Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Red neuronal recurrenteLas redes neuronales recurrentes (RNN) son un tipo de arquitectura de redes neuronales diseñadas para procesar secuencias de datos. A diferencia de las redes neuronales tradicionales, las RNN utilizan conexiones internas que permiten recordar información de entradas anteriores. Esto las hace especialmente útiles en tareas como el procesamiento de lenguaje natural, la traducción automática y el análisis de series temporales, donde el contexto y la secuencia son fundamentales para la... (RNN) fue uno de los mejores conceptos introducidos que podría hacer uso de elementos de memoria en nuestra red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas.... Antes de eso, teníamos una red neuronal que podía realizar la propagación hacia adelante y hacia atrás para actualizar los pesos y reducir los errores en la red. Pero, como sabemos, muchos problemas en el mundo real son de naturaleza temporal y dependen mucho del tiempo.
Muchas aplicaciones de idiomas son siempre secuenciales y la siguiente palabra en una oración depende de la anterior. Estos problemas se resolvieron mediante un simple RNN. Pero si entendemos a RNN, apreciamos el hecho de que incluso RNN no puede ayudarnos cuando queremos hacer un seguimiento de las palabras que se usaron anteriormente en nuestra oración. En este artículo, discutiré algunos de los principales inconvenientes de RNN y por qué usamos un modelo mejor para la mayoría de las aplicaciones basadas en lenguaje.
Comprensión de la retropropagación a través del tiempo (BPTT)
RNN utiliza una técnica llamada BackpropagationLa retropropagación es un algoritmo fundamental en el entrenamiento de redes neuronales artificiales. Se basa en el principio del descenso del gradiente, permitiendo ajustar los pesos de la red para minimizar el error en las predicciones. A través de la propagación del error desde la capa de salida hacia las capas anteriores, este método optimiza el aprendizaje de la red, mejorando su capacidad para generalizar en datos no vistos.... a través del tiempo para retropropagar a través de la red para ajustar sus pesos para que podamos reducir el error en la red. Recibió su nombre «a través del tiempo», ya que en RNN tratamos con datos secuenciales y cada vez que retrocedemos es como retroceder en el tiempo hacia el pasado. Aquí está el funcionamiento de BPTT:
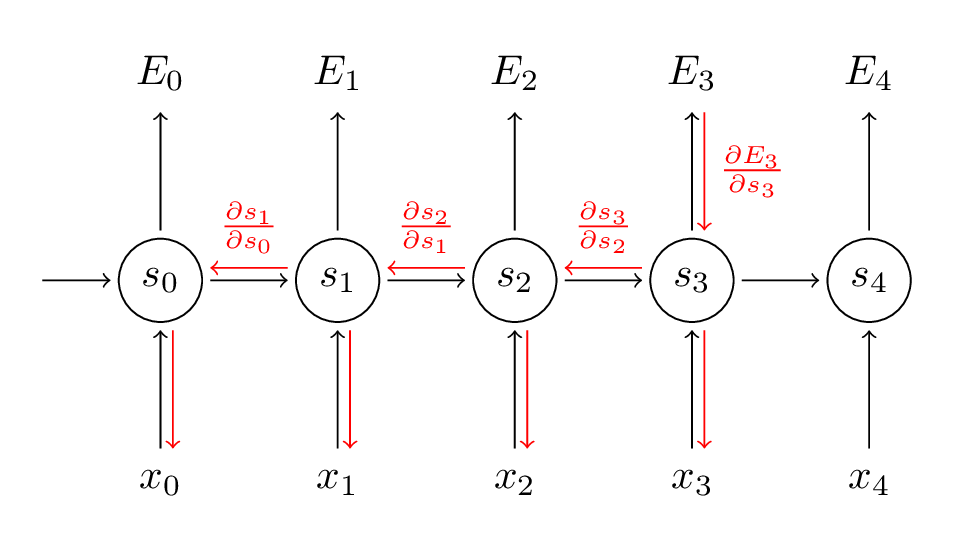
Fuente: (http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/)
En el paso BPTT, calculamos la derivada parcial en cada peso en la red. Entonces, si estamos en el tiempo t = 3, entonces consideramos la derivada de E3 con respecto a la de S3. Ahora, x3 también está conectado a s3. Entonces, también se considera su derivada. Ahora, si vemos que s3 está conectado a s2, entonces s3 depende del valor de s2 y aquí también se considera la derivada de s3 con respecto a s2. Esto actúa como una regla de la cadena y acumulamos toda la dependencia con sus derivadas y la usamos para el cálculo del error.
