Introducción
La estadística de pedidos es un concepto muy útil en las ciencias estadísticas. Tienen una amplia gama de aplicaciones que incluyen modelado de subastas, carreras de autos y pólizas de seguros, optimización de procesos de producción, estimación de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de distribuciones, et al. A través de este artículo, entenderemos la idea de las estadísticas de pedidos. Primero entenderemos su significado y gradualmente procederemos a su distribución, cubriendo eventualmente conceptos más avanzados.
Supongamos que tenemos un conjunto de variables aleatorias X1, X2, …, Xnorte, que son independientes e idénticamente distribuidos (iid). Por independencia, queremos decir que el valor tomado por una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... aleatoria no está influenciado por los valores tomados por otras variables aleatorias. Por distribución idéntica, queremos decir que la función de densidad de probabilidad (PDF) (o de manera equivalente, la función de distribución acumulativa, CDF) para las variables aleatorias es la misma. La Kth La estadística de orden para este conjunto de variables aleatorias se define como kth valor más pequeño de la muestra.
Para comprender mejor este concepto, tomaremos 5 variables aleatorias X1, X2, X3, X4, X5. Observaremos una realización / resultado aleatorio de la distribución de cada una de estas variables aleatorias. Supongamos que obtenemos los siguientes valores:
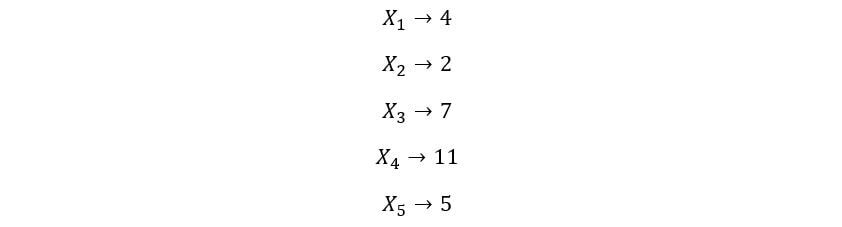
La Kth la estadística de orden para este experimento es la kth valor más pequeño del conjunto {4, 2, 7, 11, 5}. Entonces, el 1S t la estadística de orden es 2 (valor más pequeño), la 2Dakota del Norte la estadística de orden es 4 (la siguiente más pequeña), y así sucesivamente. El 5th el estadístico de orden es el quinto valor más pequeño (el valor más grande), que es 11. Repetimos este proceso muchas veces, es decir, extraemos muestras de la distribución de cada una de estas iid variables aleatorias y encontramos la kth valor más pequeño para cada conjunto de observaciones. La distribución de probabilidad de estos valores da la distribución de kth estadísticas de pedidos.
En general, si ordenamos variables aleatorias X1, X2, …, Xnorte en orden ascendente, entonces la kth la estadística de orden se muestra como:

La notación general de la kth la estadística de orden es X(k). Nota X(k) es diferente de Xk. Xk es la kth variable aleatoria de nuestro conjunto, mientras que X(k) es la kth orden estadística de nuestro conjunto. X(k) toma el valor de Xk si Xk es la kth Variable aleatoria cuando las realizaciones se ordenan en orden ascendente.
El 1S t estadística de orden X(1) es el conjunto de los valores mínimos de la realización del conjunto de ‘n’ variables aleatorias. Luegoth estadística de orden X(norte) es el conjunto de los valores máximos (n-ésimo valores mínimos) de la realización del conjunto de ‘n’ variables aleatorias. Pueden expresarse como:
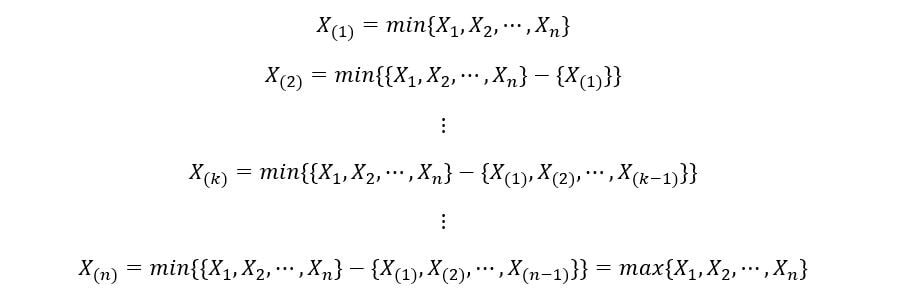
Distribución de estadísticas de pedidos
Ahora intentaremos averiguar la distribución de las estadísticas de pedidos. Primero describiremos la distribución de la nth estadística de orden, luego el 1S t orden estadística y finalmente la kth estadística de orden en general.
