Este artículo fue publicado como parte del Blogatón de ciencia de datos
Este artículo tiene como objetivo explicar la red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... y cómo compilar CNN con la biblioteca TensorFlow Keras. Este artículo discutirá los siguientes temas.
Primero analicemos la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... convolucional.
Red neuronal convolucional (CNN)
El aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... es un subconjunto muy importante del aprendizaje automático debido a su alto rendimiento en varios dominios. La red neuronal convolucional (CNN) es un poderoso tipo de aprendizaje profundo de procesamiento de imágenes que a menudo se usa en visión por computadora y que comprende un reconocimiento de imagen y video junto con un sistema de recomendación y procesamiento de lenguaje natural (NLP).
CNN utiliza un sistema multicapa que consta de la capa de entradaLa "capa de entrada" se refiere al nivel inicial en un proceso de análisis de datos o en arquitecturas de redes neuronales. Su función principal es recibir y procesar la información bruta antes de que esta sea transformada por capas posteriores. En el contexto de machine learning, una adecuada configuración de la capa de entrada es crucial para garantizar la efectividad del modelo y optimizar su rendimiento en tareas específicas...., la capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados.... y una capa oculta que comprende múltiples capas convolucionales, capas agrupadas, capas completamente conectadas. Discutiremos todas las capas en la siguiente sección del artículo mientras explicamos la construcción de CNN.
Analicemos la construcción de CNN usando la biblioteca de Keras junto con una explicación del funcionamiento de CNN.
Edificio de CNN
Usaremos el Conjunto de datos de imágenes de células de malaria. Este conjunto de datos consta de 27,558 imágenes de muestras de sangre microscópicas. El conjunto de datos consta de 2 carpetas: carpetas: parasitadas y no infectadas. Imágenes de muestra
a) muestra de sangre parasitada
b) Muestra de sangre no infectada
Discutiremos la construcción de CNN junto con CNN trabajando en los siguientes 6 pasos:
Paso 1: importar las bibliotecas necesarias
Paso 2: inicializar CNN y agregar una capa convolucionalLa capa convolucional, fundamental en las redes neuronales convolucionales (CNN), se utiliza principalmente para el procesamiento de datos con estructuras en forma de cuadrícula, como imágenes. Esta capa aplica filtros que extraen características relevantes, como bordes y texturas, permitiendo que el modelo reconozca patrones complejos. Su capacidad para reducir la dimensionalidad de los datos y mantener información esencial la convierte en una herramienta clave en tareas de visión por computadora...
Paso 3: operación de agrupación
Paso 4: agregue dos capas convolucionales
Paso 5 – Operación de aplanamiento
Paso 6: capa y capa de salida completamente conectadas
Estos 6 pasos explicarán el funcionamiento de CNN, que se muestra en la siguiente imagen:
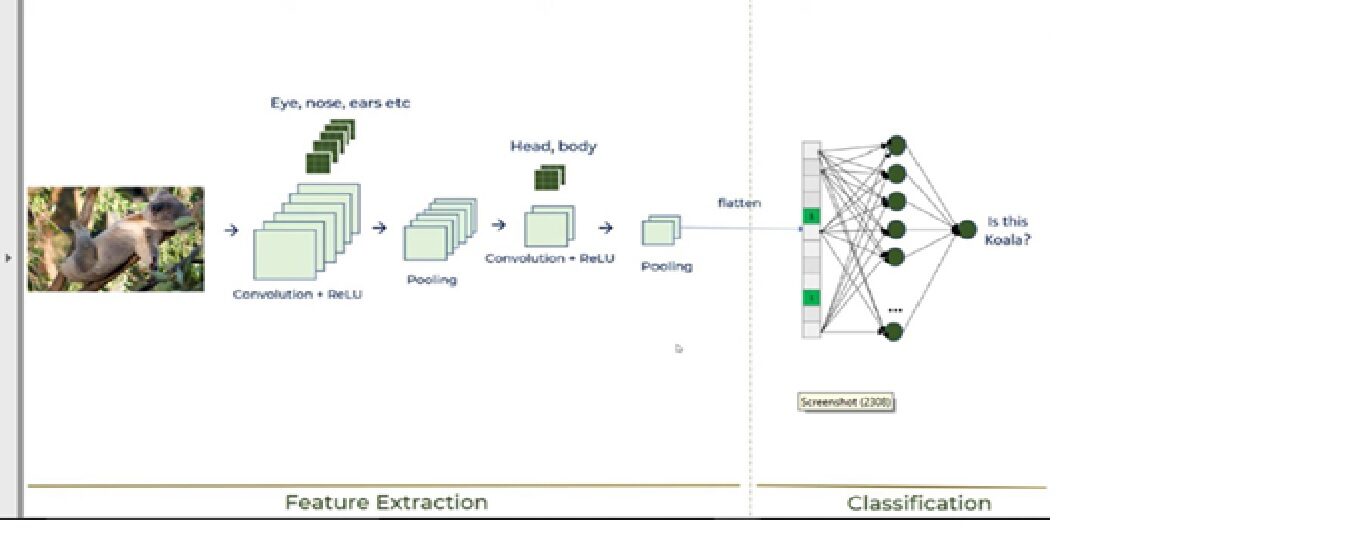
Ahora, analicemos cada paso:
1. Importar bibliotecas necesarias
Por favor, consulte el enlace a continuación para obtener explicaciones detalladas de los módulos de Keras.
