Spark es un motor de análisis de datos que se utiliza principalmente para una gran cantidad de procesamiento de datos. Nos permite difundir datos y operaciones computacionales en varios clústeres para comprender un aumento considerable del rendimiento.
Hoy en día, los científicos de datos prefieren Spark debido a sus diversos beneficios sobre otras herramientas de procesamiento de datos. Al usar Spark, el costo de la recopilación, el almacenamiento y la transferencia de datos disminuye. Cuando trabajamos en un problema de la vida real, es probable que poseamos grandes cantidades de datos para procesar. Por lo tanto, los diversos motores distribuidos como Hadoop, Spark, etc. se están convirtiendo en las principales herramientas dentro del ecosistema de ciencia de datos.
PySpark
PySpark es una herramienta de análisis de datos creada por Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y... Community para usar Python junto con Spark. Nos permite trabajar con RDD (Resilient Distributed Dataset)RDD (Resilient Distributed Dataset) es una abstracción fundamental en Apache Spark que permite el procesamiento eficiente de grandes volúmenes de datos. Se caracteriza por su capacidad para ser tolerante a fallos, permitiendo la recuperación de datos perdidos mediante la reconstrucción de particiones. Los RDD son inmutables, lo que facilita la paralelización de operaciones y mejora el rendimiento en la computación distribuida. Su uso es esencial para el análisis de datos... y DataFrames en Python. PySpark tiene numerosas características que lo convierten en un marco increíble y cuando se trata de lidiar con la gran cantidad de datos, PySpark nos brinda procesamiento rápido y en tiempo real, flexibilidad, computación en memoria y varias otras características. Es una biblioteca de Python para usar Spark que combina la simplicidad del lenguaje Python con la eficiencia de Spark.
Marco de datos de Pyspark
Un DataFrame es una colección distribuida de datos en filas bajo columnas con nombre. En términos simples, podemos decir que es lo mismo que una tabla en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... relacional o una hoja de Excel con encabezados de columna. Los DataFrames están diseñados principalmente para procesar una colección a gran escala de datos estructurados o semiestructurados.
En este artículo, discutiremos las 10 funciones de PySpark que son más útiles y esenciales para realizar un análisis de datos eficiente de datos estructurados.
Estamos utilizando Google Colab como el IDE para este análisis de datos.
Primero necesitamos instalar PySpark en Google Colab. Después de eso, importaremos el módulo pyspark.sql y crearemos una SparkSession que será un punto de entrada de Spark SQL API.
#installing pyspark !pip install pyspark
#importing pyspark
import pyspark
#importing sparksessio
from pyspark.sql import SparkSession
#creating a sparksession object and providing appName
spark=SparkSession.builder.appName("pysparkdf").getOrCreate()
Este objeto SparkSession interactuará con las funciones y métodos de Spark SQL. Ahora, creemos un Spark DataFrame leyendo un archivo CSV. Usaremos un conjunto de datos simple, es decir Datos nutricionales de 80 productos de cereales disponible en Kaggle.
#creating a dataframe using spark object by reading csv file
df = spark.read.option("header", "true").csv("/content/cereal.csv")
#show df created top 10 rows df.show(10)
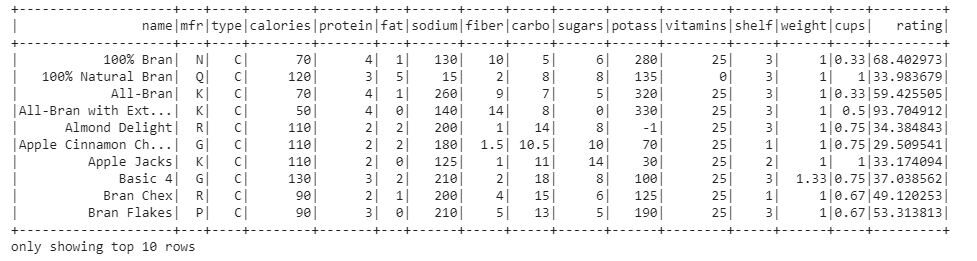
Este es el marco de datos que estamos usando para el análisis de datos. Ahora, imprimamos el esquema del DataFrame para saber más sobre el conjunto de datos.

El DataFrame consta de 16 funciones o columnas. Cada columna contiene valores de tipo cadena.