A) Distribución de la nth Estadística de pedidos:
Dejemos que la función de densidad de probabilidad (PDF) y la función de distribución acumulativa (CDF) nuestras variables aleatorias sean fX(x) y FX(x) respectivamente. Por definición de CDF,
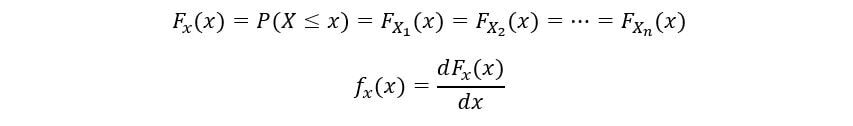
Dado que nuestras variables aleatorias se distribuyen de manera idéntica, tienen el mismo PDF fX(x) y CDF FX(X). Ahora calcularemos la CDF de nth estadística de orden (Fnorte(x)) como sigue:
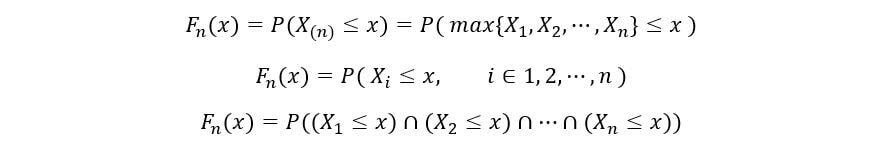
Las variables aleatorias X1, X2, …, Xnorte también son independientes. Por tanto, por propiedad de la independencia,
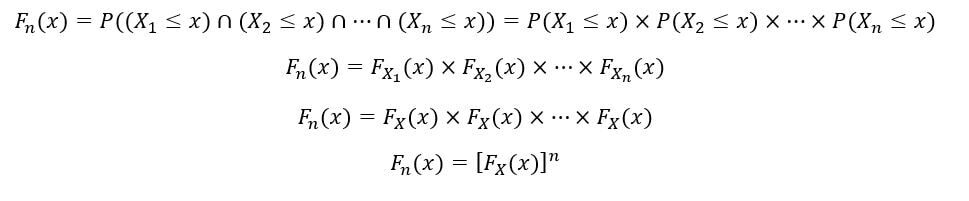
El PDF de la nth orden estadístico (fnorte(x)) se calcula de la siguiente manera:
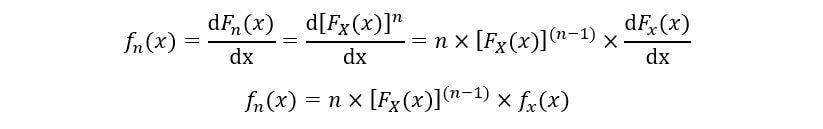
Por lo tanto, la expresión para PDF y CDF de nth Se ha obtenido la estadística de orden.
