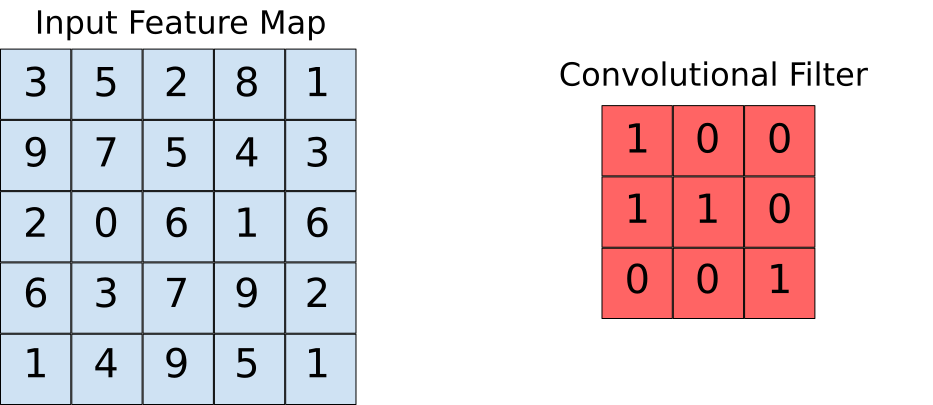
Supongamos que el mapa de características de entrada es nuestra imagen y que el filtro convolucional es la ventana sobre la que vamos a deslizarnos. Ahora observemos una de las instancias de la operación de convolución.
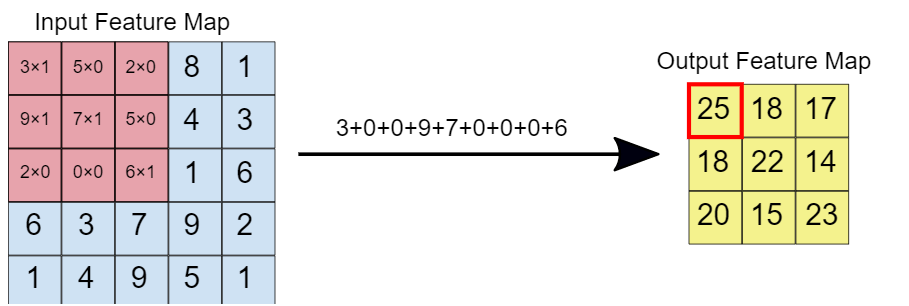
Cuando el filtro de convolución se superpone sobre la imagen, los elementos respectivos se multiplican. Luego, los valores multiplicados se suman para obtener un valor único que se completa en el mapa de características de salida. Esta operación continúa hasta que deslizamos la ventana por todo el mapa de características de entrada, llenando así el mapa de características de salida.
Capa de agrupación
La idea detrás del uso de una capa de agrupación es reducir la dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... del mapa de características. Para la representación dada a continuación, hemos utilizado una capa de agrupación máxima de 2 * 2. Cada vez que la ventana se desliza sobre la imagen, tomamos el valor máximo presente dentro de la ventana.
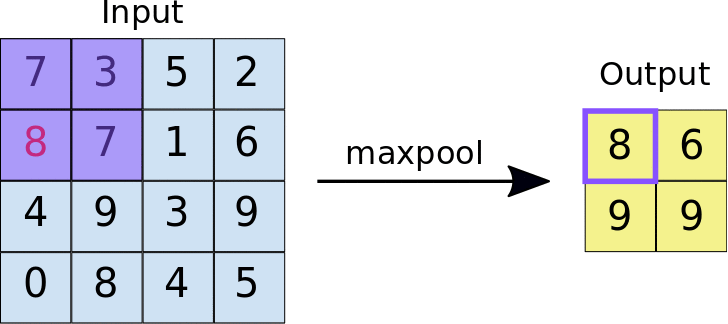
Finalmente, después de la operación de grupo máximo, podemos ver aquí que la dimensión de la entrada, es decir, 4 * 4, se ha reducido a 2 * 2.