https://keras.io/getting_started/
Código Python:
from tensorflow.keras.layers import Input, Lambda, Dense, Flatten,Conv2D from tensorflow.keras.models import Model from tensorflow.keras.applications.vgg19 import VGG19 from tensorflow.keras.applications.resnet50 import preprocess_input from tensorflow.keras.preprocessing import image from tensorflow.keras.preprocessing.image import ImageDataGenerator,load_img from tensorflow.keras.models import Sequential import numpy as np from glob import glob import matplotlib.pyplot as plt from tensorflow.keras.layers import MaxPooling2D
2. Inicializar CNN y agregar una capa convolucional
Código Python:
model=Sequential() model.add(Conv2D(filters=16,kernel_size=2,padding="same",activation="relu",input_shape=(224,224,3)))
Primero tenemos que iniciar la clase secuencial ya que hay varias capas para construir CNN y todas deben estar en secuencia. Luego agregamos la primera capa convolucional donde necesitamos especificar 5 argumentos. Entonces, analicemos cada argumento y su propósito.
· Filtros
El propósito principal de la convolución es encontrar características en la imagen utilizando un detector de características. Luego, colóquelos en un mapa de características, que conserva las características distintivas de las imágenes.
El detector de características, que se conoce como filtro, también se inicializa aleatoriamente y luego, después de muchas iteraciones, se selecciona el parámetro de matriz de filtro que será el mejor para separar imágenes. Por ejemplo, el ojo, la nariz, etc. de los animales se considerará una característica que se utiliza para clasificar imágenes mediante filtros o detectores de características. Aquí estamos usando 16 funciones.
· Kernel_size
Kernel_size se refiere al tamaño de la matriz del filtro. Aquí estamos usando un tamaño de filtro de 2 * 2.
· Relleno
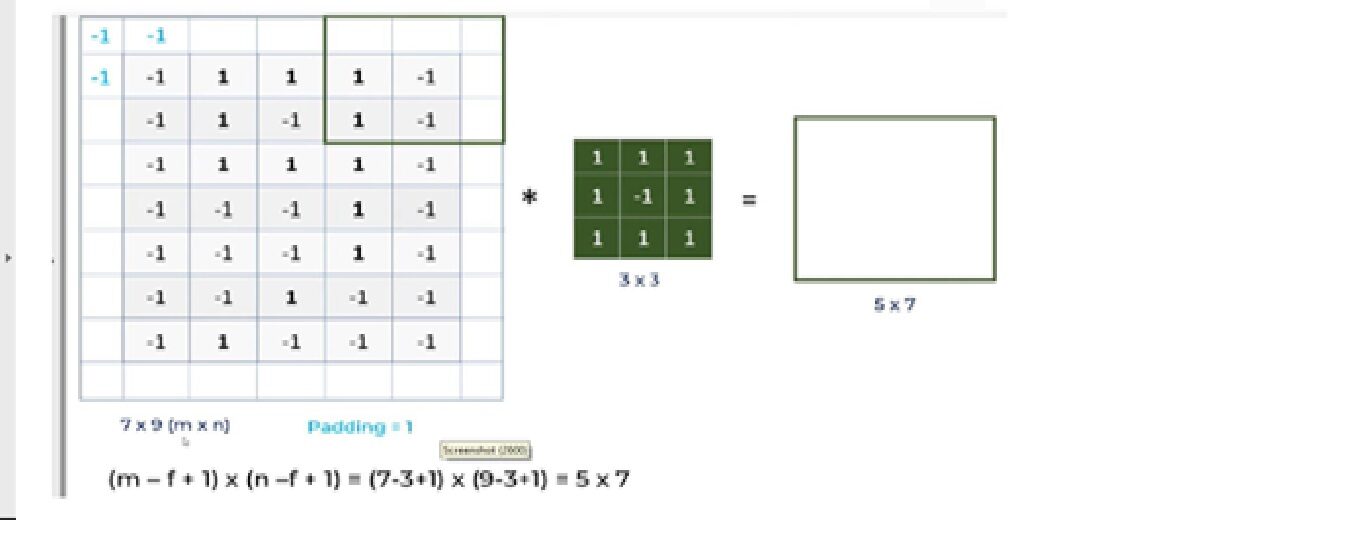
Analicemos cuál es el problema con CNN y cómo la operación de relleno resolverá el problema.