B) Distribución del 1S t Estadística de pedidos:
La CDF de una variable aleatoria también se puede calcular como el uno menos la probabilidad de que la variable aleatoria X tome un valor mayor o igual que x. Matemáticamente,
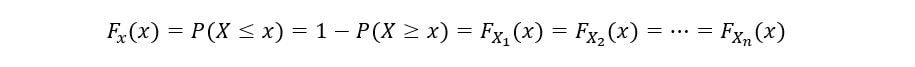
Determinaremos el CDF de 1S t estadística de orden (F1(x)) como sigue:
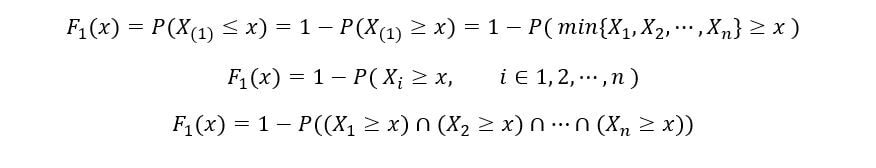
Una vez más, utilizando la propiedad de independencia de las variables aleatorias,
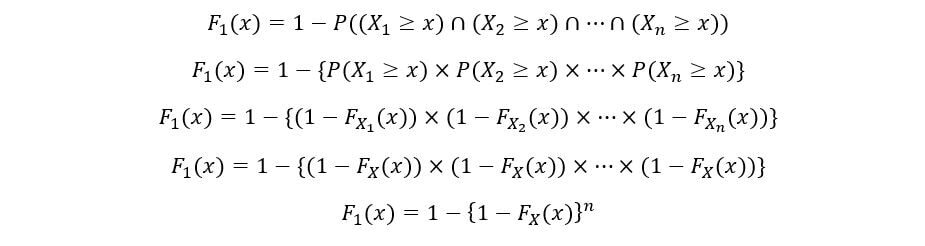
El PDF del 1S t orden estadístico (f1(x)) se calcula de la siguiente manera:
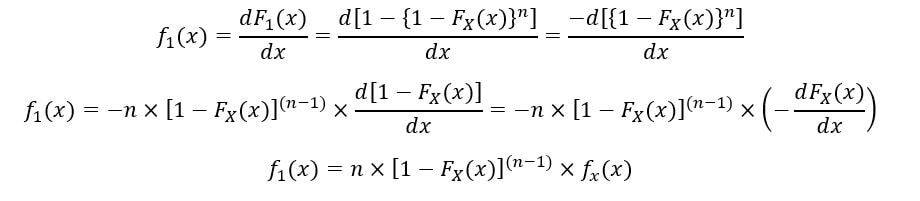
Por lo tanto, la expresión para PDF y CDF de 1S t Se ha obtenido la estadística de orden.
C) Distribución de la kth Estadística de pedidos:
Tenedorth estadística de orden, en general, la siguiente ecuación describe su CDF (Fk(X)):
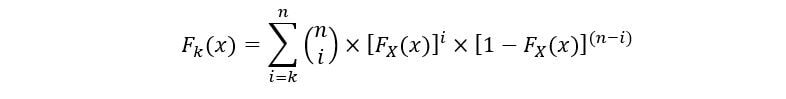
El PDF de kth orden estadístico (fk(x)) se expresa como:
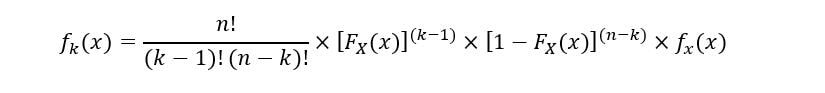
Para evitar confusiones, usaremos pruebas geométricas para entender la ecuación. Como se discutió anteriormente, el conjunto de variables aleatorias tiene el mismo PDF (fX(X)). El siguiente gráfico muestra un PDF de muestra con la kth Estadística de orden obtenida de un muestreo aleatorio:
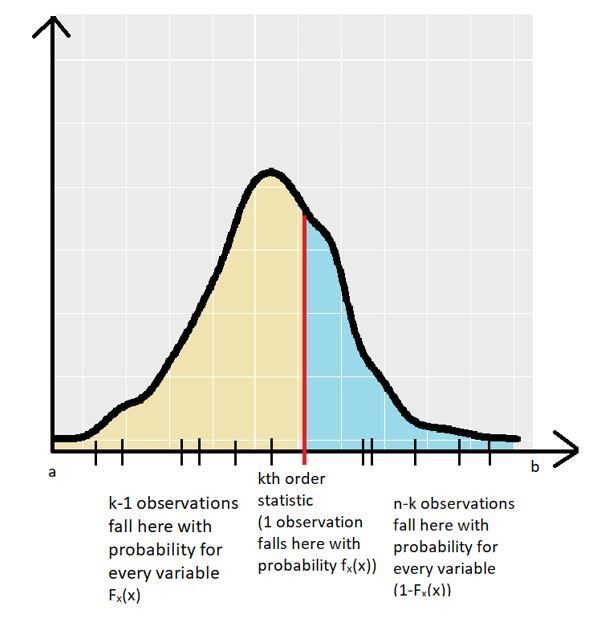
Entonces, la PDF de las variables aleatorias fX(x) se define entre el intervalo [a,b]. El estadístico de k-ésimo orden para una muestra aleatoria se muestra con la línea roja. Las otras realizaciones variables (para la muestra aleatoria) se muestran mediante las pequeñas líneas negras en el eje x.