En E3 tenemos un gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... que es de S3 y su ecuación en ese momento es:
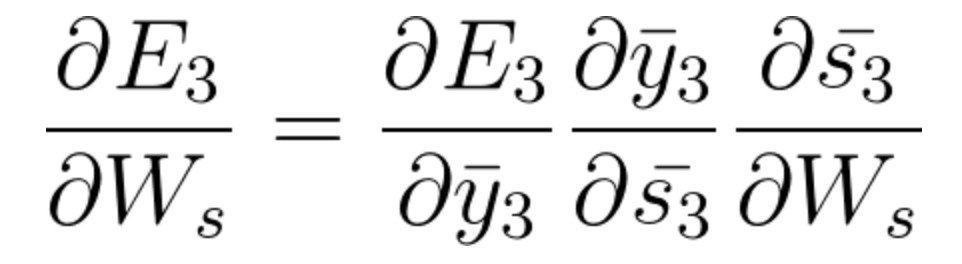
Ahora también tenemos s2 asociado con s3 entonces,
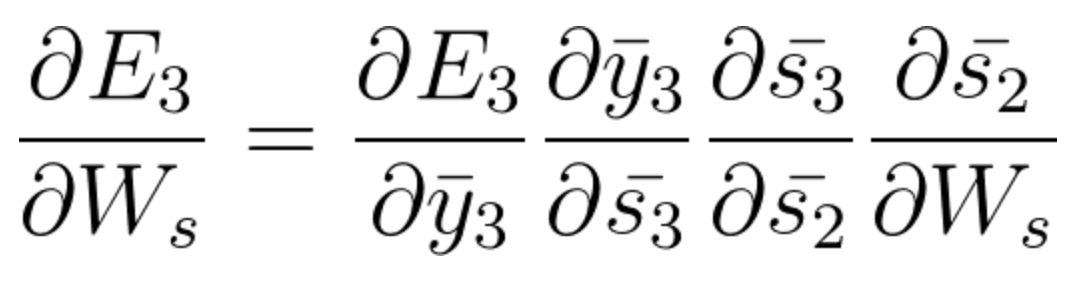
Y s1 también está asociado con s2 y, por lo tanto, ahora todo s1, s2, s3 y tiene un efecto en E3,
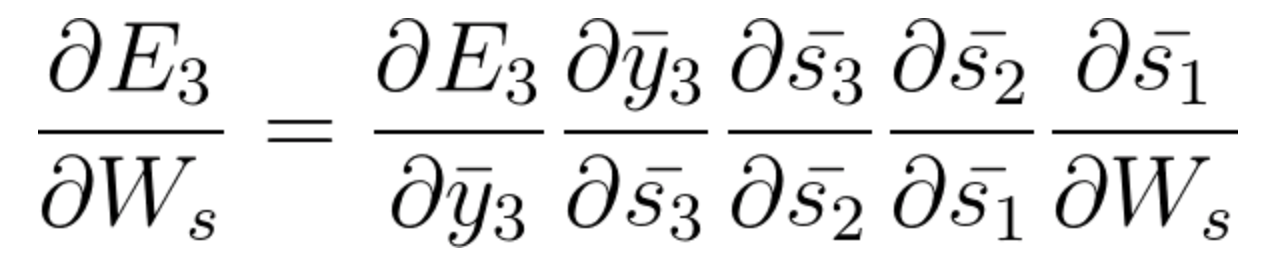
Al acumular todo terminamos obteniendo la siguiente ecuación que ha aportado Ws hacia esa red en el tiempo t = 3,
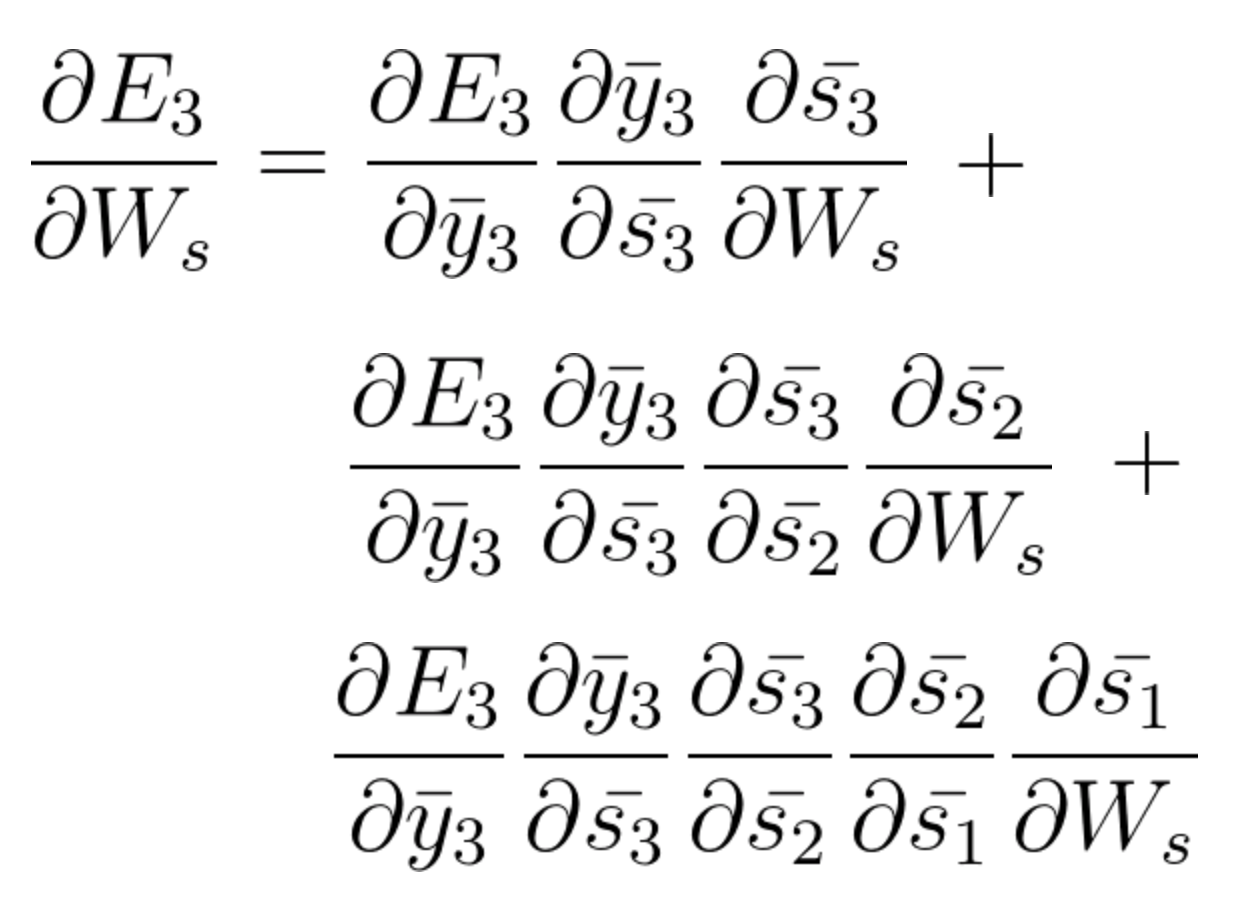
La ecuación general para la que ajustamos Ws en nuestra red BPTT se puede escribir como,
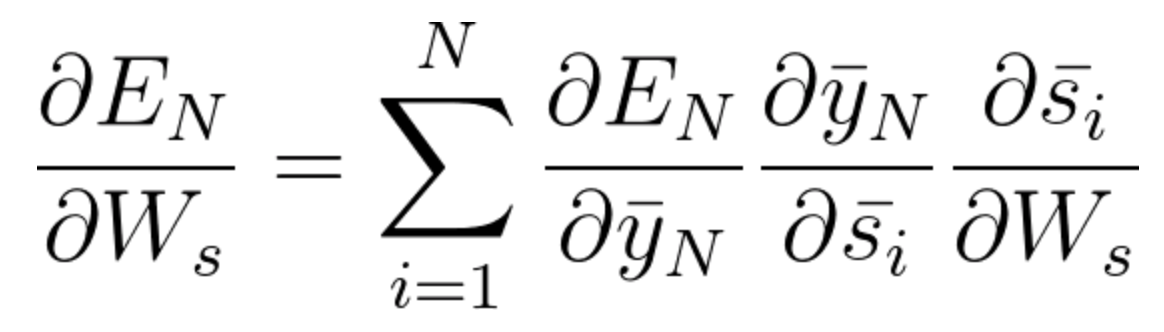