una. Para una imagen de escala de grises (nxn) y un filtro / núcleo (fxf), las dimensiones de la imagen resultante de una operación de convolución es (n – f + 1) x (n – f + 1).
Entonces, por ejemplo, una imagen de 5 * 7 y un tamaño de núcleo de filtro de 3 * 3, el resultado de salida después de la operación de convolución sería un tamaño de 3 * 5. Por lo tanto, la imagen se encoge cada vez que se realiza la operación convolucional.
B. Los píxeles, ubicados en las esquinas, tienen una contribución muy pequeña en comparación con los píxeles del medio.
Entonces, para mitigar estos problemas, se realiza la operación de relleno. El relleno es un proceso simple de agregar capas con 0 o -1 a las imágenes de entrada para evitar los problemas mencionados anteriormente.
Aquí estamos usando Padding = Same argumentos, que describe que las imágenes de salida tienen las mismas dimensiones que las imágenes de entrada.
· Función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.... – ReluLa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción...
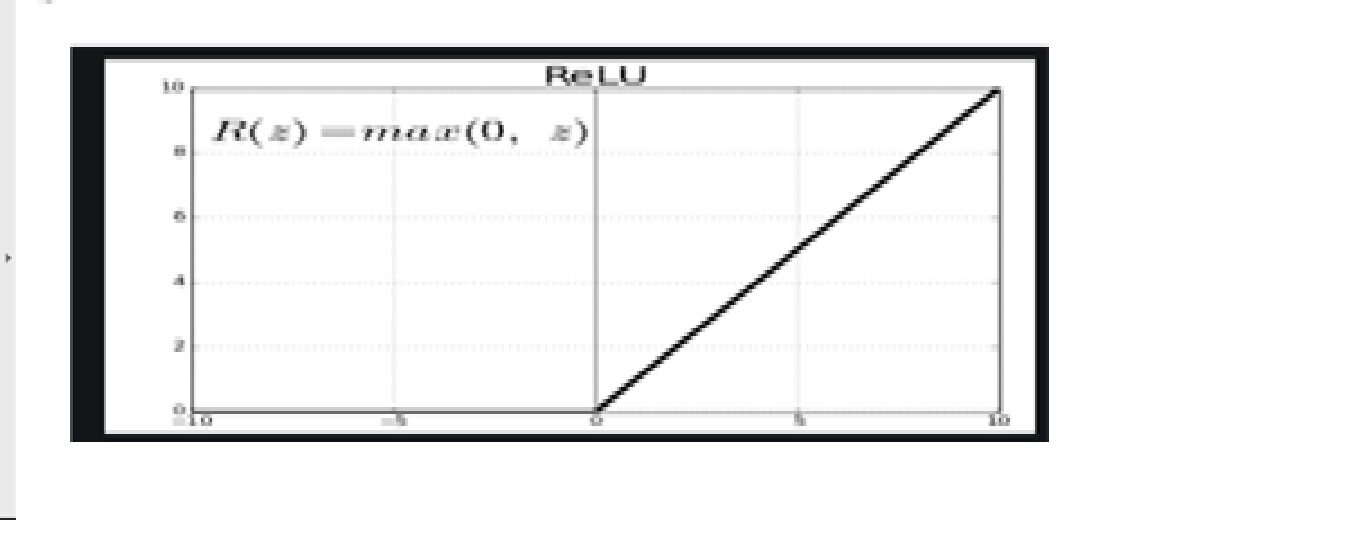
Dado que las imágenes no son lineales, para aportar no linealidad, la función de activación reluLa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Se define como ( f(x) = max(0, x) ), lo que significa que produce una salida de cero para valores negativos y un incremento lineal para valores positivos. Su capacidad para mitigar el problema del desvanecimiento del gradiente la convierte en una opción preferida en arquitecturas profundas.... se aplica después de la operación convolucional.
