«La predicción es muy difícil, especialmente si se trata del futuro».
alguna idea después de leer la hermosa cita anterior. He explicado diferentes bibliotecas automatizadas para automatizar el aprendizaje automático y la tarea de PNL en mis artículos anteriores. De manera similar, en este artículo, explicaré “Cómo automatizar la predicción de series temporales usando Auto-TS”.
Auto-TS es parte de AutoML que automatizará algunos de los componentes del proceso de aprendizaje automático. Esto automatiza las bibliotecas y ayuda a los no expertos a entrenar un modelo básico de aprendizaje automático sin tener mucho conocimiento en el campo. Aquí En este artículo, discutiré cómo automatizar la implementación de un modelo de pronóstico de series de tiempo usando la biblioteca Auto-TS.
¿Qué es Auto-TS?
Es una biblioteca de Python de código abierto que se utiliza básicamente para automatizar el pronóstico de series temporales. Entrenará automáticamente varios modelos de series de tiempo utilizando una sola línea de código, lo que nos ayudará a elegir el mejor para nuestro planteamiento del problema.
En la biblioteca de código abierto de Python, Auto-TS, auto-ts.Auto_TimeSeries () es la función principal a la que llamará con los datos de su tren. Luego, podemos elegir qué tipo de modelos desea, como modelos basados en estadísticas, ml o FB. También podemos ajustar los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... que seleccionarán automáticamente el mejor modelo en función del parámetro de puntuación en el que queremos que se base. Devolverá el mejor modelo y un diccionario que contiene predicciones para el número de Forecast_periods que mencionó (predeterminado = 2).
Características de la biblioteca Auto-TS:
- Encuentra el modelo óptimo de predicción de series de tiempo mediante la optimización de la programación genética.
- Entrena modelos ingenuos, estadísticos, de aprendizaje automático y de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud..., con todas las configuraciones de hiperparámetros posibles y validación cruzada.
- Realiza transformaciones de datos para manejar datos desordenados aprendiendo la imputación óptima de NaN y la eliminación de valores atípicos.
- Elección de la combinación de métricas para la selección del modelo.
Instalación:
pip install autots OR pip3 install auto-ts OR pip install git+git://github.com/AutoViML/Auto_TS
Requerimientos:
dask scikit-learn FB Prophet statsmodels pmdarima XGBoost
Importar biblioteca usando:
from auto_ts import auto_timeseries
Parámetros disponibles en auto_timeseries:
model = auto_timeseries( score_type="rmse", time_interval="Month", non_seasonal_pdq=None, seasonality=False, seasonal_period=12, model_type=['Prophet'], verbose=2)
Puede ajustar los parámetros y analizar el cambio en el rendimiento del modelo. Para obtener más detalles sobre los parámetros, haga clic en aquí.
Conjunto de datos utilizado:
Aquí he usado el Precio de las acciones de Amazon conjunto de datos de enero de 2006 a enero de 2018, que se descarga de Kaggle. Esta biblioteca solo ofrece modelos de predicción de series de tiempo de trenes. El conjunto de datos debe tener una columna de formato de fecha o hora.