Hay exactamente (k – 1) observaciones de variables aleatorias que caen en la región amarilla del gráfico (la región entre a & kth estadística de orden). La probabilidad de que una observación particular caiga en esta región está dada por la CDF de las variables aleatorias (FX(X)). Pero somos conscientes de que (k – 1) observaciones cayeron en la región, lo que nos da el término (por independencia) (FX(X))(k – 1).
Hay exactamente (n – k) observaciones de variables aleatorias que caen en la región azul del gráfico (la región entre kth orden estadística & b). La probabilidad de que una observación particular caiga en esta región viene dada por el 1 – CDF de las variables aleatorias (1– FX(X)). Pero somos conscientes de que (n – k) observaciones cayeron en la región, lo que nos da el término (por independencia) (1-FX(X))(n – k).
Finalmente, exactamente 1 observación cae exactamente en el estadístico de k-ésimo orden con probabilidad fX(X). Por lo tanto, el producto de los 3 términos nos da una idea del significado geométrico de la ecuación para PDF del estadístico de k-ésimo orden. Pero, ¿de dónde viene el término factorial? El escenario anterior solo mostró uno de los muchos ordenamientos. Puede haber muchas de estas combinaciones. El número total de tales combinaciones se muestra a continuación:
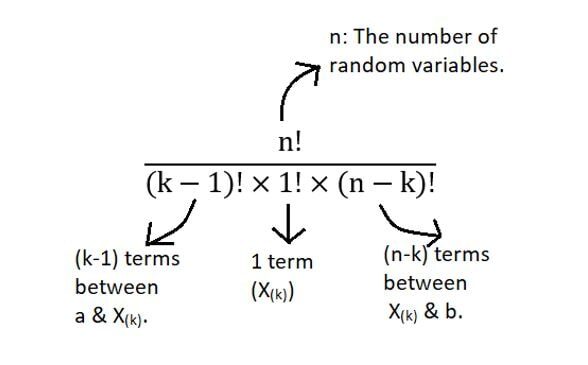
Por tanto, el producto de todos estos términos nos da la distribución general de kth estadística de pedidos.