Relu significa función de activación lineal rectificada. La función Relu generará la entrada directamente si es positiva; de lo contrario, generará cero.
· Forma de entrada
Este argumento muestra el tamaño de la imagen: 224 * 224 * 3. Dado que las imágenes en formato RGB son así, la tercera dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... de la imagen es 3.
3. Operación de agrupación
Código Python:
model.add(MaxPooling2D(pool_size=2))
Necesitamos aplicar la operación de agrupación después de inicializar CNN. La agrupación es una operación de muestreo descendente de la imagen. La capa de agrupación se utiliza para reducir las dimensiones de los mapas de características. Por lo tanto, la capa Pooling reduce la cantidad de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... a aprender y reduce el cálculo en la red neuronal.
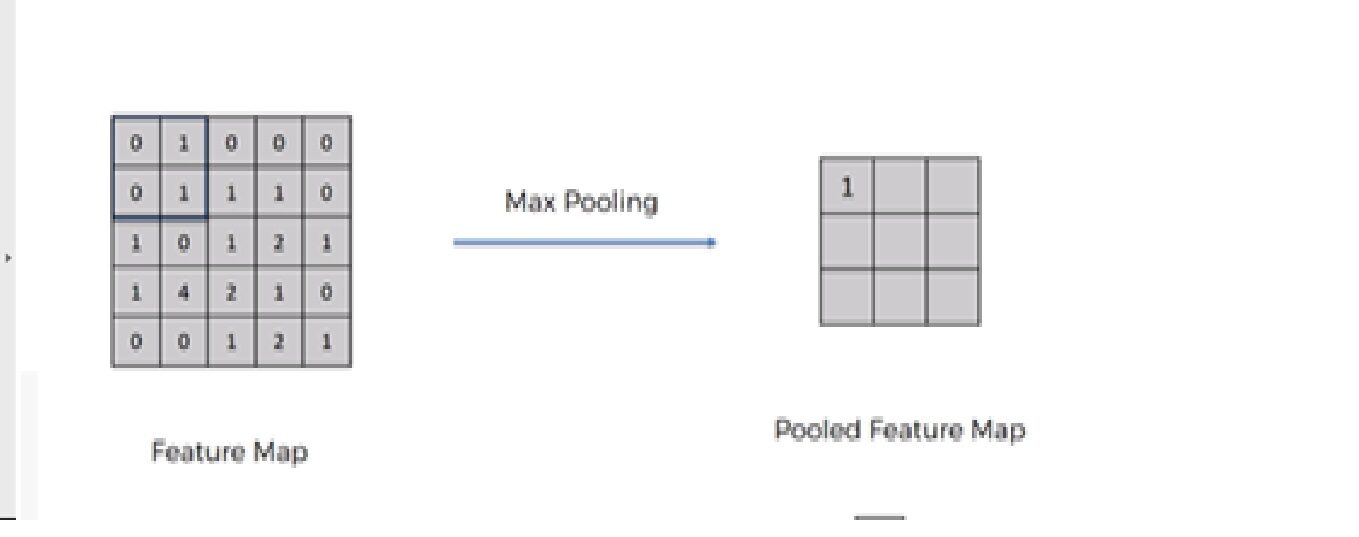
Las operaciones futuras se realizan en entidades resumidas creadas por la capa de agrupación. en lugar de características ubicadas con precisión generadas por la capa de convolución. Esto lleva al modelo más robusto a las variaciones en la orientación de la característica en la imagen.
Hay principalmente 3 tipos de agrupación: –
1. Agrupación máxima
2. Agrupación promedio
3. Agrupación global
4. Agregue dos capas convolucionales
Para agregar dos capas convolucionales más, necesitamos repetir los pasos 2 y 3 con una ligera modificación en el número de filtros.
