Si conoce a 10 personas que han estado en la ciencia de datos durante más de 5 años, ¡es probable que todos conozcan o hayan usado SQL en alguna vez de alguna forma! Tal es el grado de influencia que SQL tuvo en cualquier cosa que ver con datos estructurados.
En este post, aprenderemos los conceptos básicos de SQL y nos centraremos en SQL para RDBMS. Como verá, SQL es bastante sencillo de aprender y comprender.
¿Qué es SQL?
SQL son las siglas de Structured Query Language. Es un lenguaje de programación estándar para tener acceso a una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... relacional. Ha sido diseñado para la administración de datos en sistemas de administración de bases de datos relacionales (RDBMS) como Oracle, MySQL, MS SQL Server, IBM DB2.
SQL es uno de los primeros lenguajes comerciales utilizados para el modelo relacional de Edgar F. Codd, además descrito en su influyente post de 1970, “Un modelo relacional de datos para grandes bancos de datos compartidos. «
Previamente, SQL era un lenguaje de facto para la generación de profesionales de tecnología de la información. Esto se debió al hecho de que los almacenes de datos consistían en uno u otro RDBMS. La simplicidad y la belleza del lenguaje permitieron a los profesionales del almacenamiento de datos consultar datos y proporcionarlos a los analistas comerciales.
A pesar de esto, el problema con RDBMS es que a menudo son adecuados solo para información estructurada. Para información no estructurada, las bases de datos más nuevas como MongoDB y HBaseHBase es una base de datos NoSQL diseñada para manejar grandes volúmenes de datos distribuidos en clústeres. Basada en el modelo de columnas, permite un acceso rápido y escalable a la información. HBase se integra fácilmente con Hadoop, lo que la convierte en una opción popular para aplicaciones que requieren almacenamiento y procesamiento de datos masivos. Su flexibilidad y capacidad de crecimiento la hacen ideal para proyectos de big data.... (de Hadoop) demuestran ser más adecuadas. Parte de esto es una compensación en las bases de datos, que se debe al teorema CAP.
¿Qué es el teorema CAP?
El teorema de CAP establece que, en el mejor de los casos, podemos aspirar a dos de las tres propiedades siguientes. CAP significa:
Consistencia – Esto significa que los datos en la base de datos permanecen consistentes después de la ejecución de una operación.
Disponibilidad – Esto significa que el sistema de base de datos está siempre activo para garantizar la disponibilidad.
Tolerancia de partición – Esto significa que el sistema continúa funcionando inclusive si la transferencia de información entre los servidores no es confiable.
Las diversas bases de datos y sus relaciones con el teorema de CAP se muestran a continuación:
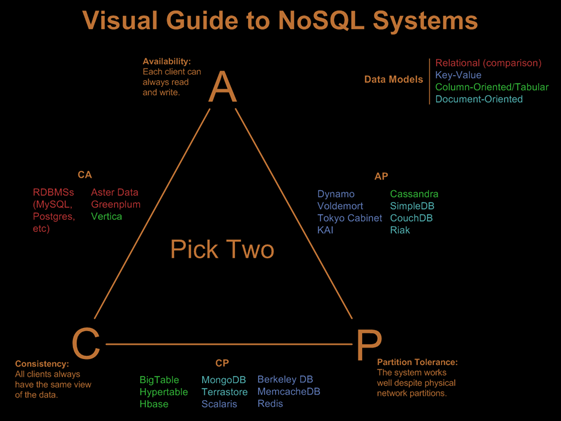
Propiedades de las bases de datos:
A pesar de esto, una transacciónLa "transacción" se refiere al proceso mediante el cual se lleva a cabo un intercambio de bienes, servicios o dinero entre dos o más partes. Este concepto es fundamental en el ámbito económico y legal, ya que implica el acuerdo mutuo y la consideración de términos específicos. Las transacciones pueden ser formales, como contratos, o informales, y son esenciales para el funcionamiento de mercados y negocios.... de base de datos debe ser compatible con ACID. ACID significa atómico, consistente, aislado y duradero, como se explica a continuación:
Atómico: Una transacción debe completarse con todas sus modificaciones de datos o no.
Consistente: Al final de la transacción, todos los datos deben dejarse consistentes.
