Cuando el día estaba llegando a su fin, pensé en encajar en otra reunión. Dos analistas de mi equipo habían estado trabajando para crear un conjunto de datos para uno de los modelos predictivos que queríamos construir. La experiencia laboral combinada (en modelos predictivos) entre los analistas fue de ~ 5 años. Esperaba pasar la reunión y salir por el día.
Entonces, comenzó la reunión. ¡Cinco minutos después de la reunión y supe que la reunión tomará mucho más tiempo de lo que pensé inicialmente!
¿El motivo? Repasemos la discusión tal como sucedió:

Kunal: ¿Cuántas filas tiene en el conjunto de datos?
Analista 1: (Después de revisar el conjunto de datos) X filas
Kunal: ¿Cuántas filas esperas?
Analista 1 y 2: Mirada en blanco en sus caras
Kunal: ¿Cuántos eventos / puntos de datos espera en el período / cada mes?
Analista 1 y 2: …. (Ninguno de ellos tenía ni idea)
El número de filas en el conjunto de datos me pareció más alto. Los analistas lo habían pasado por alto claramente, debido a que no lo compararon con las expectativas comerciales (o no lo tenían en primer lugar). Al profundizar, encontramos que algunos eventos tenían varias filas en los conjuntos de datos y, por eso, un mayor número de filas.
Un alto porcentaje de analistas habrían pasado por una experiencia semejante en alguna vez de su carrera..
A veces, ya sea debido a las presiones de la línea de tiempo o por alguna otra razón, pasamos por alto hacer controles básicos de cordura en el conjunto de datos en el que estamos trabajando. A pesar de esto, pasar por alto la precisión de los datos en las etapas iniciales del proyecto puede resultar muy costoso y, por eso, de forma general es importante destacar ser paranoico con relación a la precisión de los datos.
Por lo general, sigo un marco simple para verificar la precisión de los puntos de datos. En este post, compartiré el procedimiento que suelo utilizar para verificar la cordura de los datos. El marco va de arriba hacia abajo, lo que se adapta bien. Si tiene errores evidentes en los conjuntos de datos, serán evidentes al principio del procedimiento.
Tenga en cuenta que el post restante asume que está trabajando en un conjunto de datos estructurados. Para conjuntos de datos no estructurados, aún cuando los principios se seguirían aplicando, el procedimiento cambiaría.
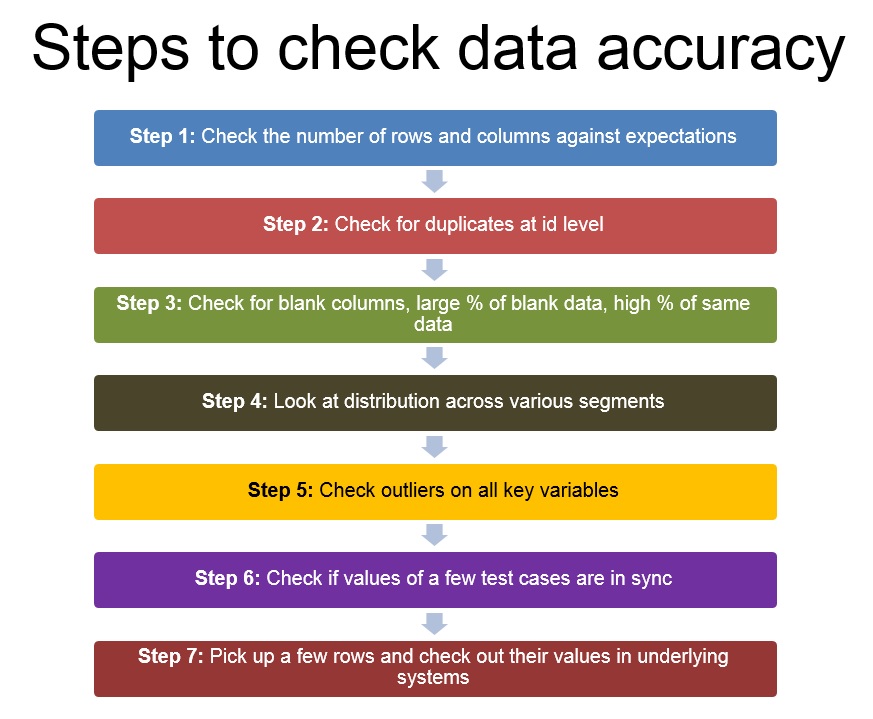
Paso 1: verifique el número de columnas y filas con las expectativas
El primer paso tan pronto como obtenga cualquier conjunto de datos sería verificar si tiene todas las filas y columnas requeridas. El número de columnas vendría dictado por el número de hipótesis que tiene y las variables que necesitaría para probar / refutar estas hipótesis.