Código Python:
model.add(Conv2D(filters=32,kernel_size=2,padding="same",activation ="relu")) model.add(MaxPooling2D(pool_size=2)) model.add(Conv2D(filters=64,kernel_size=2,padding="same",activation="relu")) model.add(MaxPooling2D(pool_size=2))
Modificamos el 2Dakota del Norte y 3rd capas convolucionales con número de filtro 32 y 64 respectivamente.
5. Operación de aplanamiento
Código Python:
model.add(Flatten())
La operación de aplanamiento es convertir el conjunto de datos en una matriz 1-D para ingresar en la siguiente capa, que es la capa completamente conectada.
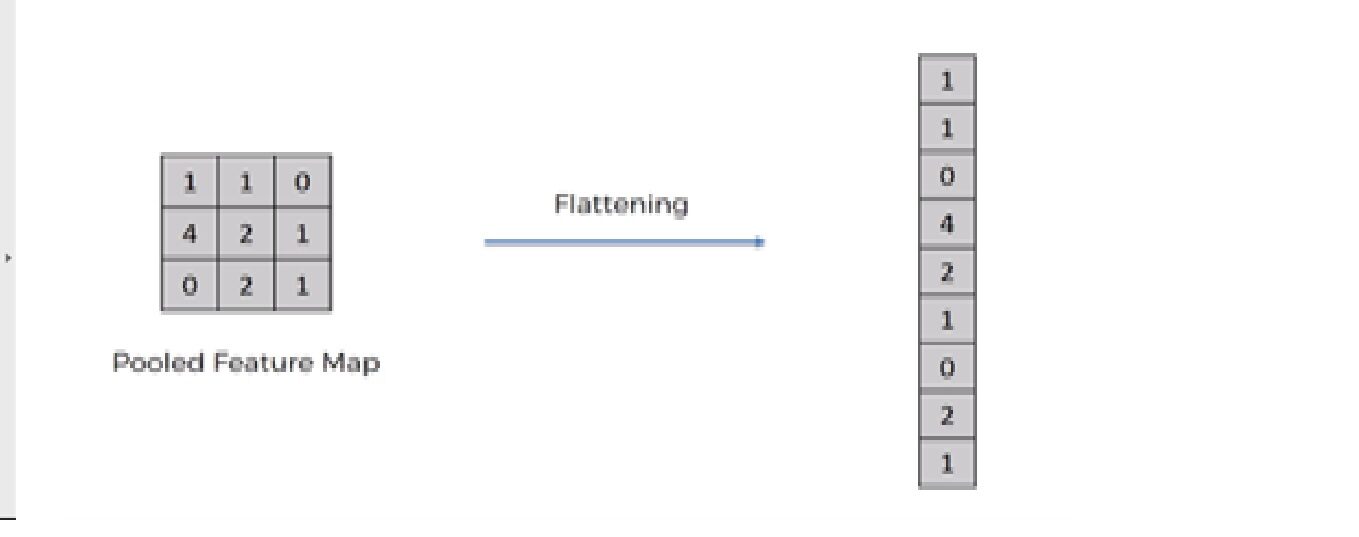
Después de terminar los 3 pasos, ahora hemos agrupado el mapa de características. Ahora estamos aplanando nuestra salida después de dos pasos en una columna. Porque necesitamos insertar estos datos 1-D en una capa de red neuronal artificial.
6. Capa completamente conectada y capa de salida
La salida de la operación de aplanamiento funciona como entrada para la red neuronal. El objetivo de la red neuronal artificial hace que la red neuronal convolucional sea más avanzada y lo suficientemente capaz de clasificar imágenes.