Inicialmente, cargue el conjunto de datos de la serie temporalUna serie temporal es un conjunto de datos recogidos o medidos en momentos sucesivos, generalmente en intervalos de tiempo regulares. Este tipo de análisis permite identificar patrones, tendencias y ciclos en los datos a lo largo del tiempo. Su aplicación es amplia, abarcando áreas como la economía, la meteorología y la salud pública, facilitando la predicción y la toma de decisiones basadas en información histórica.... con una columna de fecha y hora:
df = pd.read_csv("Amazon_Stock_Price.csv", usecols=['Date', 'Close'])
df['Date'] = pd.to_datetime(df['Date'])
df = df.sort_values('Date')
Ahora, divida todos los datos en datos de prueba y de tren:
train_df = df.iloc[:2800] test_df = df.iloc[2800:]
Ahora, visualizaremos la división de prueba del tren:
train_df.Close.plot(figsize=(15,8), title="AMZN Stock Price", fontsize=14, label="Train") test_df.Close.plot(figsize=(15,8), title="AMZN Stock Price", fontsize=14, label="Test") plt.legend() plt.grid() plt.show()
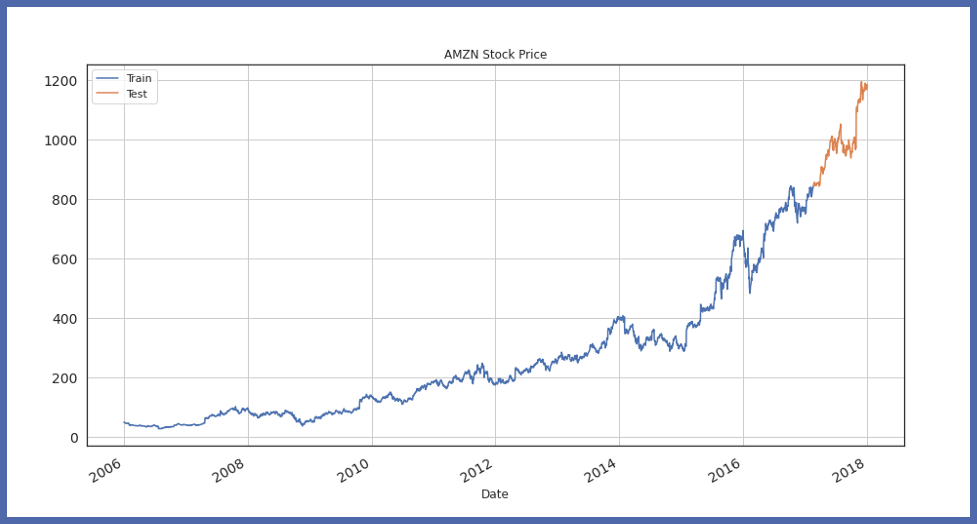
Ahora, inicialicemos el objeto del modelo Auto-TS y ajustemos los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....:
model = auto_timeseries(forecast_period=219, score_type="rmse", time_interval="D", model_type="best") model.fit(traindata= train_df, ts_column="Date", target="Close")
Ahora comparemos la precisión de diferentes modelos:
model.get_leaderboard() model.plot_cv_scores()
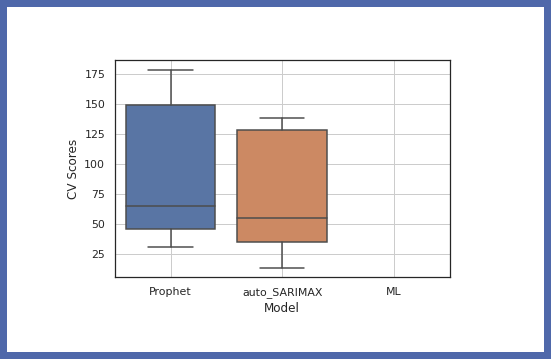
Ahora probemos nuestro modelo con datos de prueba:
future_predictions = model.predict(testdata=219)
Finalmente, visualice el valor y la predicción de los datos de prueba:
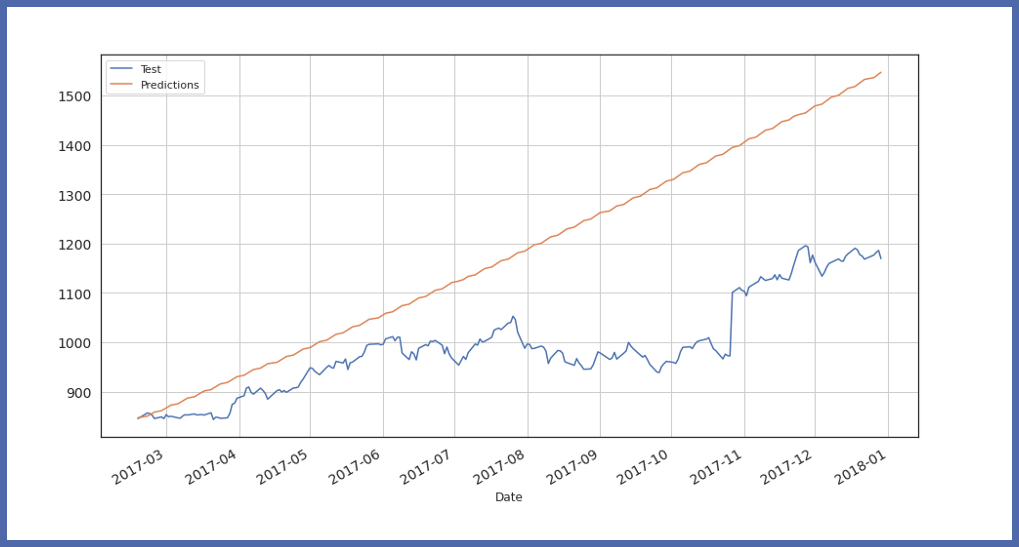
Parámetros disponibles en auto_timeseries:
model = auto_timeseries( score_type="rmse", time_interval="Month", non_seasonal_pdq=None, seasonality=False, seasonal_period=12, model_type=['Prophet'], verbose=2)
Parámetros disponibles en model.fit ():
model.fit( traindata=train_data, ts_column=ts_column, target=target, cv=5, sep="," )
Parámetros disponibles en model.predict ():
predictions = model.predict( testdata = can be either a dataframe or an integer standing for the forecast_period, model="best" or any other string that stands for the trained model )
Puede jugar con todos estos parámetros y analizar el rendimiento de nuestro modelo y luego puede seleccionar el modelo más adecuado para el planteamiento de su problema. Puede comprobar todos estos parámetros en detalle haciendo clic en aquí.
Conclusión:
En este artículo, he discutido cómo se puede automatizar el modelo de series de tiempo en una línea de código Python. Auto-TS realiza el preprocesamiento de datos, ya que elimina los valores atípicos de los datos y maneja datos desordenados al aprender la imputación óptima de NaN. Utilizando solo una línea de código, inicializando el objeto Auto-TS y ajustando los datos del tren, entrenará automáticamente múltiples modelos de series temporales como ARIMA, SARIMAX, FB Prophet, VAR, y generará el modelo de mejor rendimiento que es adecuado para nuestra declaración de problema. El resultado del modelo parece depender del tamaño del conjunto de datos. Si intentamos aumentar el tamaño del conjunto de datos, el resultado definitivamente puede mejorar.
EndNote
Espero que hayas disfrutado de este artículo. ¿Cualquier pregunta? ¿Me he perdido algo? Por favor, comuníquese con mi LinkedIn O deja un comentario abajo. Y finalmente, … no hace falta decir,
¡Gracias por leer!
¡¡Salud!!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