Funciones útiles de las estadísticas de pedidos
Las estadísticas de pedidos dan lugar a varias funciones útiles. Entre ellos, los notables incluyen el rango de la muestra y la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... de la muestra.
1) Rango de muestra: Se define como la diferencia entre el valor más grande y el más pequeño. Se expresa de la siguiente manera:
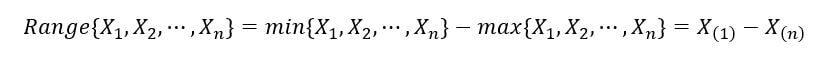
2) Mediana de la muestra: La mediana de la muestra divide la muestra aleatoria (realizaciones del conjunto de variables aleatorias) en dos mitades, una que contiene las muestras con valores más bajos y la otra que contiene las muestras con valores más altos. Es como la estadística de orden medio / central. Se define matemáticamente como:
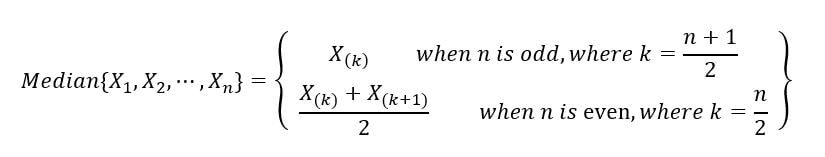
PDF conjunto de estadísticas de pedidos
Una función de densidad de probabilidad conjunta puede ayudarnos a comprender mejor la relación entre dos variables aleatorias (estadísticas de dos órdenes
en nuestro caso). El PDF conjunto para cualquier estadística de 2 órdenes X(a) & X(B), tal que 1 ≤ a ≤ b ≤ n viene dado por la siguiente ecuación:
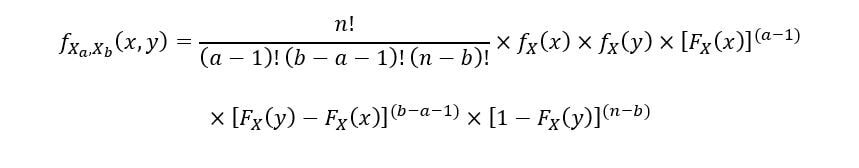
Ejemplo
Usaremos un ejemplo muy simple para ilustrar la distribución de las estadísticas de orden: la distribución uniforme estándar (U[0, 1] distribución). Tomaremos 5 variables aleatorias X1, X2, X3, X4, X5, todos tienen la U[0, 1] distribución. Para este conjunto de variables aleatorias, calcularemos y trazaremos el 1S t, 3rd (la mediana de la muestra) y 5th (norteth) estadísticas de pedidos. La siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... muestra la U[0, 1] distribución:
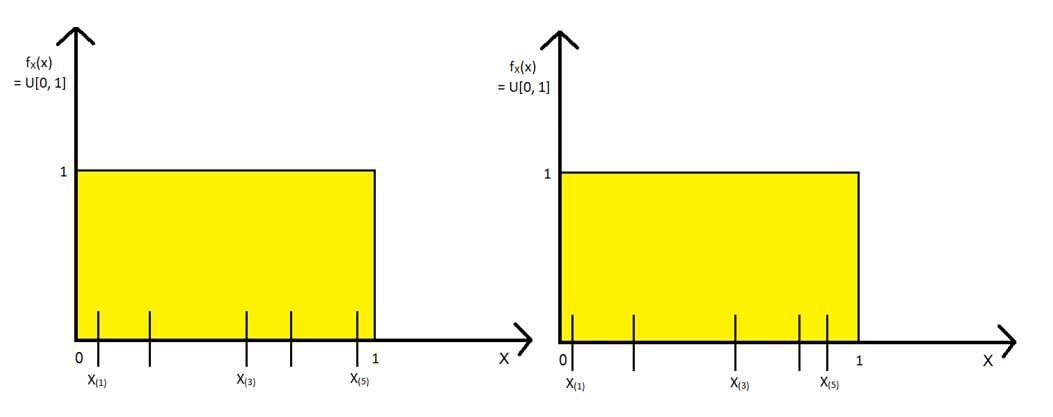
Dibujaremos muestras aleatorias de la siguiente manera y encontraremos el 1S t, 3rd & 5th estadística de orden para cada muestra. A continuación se muestran dos de las muestras:
El PDF y CDF de distribución uniforme estándar se dan como:
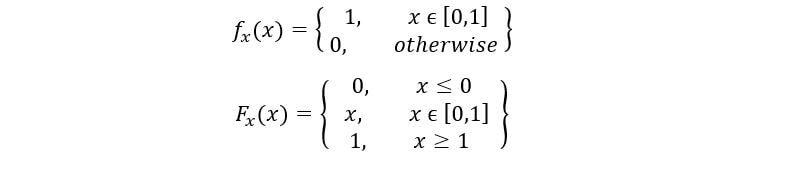
Usaremos esta información y calcularemos X(1), X(3) & X(5) usando las fórmulas que derivamos. Tomaremos el caso solo cuando x esté entre 0 y 1 (para otros casos, la estadística de orden es cero ya que PDF es cero).
A) Para 1S t estadística de orden:
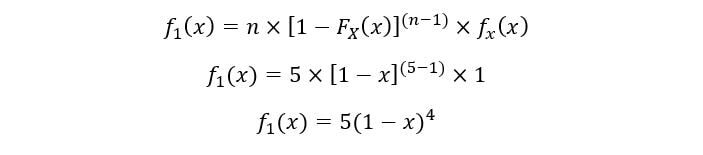
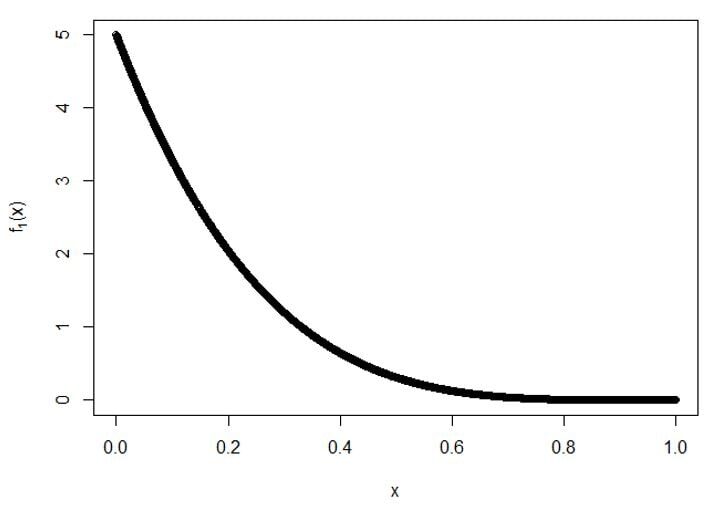
Trazar para f1(X):
B) Para 3rd estadística de orden:
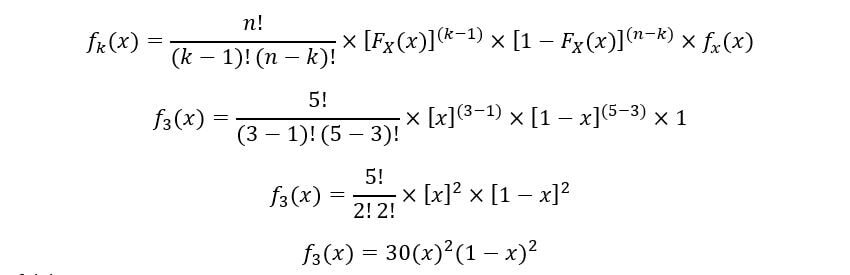
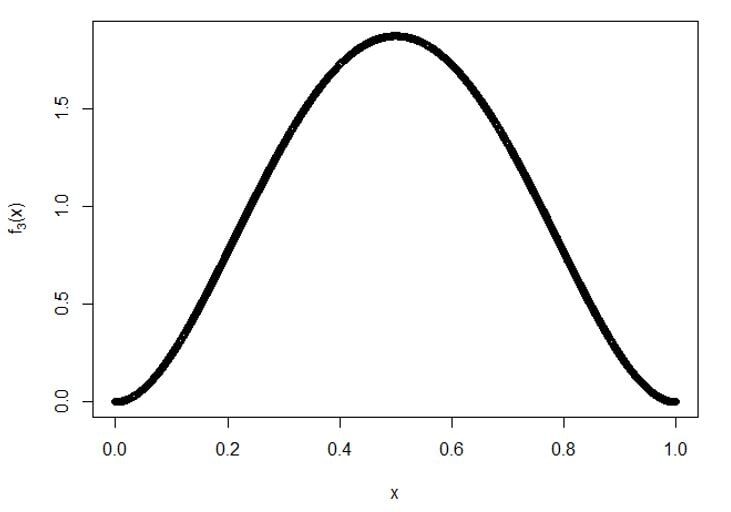
Trazar para f5(X):
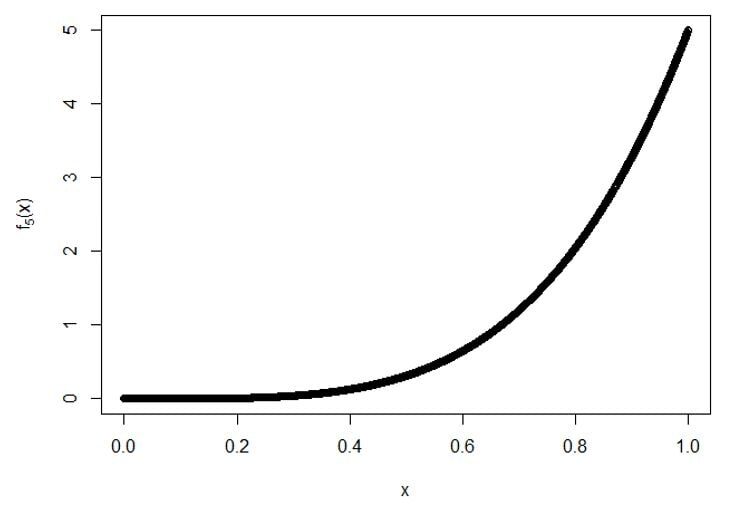
C) Para 5th estadística de orden:
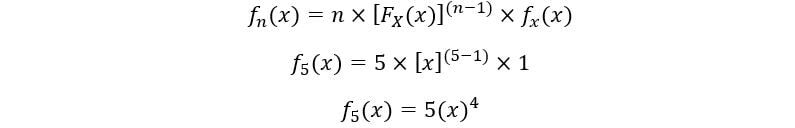
Trazar para f5(X):
Conclusión
Por lo tanto, hemos explorado los conceptos de estadística de pedidos a fondo. Se puede modelar una amplia gama de procesos físicos a través de estadísticas de pedidos, explotando sus propiedades, particularmente sus distribuciones.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