Ahora, como hemos notado, Wx también está asociado con la red. Entonces, al hacer lo mismo, generalmente podemos escribir,
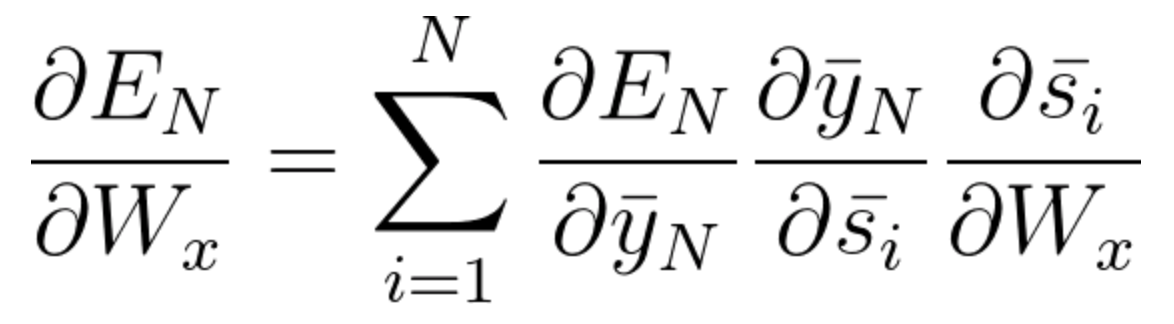
Ahora que ha entendido cómo funciona BPTT, básicamente se trata de cómo RNN ajusta sus pesos y reduce el error. Ahora, la falla principal aquí es que esto es básicamente solo para una red pequeña con 4 capas. Pero imagínese si tuviéramos cientos de capas y, a la vez, digamos t = 100, terminaríamos calculando todas las derivadas parciales asociadas con la red y esta es una multiplicación enorme y esto puede reducir el valor general a un valor muy pequeño o valor minuto tal que puede resultar inútil corregir el error. Este problema se llama Problema de gradiente que desaparece.
Problema de gradiente que desaparece
Como todos sabemos, en RNN para predecir una salida usaremos una función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.... sigmoidea para que podamos obtener la salida de probabilidad para una clase en particular. Como vimos en la sección anterior cuando se trata de decir E3, existe una dependencia a largo plazo. El problema ocurre cuando tomamos la derivada y la derivada del sigmoide siempre está por debajo de 0.25 y, por lo tanto, cuando multiplicamos muchas derivadas juntas de acuerdo con la regla de la cadena, terminamos con un valor de fuga tal que no podemos usarlos para el cálculo del error. .