Capa completamente conectada
Esta capa está presente en la sección de cola de la arquitectura del modelo de CNN como se vio antes. La entrada a la capa completamente conectada son las características ricas que se han extraído mediante filtros convolucionales. Esto luego se propaga hacia adelante hasta la capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados...., donde obtenemos la probabilidad de que la imagen de entrada pertenezca a diferentes clases. El resultado predicho es la clase con la probabilidad más alta que el modelo ha predicho.
Implementación de código
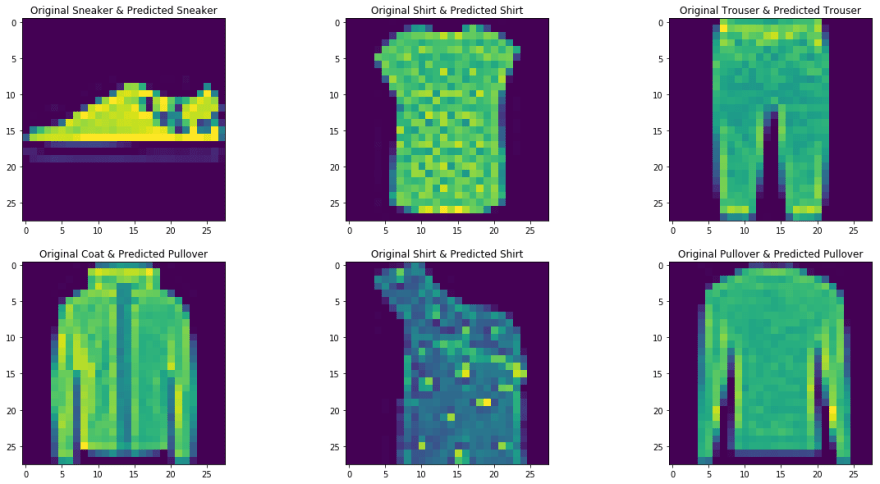
Aquí tomamos el Fashion MNIST como nuestro conjunto de datos de problemas. El conjunto de datos contiene camisetas, pantalones, pulóveres, vestidos, abrigos, sandalias, camisas, zapatillas, bolsos y botines. La tarea consiste en clasificar una imagen determinada en las clases antes mencionadas después de entrenar el modelo.
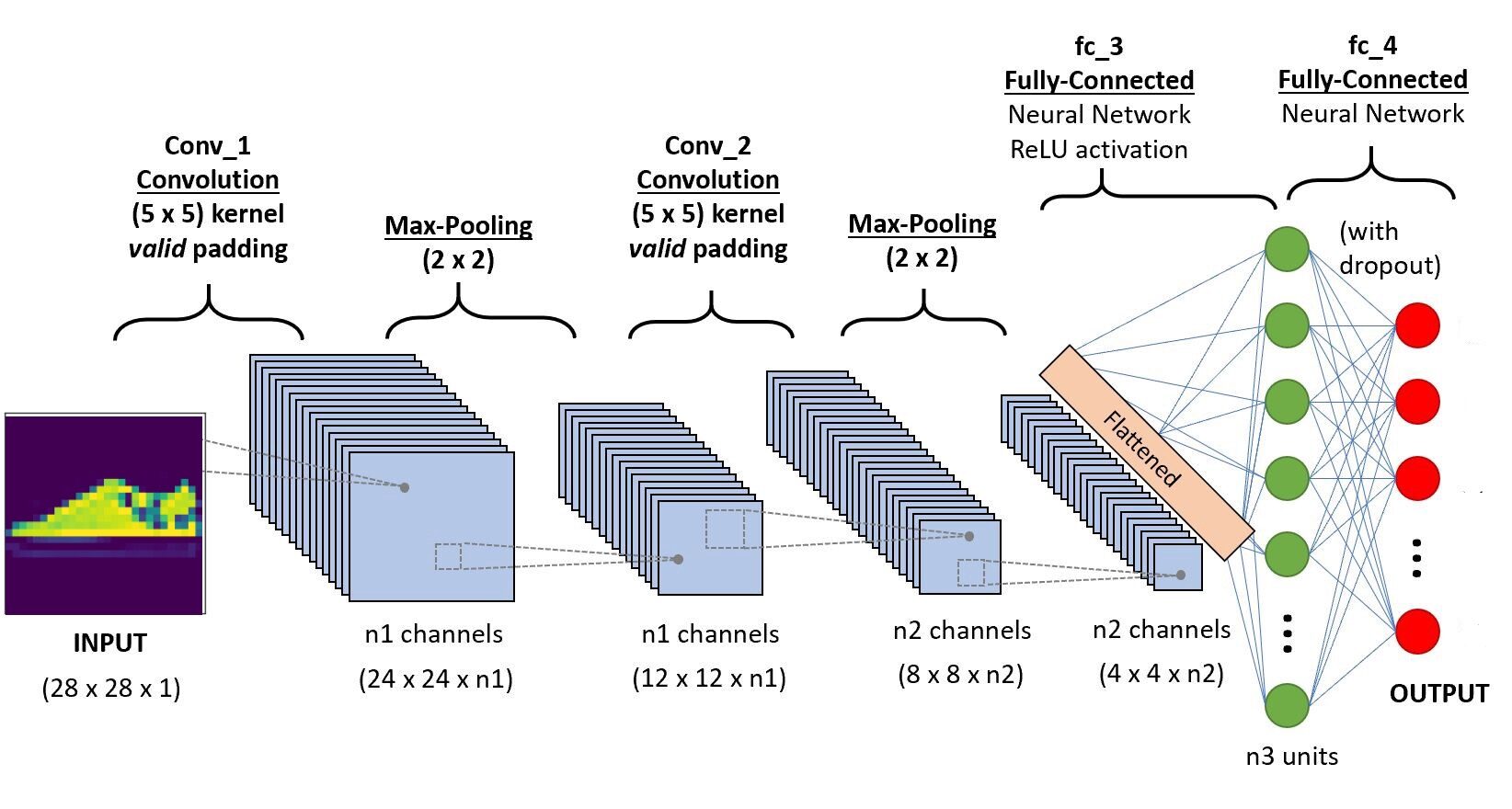
Implementaremos el código en Google Colab, ya que proporcionan el uso de recursos de GPU gratuitos durante un período de tiempo fijo. Si es nuevo en el entorno Colab y las GPU, consulte este blog para tener una mejor idea. A continuación se muestra la arquitectura de la CNN que vamos a construir.
Paso 1: Importación de las bibliotecas necesarias
import os import torch import torchvision import tarfile from torchvision import transforms from torch.utils.data import random_split from torch.utils.data.dataloader import DataLoader import torch.nn as nn from torch.nn import functional as F from itertools import chain
Paso -2: Descarga del conjunto de datos de prueba y tren
train_set = torchvision.datasets.FashionMNIST("/usr", download=True, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=True, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