Por otra parte, el número de filas vendría dictado por el número de eventos que espera en el período seleccionado. El punto de referencia más sencillo se basaría en su comprensión empresarial.
Paso 2: Verifique si hay duplicados en el nivel de identificación (y no para toda la fila)
Una vez que esté seguro de que todas las columnas están presentes y el número de filas se ve dentro del rango esperado, verifique rápidamente si hay duplicados en el nivel de su identificación (o el nivel en el que las filas deben ser únicas; podría ser una combinación de variables)
Paso 3: compruebe si hay columnas en blanco, gran porcentaje de datos en blanco, alto% de los mismos datos
Ahora que sabe que todas las columnas están ahí y que no hay duplicados, fíjese si hay columnas que estén totalmente en blanco. Esto puede suceder en caso de que falle alguna unión o en caso de que haya algún error en la extracción de datos. Si ninguna de las columnas está en blanco, observe el% de casos en blanco por cada columna y las distribuciones de frecuencia para averiguar si los mismos datos se repiten en más casos de los esperados.
Paso 4: observe la distribución en varios segmentos; verifique la comprensión empresarial y utilice tablas dinámicas
Este paso continúa donde termina 3. En lugar de mirar las frecuencias de los puntos de datos individualmente, observe sus distribuciones. ¿Espera una distribución normal, bipolar o uniforme? ¿La distribución se parece a lo que esperabas?
Paso 5. Verifique los valores atípicos en todas las variables clave, especialmente las calculadas
Una vez que las distribuciones se vean bien, busque valores atípicos. Especialmente en los casos en los que ha calculado columnas. ¿Los valores de Extreme se asemejan a los que deseaba? Asegúrese de que no haya divisiones entre cero, ha limitado los valores que le gustaría.
Paso 6: compruebe si los valores de algunos casos de prueba están sincronizados
Una vez que haya verificado todas las columnas individualmente, verifique si están sincronizadas entre sí. Compruebe si las distintas fechas de los casos están en orden cronológico (p. Ej., ¿Los saldos, el gasto y el límite de crédito están sincronizados entre sí para los clientes de su tarjeta de crédito?
Paso 7: elija algunas filas y verifique sus valores en los sistemas subyacentes
Una vez que se hayan realizado todos los pasos anteriores, es hora de verificar algunas muestras consultando los sistemas o bases de datos subyacentes. Si hubo algún error en los datos, idealmente ya debería haberlo identificado. Este paso solo garantiza que los datos estén como estaban en los sistemas subyacentes.
Tenga en cuenta que algunos de estos errores pueden detectarse a través de el uso de registros proporcionados por su herramienta. Mirar los registros de forma general proporciona mucha información sobre errores y advertencias.
Estos fueron los pasos que utilizo para verificar la precisión de los datos y, por lo general, me ayudan a detectar errores evidentes en los datos. Por lo visto, no son la solución a todos los posibles errores, pero deberían darte un buen punto de partida y una buena dirección. ¿Qué opinas de este marco? ¿Existen otros marcos / métodos que utiliza para verificar la precisión de los datos? En caso de ser así, agrégalos en los comentarios a continuación.