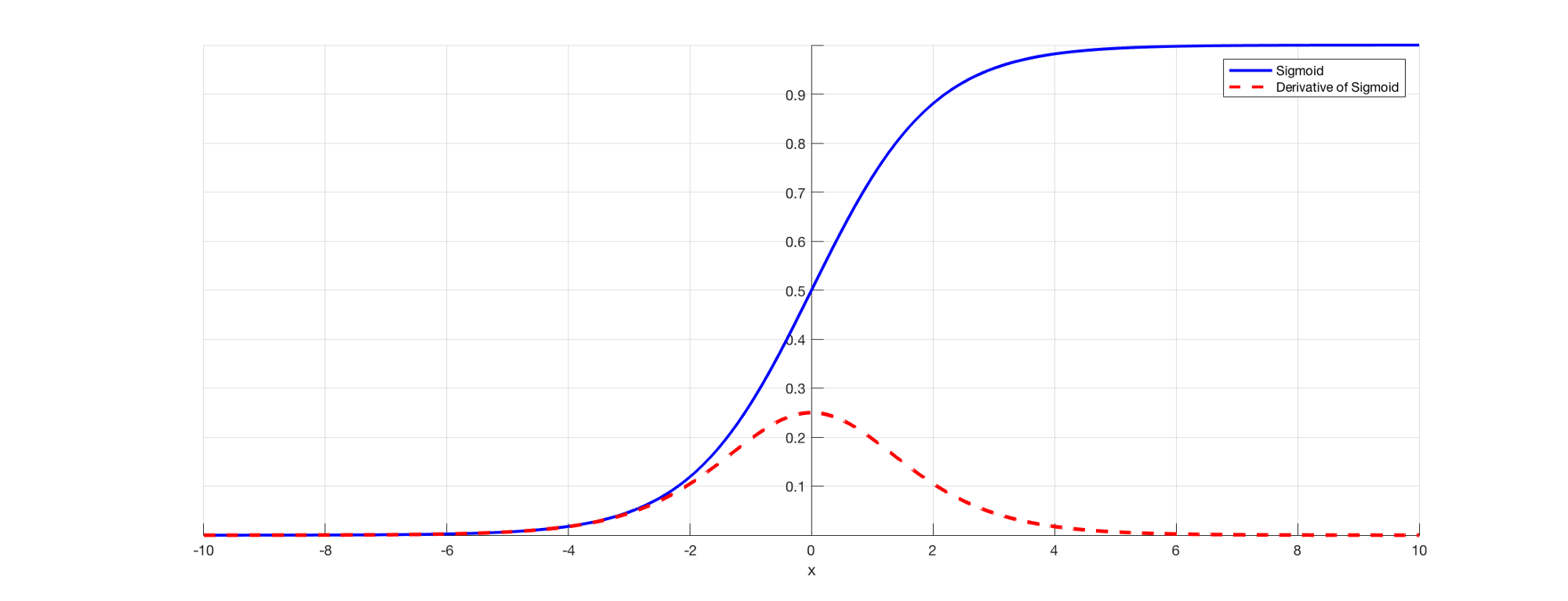
Fuente: (https://towardsdatascience.com/the-vanishing-gradient-problem-69bf08b15484)
Por lo tanto, los pesos y los sesgos no se actualizarán correctamente y, a medida que las capas continúan aumentando, caímos más en esto y nuestro modelo no funciona correctamente y genera imprecisiones en toda la red.
Algunas formas de resolver este problema son inicializar la matriz de peso correctamente o optar por algo como un ReLULa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción... en lugar de funciones sigmoideas o tanh.