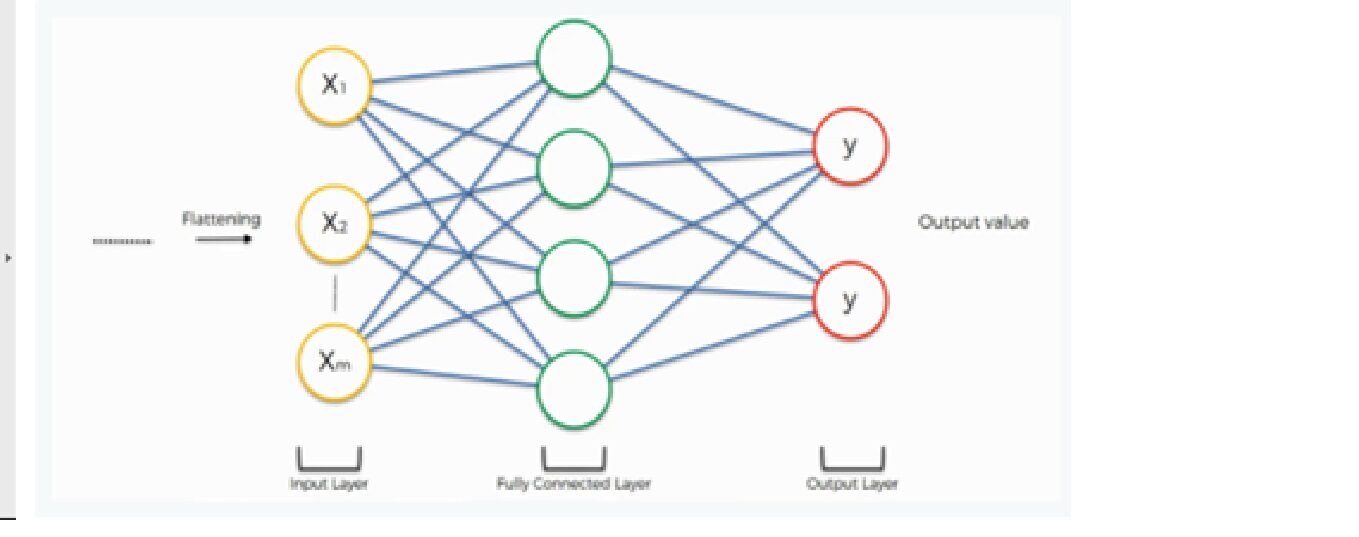
Aquí estamos usando una clase densa de la biblioteca de Keras para crear una capa completamente conectada y una capa de salida.
Código Python:
model.add(Dense(500,activation="relu")) model.add(Dense(2,activation="softmax"))
La función de activación de softMax se utiliza para construir la capa de salida. Analicemos la función de activación de softmax.
Función de activación Softmax
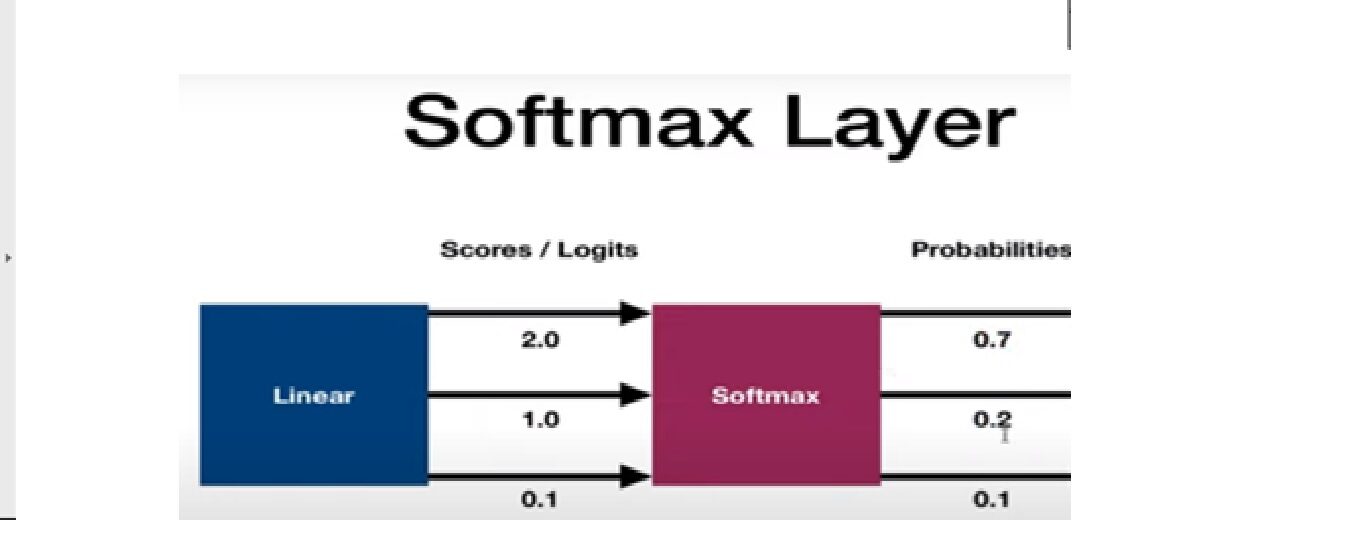
Se utiliza como la última función de activación de una red neuronal para llevar la salida de la red neuronal a una distribución de probabilidad sobre las clases de predicción. La salida de Softmax está en probabilidades de cada resultado posible para predecir la clase. La suma de probabilidades debe ser una para todas las clases de predicción posibles.