Paso 3 División del conjunto de entrenamiento para entrenamiento y validación
train_size = 48000 val_size = 60000 - train_size train_ds,val_ds = random_split(train_set,[train_size,val_size])
Paso 4 Cargar el conjunto de datos en la memoria usando Dataloader
train_dl = DataLoader(train_ds,batch_size=20,shuffle=True) val_dl = DataLoader(val_ds,batch_size=20,shuffle=True) classes = train_set.classes
Ahora visualicemos los datos cargados,
for imgs,labels in train_dl:
for img in imgs:
arr_ = np.squeeze(img)
plt.show()
break
break
Paso -5 Definiendo la arquitectura
import torch.nn as nn
import torch.nn.functional as F
#define the CNN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#convolutional layer-1
self.conv1 = nn.Conv2d(1,6,5, padding=0)
#convolutional layer-2
self.conv2 = nn.Conv2d(6,10,5,padding=0)
# max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# Fully connected layer 1
self.ff1 = nn.Linear(4*4*10,56)
# Fully connected layer 2
self.ff2 = nn.Linear(56,10)
def forward(self, x):
# adding sequence of convolutional and max pooling layers
#input dim-28*28*1
x = self.conv1(x)
# After convolution operation, output dim - 24*24*6
x = self.pool(x)
# After Max pool operation output dim - 12*12*6
x = self.conv2(x)
# After convolution operation output dim - 8*8*10
x = self.pool(x)
# max pool output dim 4*4*10
x = x.view(-1,4*4*10) # Reshaping the values to a shape appropriate to the input of fully connected layer
x = F.relu(self.ff1(x)) # Applying Relu to the output of first layer
x = F.sigmoid(self.ff2(x)) # Applying sigmoid to the output of second layer
return x
# create a complete CNN model_scratch = Net() print(model)
# move tensors to GPU if CUDA is available
if use_cuda:
model_scratch.cuda()
Paso 6: definición de la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y...
# Loss function
import torch.nn as nn