Problema de gradiente explosivo
La explosión de gradientes es un problema en el que el valor del gradiente se vuelve muy grande y esto ocurre a menudo cuando inicializamos pesos más grandes y podríamos terminar con NaN. Si nuestro modelo sufrió este problema, no podemos actualizar los pesos en absoluto. Pero afortunadamente, el recorte de degradado es un proceso que podemos usar para esto. En un valor de umbral predefinido, recortamos el degradado. Esto evitará que el valor del gradiente supere el umbral y nunca terminaremos en números grandes o NaN.
Dependencia a largo plazo de las palabras
Ahora, consideremos una oración como, “Las nubes están en el ____”. Nuestro modelo RNN puede predecir fácilmente ‘Cielo’ aquí y esto se debe al contexto de las nubes y muy pronto viene como una entrada a su capa anterior. Pero puede que no siempre sea así.
Imagen si tuviéramos una oración como: “Jane nació en Kerala. Jane solía jugar para el equipo de fútbol femenino y también ha encabezado los exámenes a nivel estatal. Jane habla ____ con fluidez «.
Esta es una oración muy larga y el problema aquí es que, como humano, puedo decir que, dado que Jane nació en Kerala y superó su examen estatal, es obvio que debería dominar el «malayalam» con mucha fluidez. Pero, ¿cómo sabe nuestra máquina sobre esto? En el punto en el que el modelo quiere predecir palabras, es posible que haya olvidado el contexto de Kerala y más sobre otra cosa. Este es el problema de la dependencia a largo plazo en RNN.
Unidireccional en RNN
Como hemos comentado anteriormente, RNN toma datos secuencialmente y palabra por palabra o letra por letra. Ahora, cuando intentamos predecir una palabra en particular, no estamos pensando en su contexto futuro. Es decir, digamos que tenemos algo como: “El mouse es realmente bueno. El mouse se utiliza para ____ para facilitar el uso de las computadoras «. Ahora, si podemos viajar bidireccionalmente y también podemos ver el contexto futuro, podemos decir que ‘Desplazamiento’ es la palabra apropiada aquí. Pero, si es unidireccional, nuestro modelo nunca ha visto computadoras, entonces, ¿cómo sabe si estamos hablando del ratón animal o del ratón de la computadora?
Estos problemas se resuelven más tarde utilizando modelos de lenguaje como BERT, donde podemos ingresar oraciones completas y usar el mecanismo de auto atención para comprender el contexto del texto.
Utilice la memoria a corto plazo a largo plazo (LSTM)
Una forma de resolver el problema del gradiente de fuga y la dependencia a largo plazo en RNN es optar por las redes LSTM. LSTM tiene una introducción a tres puertas llamadas puertas de entrada, salida y olvido. En las que las puertas de olvido se encargan de la información que se necesita dejar pasar a través de la red. De esta forma, podemos tener memoria a corto y largo plazo. Podemos pasar la información a través de la red y recuperarla incluso en una etapa muy posterior para identificar el contexto de predicción. El siguiente diagrama muestra la red LSTM.