Ahora, analicemos el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y la evaluación de la red neuronal convolucional. Discutiremos esta sección en 3 pasos; –
Paso 1: compila el modelo de CNN
Paso 2: ajuste el modelo en el conjunto de entrenamiento
Paso 3: evaluar el resultado
Paso 1: compilar el modelo de CNN
Línea de código
model.compile (loss = ‘categorical_crossentropy’, optimizer = ‘adam’, metrics =[‘accuracy’])
Aquí estamos usando 3 argumentos: –
· Función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y...
Estamos usando el categorical_crossentropy función de pérdida que se utiliza en la tarea de clasificación. Esta pérdida es una muy buena medida de cuán distinguibles son dos distribuciones de probabilidad discretas entre sí.
Por favor, consulte el enlace a continuación para obtener una descripción detallada de los diferentes tipos de función de pérdida:
· Optimizador
Estamos usando Adam Optimizarr que se utiliza para actualizar los pesos de las redes neuronales y la tasa de aprendizaje. Los optimizadores se utilizan para resolver problemas de optimización minimizando la función.
Por favor, consulte el enlace a continuación para obtener una explicación detallada de los diferentes tipos de optimizador:
· Argumentos de métricas
Aquí, estamos utilizando la precisión como métrica para evaluar el rendimiento del algoritmo de red neuronal convolucional.
Paso 2: ajuste del modelo en el conjunto de entrenamiento
Línea de código:
model.fit_generator(training_set,validation_data=test_set,epochs=50, steps_per_epoch=len(training_set), validation_steps=len(test_set) )
Estamos ajustando el modelo CNN en el conjunto de datos de entrenamiento con 50 iteraciones y cada iteración tiene diferentes pasos para entrenar y evaluar pasos según la duración del conjunto de prueba y entrenamiento.
Paso 3: – Evaluar el resultado
Comparamos la función de precisión y pérdida para el conjunto de datos de entrenamiento y prueba.
Código: Trazado de gráfico de pérdidas
plt.plot(r.history['loss'], label="train loss")
plt.plot(r.history['val_loss'], label="val loss")
plt.legend()
plt.show()
plt.savefig('LossVal_loss')
Producción
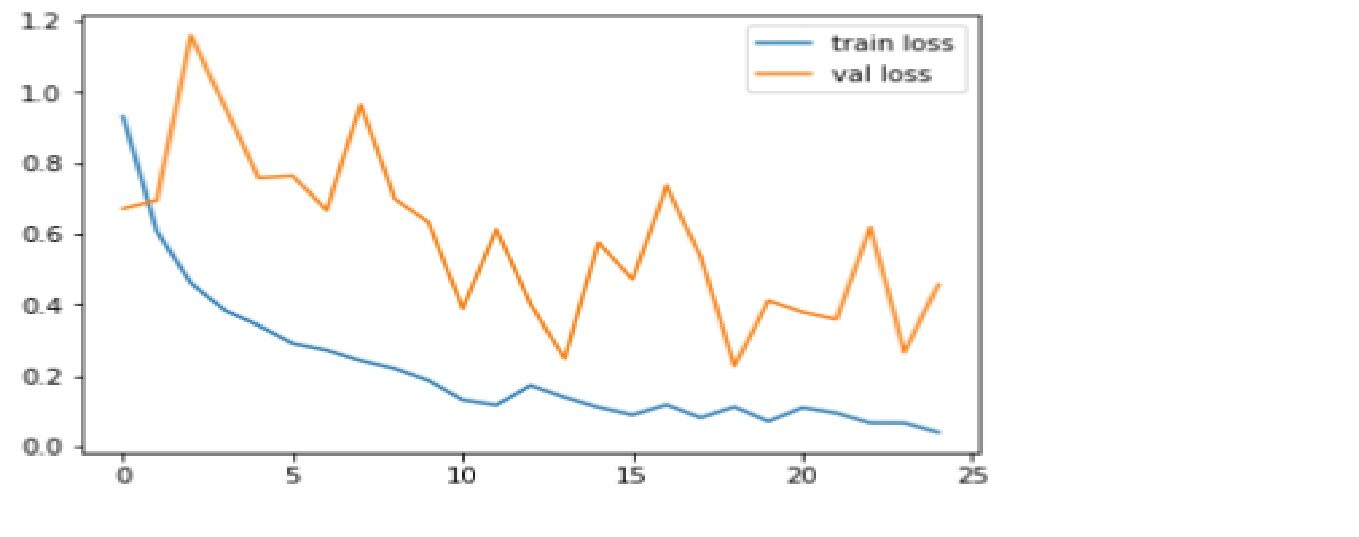
La pérdida es el castigo por una mala predicción. El objetivo es hacer que la pérdida de validación sea lo más baja posible. Un poco de sobreajuste es casi siempre algo bueno. Todo lo que importa, al final, es: es la pérdida de validación lo más baja posible.