import torch.optim as optim
criterion_scratch = nn.CrossEntropyLoss()
def get_optimizer_scratch(model):
optimizer = optim.SGD(model.parameters(),lr = 0.04)
return optimizer
Paso 7: implementación del algoritmo de capacitación y validación
# Implementing the training algorithm
def train(n_epochs, loaders, model, optimizer, criterion, use_cuda, save_path):
"""returns trained model"""
# initialize tracker for minimum validation loss
valid_loss_min = np.Inf
for epoch in range(1, n_epochs+1):
# initialize variables to monitor training and validation loss
train_loss = 0.0
valid_loss = 0.0
# train phase #
# setting the module to training mode
model.train()
for batch_idx, (data, target) in enumerate(loaders['train']):
# move to GPU
if use_cuda:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data.item() - train_loss))
# validate the model #
# set the model to evaluation mode
model.eval()
for batch_idx, (data, target) in enumerate(loaders['valid']):
# move to GPU
if use_cuda:
data, target = data.cuda(), target.cuda()
output = model(data)
loss = criterion(output, target)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (loss.data.item() - valid_loss))
# print training/validation statistics
print('Epoch: {} tTraining Loss: {:.6f} tValidation Loss: {:.6f}'.format(
epoch,
train_loss,
valid_loss
))
## If the valiation loss has decreased, then saving the model
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), save_path)
valid_loss_min = valid_loss
return model
Paso 8: Fase de formación y evaluación
num_epochs = 15
model_scratch = train(num_epochs, loaders_scratch, model_scratch, get_optimizer_scratch(model_scratch),
criterion_scratch, use_cuda, 'model_scratch.pt')
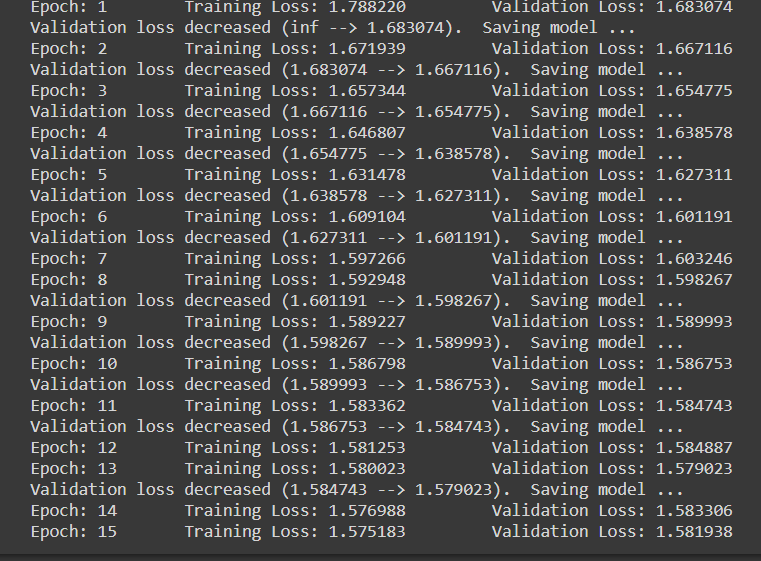
Tenga en cuenta que cuando cada vez que disminuye la pérdida de validación, estamos guardando el estado del modelo.