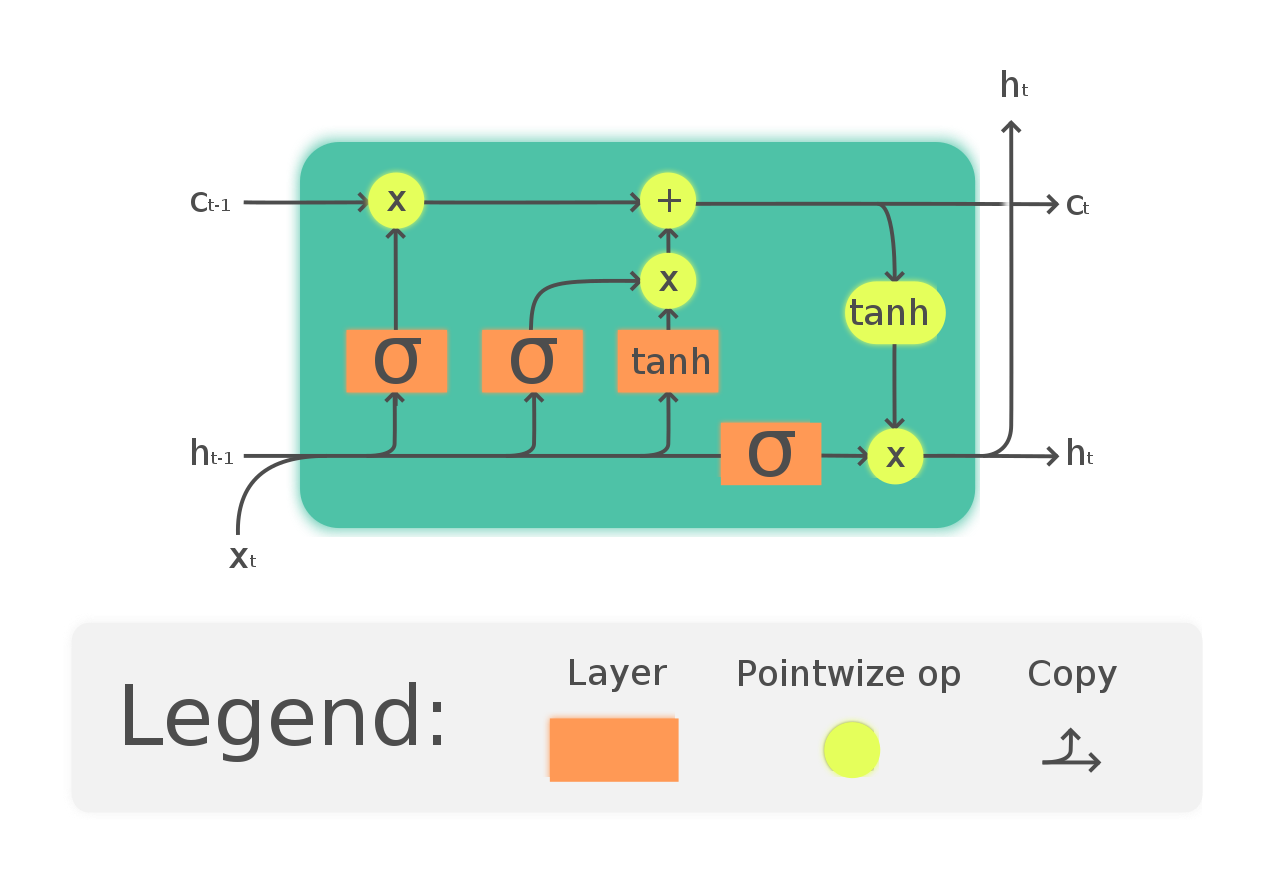
(https://en.wikipedia.org/wiki/Long_short-term_memory#/media/File:The_LSTM_Cell.svg)
Siga este tutorial para obtener una mejor comprensión y un ejemplo intuitivo de LSTM: https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-sa-step-by-step-explanation-44e9eb85bf21
Con suerte, ahora ha entendido los problemas de usar una RNN y por qué hemos optado por redes más complejas como LSTM.
Referencias
1.http: //www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
2. https://analyticsindiamag.com/what-are-the-challenges-of-training-recurrent-neural-networks/
3. https://towardsdatascience.com/the-vanishing-gradient-problem-69bf08b15484
4. https://en.wikipedia.org/wiki/Long_short-term_memory
5. https://www.udacity.com/course/deep-learning-nanodegree–nd101
6. Imagen de vista previa: https://unsplash.com/photos/Sot0f3hQQ4Y
Conclusión
No dudes en conectarte conmigo en:
1. https://www.linkedin.com/in/siddharth-m-426a9614a/
2. https://github.com/Siddharth1698
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