Código: Gráfico de precisión de trazado
plt.plot(r.history['accuracy'], label="train acc")
plt.plot(r.history['val_accuracy'], label="val acc")
plt.legend()
plt.show()
plt.savefig('AccVal_acc')
Producción
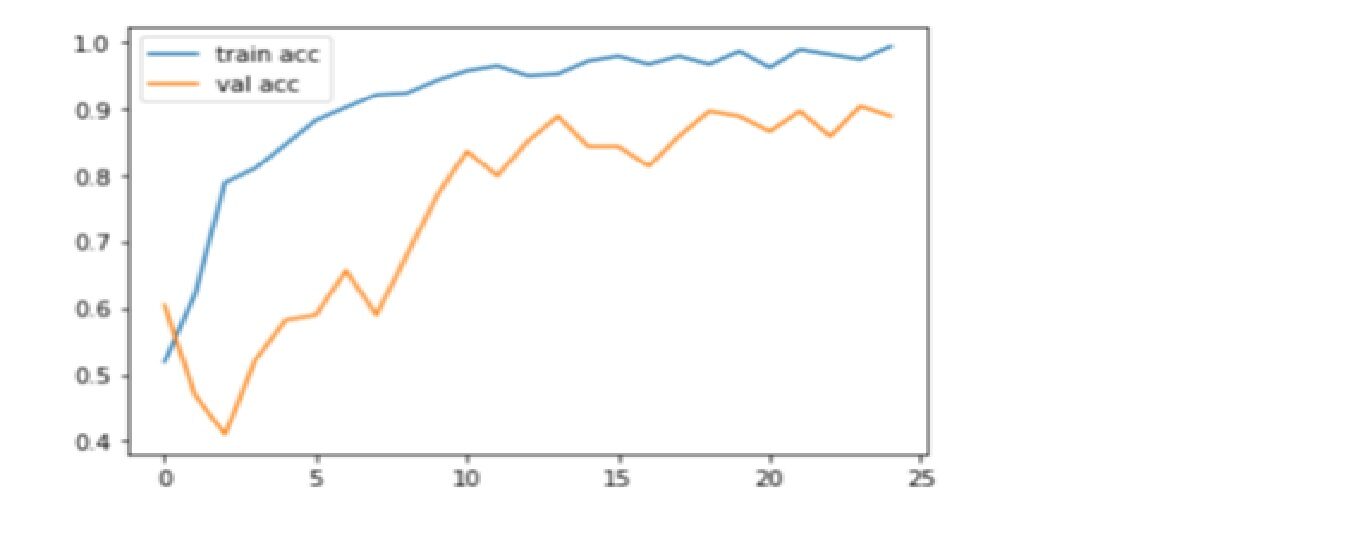
La precisión es una métrica para evaluar modelos de clasificación. De manera informal, la precisión es la fracción de predicciones que nuestro modelo acertó. Aquí, podemos observar que la precisión se acerca al 90% en la prueba de validación que muestra que un modelo de CNN está funcionando bien en las métricas de precisión.
¡Gracias por leer! ¡Feliz aprendizaje profundo!
Referencias:
1. https://www.superdatascience.com/
2. https://www.youtube.com/watch?v=H-bcnHE6Mes
Sobre mí :
Soy Jitendra Sharma, practicante de ciencia de datos en Nabler, y me dedico a PGDM-Big Data Analytics del Goa Institute of Management. Puedes contactarme a través de LinkedIn y Github.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