Aislado : Las modificaciones de datos hechas por una transacción deben ser independientes de otras transacciones.
Durable : Al final de la transacción, los efectos de las modificaciones hechas por la transacción deben ser permanentes en el sistema.
Para contrarrestar el ACID, los servicios consistentes proporcionan características BASE (Simplemente disponible, estado suave, consistencia eventual).
Conjunto de comandos en SQL
SELECCIONE- El siguiente es un ejemplo de una consulta SELECTEl comando "SELECT" es fundamental en SQL, utilizado para consultar y recuperar datos de una base de datos. Permite especificar columnas y tablas, filtrando resultados mediante cláusulas como "WHERE" y ordenando con "ORDER BY". Su versatilidad lo convierte en una herramienta esencial para la manipulación y análisis de datos, facilitando la obtención de información específica de manera eficiente.... que devuelve una lista de libros económicos. La consulta recupera todas las filas del Biblioteca mesa en la que el precio La columna contiene un valor menor que 10,00. El resultado se clasifica en orden ascendente por precio. El asterisco en el elegir lista indica que todas las columnas de la Libro
SELECT * FROM Library WHERE"WHERE" es un término en inglés que se traduce como "dónde" en español. Se utiliza para hacer preguntas sobre la ubicación de personas, objetos o eventos. En contextos gramaticales, puede funcionar como adverbio de lugar y es fundamental en la formación de preguntas. Su correcta aplicación es esencial en la comunicación cotidiana y en la enseñanza de idiomas, facilitando la comprensión y el intercambio de información sobre posiciones y direcciones.... price < 10.00 ORDER BY price;
La tabla debe incluirse en el conjunto de resultados.
ACTUALIZAR –
Esta consulta ayuda a actualizar tablas en una base de datos. Además se puede combinar la consulta SELECT con el operador GROUP BYLa cláusula "GROUP BY" en SQL se utiliza para agrupar filas que comparten valores en columnas específicas. Esto permite realizar funciones de agregación, como SUM, COUNT o AVG, sobre los grupos resultantes. Su uso es fundamental para analizar datos y obtener resúmenes estadísticos. Es importante recordar que todas las columnas seleccionadas que no forman parte de una función de agregación deben incluirse en la cláusula "GROUP BY".... para agregar estadísticas de una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... numérica por una variable categórica.
UNIONES-
Por eso, SQL se utiliza mucho no solo para consultar datos, sino además para unir los datos devueltos por tales consultas o tablas. La fusión de datosLa fusión de datos es un proceso que integra información de diversas fuentes para obtener un conjunto unificado y coherente. Esta técnica es fundamental en áreas como la inteligencia artificial, la minería de datos y la analítica, ya que permite mejorar la precisión y la calidad de los análisis. Al combinar datos heterogéneos, se pueden descubrir patrones y tendencias que, de otro modo, pasarían desapercibidos.... en SQL se realiza a través de ‘uniones’. La próxima infografía se utiliza a menudo para explicar las uniones SQL:
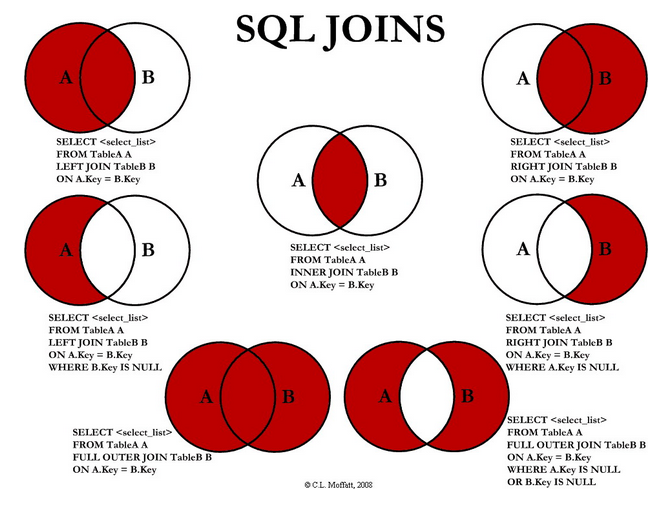
Cómo utilizar join"JOIN" es una operación fundamental en bases de datos que permite combinar registros de dos o más tablas basándose en una relación lógica entre ellas. Existen diferentes tipos de JOIN, como INNER JOIN, LEFT JOIN y RIGHT JOIN, cada uno con sus propias características y usos. Esta técnica es esencial para realizar consultas complejas y obtener información más relevante y detallada a partir de múltiples fuentes de datos.... en SQL
CASO- Tenemos el operador case / when / then / else / end en SQL. Funciona como si no
en otros lenguajes de programación:
CASE WHEN n > 0 THEN 'positive' WHEN n < 0 THEN 'negative' ELSE 'zero' END
Subconsultas anidadas – Las consultas se pueden anidar de modo que los resultados de una consulta se puedan usar en otra consulta a través de un operador relacional o una función de agregación. Una consulta anidada además se conoce comosubconsultaUna subconsulta es una consulta dentro de otra consulta en SQL. Se utiliza para obtener resultados de una base de datos que dependan de los resultados de una consulta externa. Las subconsultas pueden aparecer en cláusulas SELECT, WHERE o FROM, y permiten realizar operaciones más complejas al filtrar o modificar datos de manera eficiente. Su uso adecuado optimiza el rendimiento y la claridad del código SQL....