Paso 9 Fase de prueba
def test(loaders, model, criterion, use_cuda):
# monitor test loss and accuracy
test_loss = 0.
correct = 0.
total = 0.
# set the module to evaluation mode
model.eval()
for batch_idx, (data, target) in enumerate(loaders['test']):
# move to GPU
if use_cuda:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the loss
loss = criterion(output, target)
# update average test loss
test_loss = test_loss + ((1 / (batch_idx + 1)) * (loss.data.item() - test_loss))
# convert output probabilities to predicted class
pred = output.data.max(1, keepdim=True)[1]
# compare predictions to true label
correct += np.sum(np.squeeze(pred.eq(target.data.view_as(pred)),axis=1).cpu().numpy())
total += data.size(0)
print('Test Loss: {:.6f}n'.format(test_loss))
print('nTest Accuracy: %2d%% (%2d/%2d)' % (
100. * correct / total, correct, total))
# load the model that got the best validation accuracy
model_scratch.load_state_dict(torch.load('model_scratch.pt'))
test(loaders_scratch, model_scratch, criterion_scratch, use_cuda)

Paso 10 Prueba con una muestra
La función definida para probar el modelo con una sola imagen.
def predict_image(img, model):
# Convert to a batch of 1
xb = img.unsqueeze(0)
# Get predictions from model
yb = model(xb)
# Pick index with highest probability
_, preds = torch.max(yb, dim=1)
# printing the image
plt.imshow(img.squeeze( ))
#returning the class label related to the image
return train_set.classes[preds[0].item()]
img,label = test_set[9] predict_image(img,model_scratch)
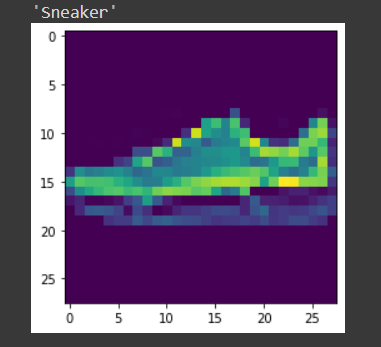
Conclusión
Aquí habíamos discutido brevemente las principales operaciones en una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... y su arquitectura. También se implementó un modelo de red neuronal convolucional simple para dar una mejor idea del caso de uso práctico. Puede encontrar el código implementado en mi Repositorio de GitHub. Además, puede mejorar el rendimiento del modelo implementado aumentando el conjunto de datos, utilizando técnicas de regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones.... como la normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... por lotes y el abandono en las capas completamente conectadas de la arquitectura. Además, tenga en cuenta que también están disponibles modelos de CNN previamente entrenados, que han sido entrenados utilizando grandes conjuntos de datos. Al utilizar estos modelos de última generación, sin duda logrará las mejores puntuaciones métricas para un problema determinado.
Referencias
- https://www.youtube.com/watch?v=EHuACSjijbI – Jovian
- https://www.youtube.com/watch?v=2-Ol7ZB0MmU&t=1503s- Una introducción amigable a las redes neuronales convolucionales y el reconocimiento de imágenes
Sobre el Autor
Mi nombre es Adwait Dathan, actualmente estoy cursando mi maestría en Inteligencia Artificial y Ciencia de Datos. Siéntete libre de conectarte conmigo a través de Linkedin.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