.
¿Dónde usamos SQL?
- SQL se ha utilizado ampliamente para recuperar datos, fusionar datos, realizar consultas de casos grupales y anidados durante décadas. Inclusive para la ciencia de datos, SQL se ha adoptado ampliamente. A continuación, se muestran algunos ejemplos del uso específico de análisis de SQL:
- En el caso del lenguaje SAS que utiliza PROC SQL, podemos escribir consultas SQL para consultar, actualizar y manipular datos.
- En R, se puede utilizar el paquete sqldf para ejecutar consultas SQL en marcos de datos.
En Python, la biblioteca pandasql le posibilita consultar Pandas DataFrames usando sintaxis SQL.
¿SQL influye además en otros lenguajes?
El inconveniente de las bases de datos relacionales es que no pueden manejar datos no estructurados. Para hacer frente a la aparición, han surgido nuevas bases de datos y se les da NoSQL como un nombre alternativo al DBMS. Pero SQL aún no ha muerto. Ver también:
Un mapeo de SQL a MongoDB
A continuación se muestran algunos lenguajes en los que SQL cuenta con una influencia significativa:
.
SQL-Mapreduce
– Teradata utiliza la base de datos Aster que utiliza SQL con MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data.... para grandes conjuntos de datos en la era de Big Data. SQL-MapReduce® es un marco creado por Teradata Aster para permitir a los desarrolladores escribir funciones SQL-MapReduce poderosas y altamente expresivas en lenguajes como Java, C #, Python, C ++ y R y llevarlas a la plataforma de descubrimiento para análisis de alto rendimiento. Después, los analistas pueden invocar funciones SQL-MapReduce usando SQL estándar o R por medio de la base de datos Aster.
Spark SQL – El proyecto Spark de Apache es paraProcesamiento en tiempo real, en memoria y en paralelo de datos de Hadoop
. Spark SQL se basa en él para permitir que las consultas SQL se escriban en los datos. En Impala de Cloudera, los datos almacenados en HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información... o HBase se pueden consultar, y la sintaxis SQL es la misma que la de Apache HiveHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.....
Ver además: Obtenga más información sobre las formas de realizar consultas en Hadoop mediante SQLaquí
.
Notas finales
En este post discutimos sobre SQL, sus usos, el teorema CAP e influencia de SQL en otros lenguajes. Un conocimiento básico de SQL es muy relevante en el mundo actual, donde Python, R, SAS son lenguajes dominantes en la ciencia de datos. SQL sigue siendo relevante en la era de BIG DATA. La belleza del lenguaje sigue siendo su estructura elegante y simple. Thinkpot:
¿Crees que SQL se ha convertido en un arma inevitable para la administración de datos? ¿Recomendaría algún otro idioma de base de datos?
Comparta sus puntos de vista / opinión / comentarios con nosotros en la sección de comentarios a continuación. ¡Nos encantaría escucharlo de usted! Si le gusta lo que acaba de leer y desea continuar con su aprendizaje sobre análisis,suscríbete a nuestros correos electrónicos , Síguenos en Twitter o como nuestropagina de Facebook
.
Relacionado