Comencemos con las funciones:
- Seleccione(): La función de selección nos ayuda a mostrar un subconjunto de columnas seleccionadas de todo el marco de datos, solo necesitamos pasar los nombres de columna deseados. Imprimamos tres columnas cualesquiera del marco de datos usando selectEl comando "SELECT" es fundamental en SQL, utilizado para consultar y recuperar datos de una base de datos. Permite especificar columnas y tablas, filtrando resultados mediante cláusulas como "WHERE" y ordenando con "ORDER BY". Su versatilidad lo convierte en una herramienta esencial para la manipulación y análisis de datos, facilitando la obtención de información específica de manera eficiente.... ().
df.select('name', 'mfr', 'rating').show(10)
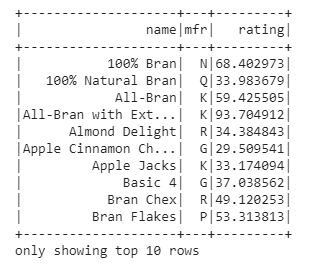
En la salida, obtuvimos el subconjunto del marco de datos con tres columnas name, mfr, rating.
- withColumn (): La función withColumn se usa para manipular una columna o para crear una nueva columna con la columna existente. Es una función de transformación, también podemos cambiar el tipo de datos de cualquier columna existente.
En el esquema de DataFrame, vimos que todas las columnas son de tipo cadena. Cambiemos el tipo de datos de la columna de calorías a un número entero.
df.withColumn("Calories",df['calories'].cast("Integer")).printSchema()

En el esquema, podemos ver que la columna Tipo de datos de calorías se cambia al tipo entero.
- agrupar por(): La función groupBy se utiliza para recopilar los datos en grupos en DataFrame y nos permite realizar funciones agregadas en los datos agrupados. Esta es una operación de análisis de datos muy común similar a la cláusula groupBy en SQL.
Averigüemos el recuento de cada cereal presente en el conjunto de datos.
df.groupBy("name", "calories").count().show()
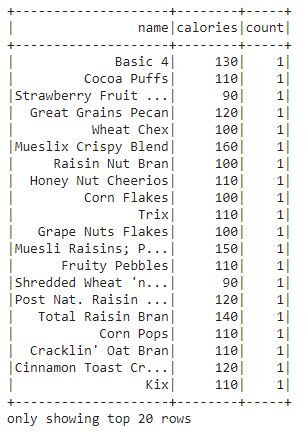
- orderBy (): La función orderBy se utiliza para ordenar todo el marco de datos en función de la columna particular del marco de datos. Ordena las filas del marco de datos según los valores de las columnas. De forma predeterminada, se clasifica en orden ascendente.
Analicemos el marco de datos en función de la columna de proteínas del conjunto de datos.
df.orderBy("protein").show()
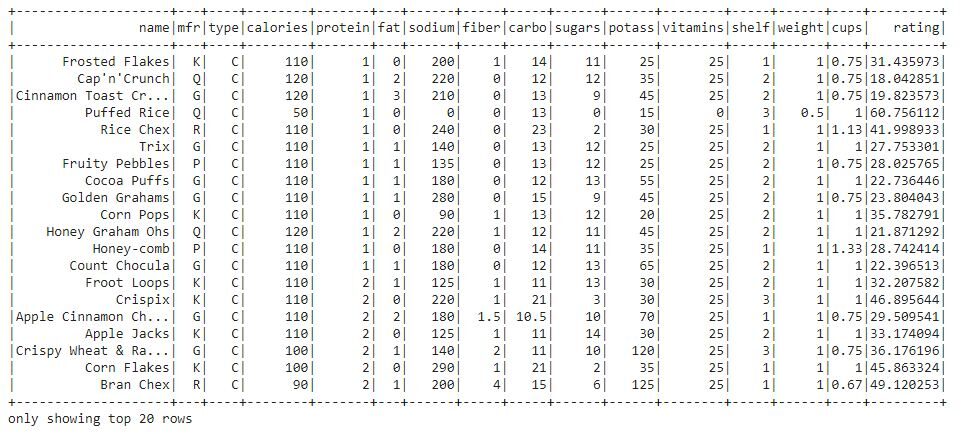
Podemos ver que todo el marco de datos está ordenado en función de la columna de proteínas.
- separar(): El split () se utiliza para dividir una columna de cadena del marco de datos en varias columnas. Esta función se aplica al marco de datos con la ayuda de withColumn () y select ().
La columna de nombre del marco de datos contiene valores en dos palabras de cadena. Dividamos la columna de nombre en dos columnas desde el espacio entre dos cadenas.
fropm pyspark.sql.functions import split
df1 = df.withColumn('Name1', split(df['name'], " ").getItem(0))
.withColumn('Name2', split(df['name'], " ").getItem(1))
df1.select("name", "Name1", "Name2").show()
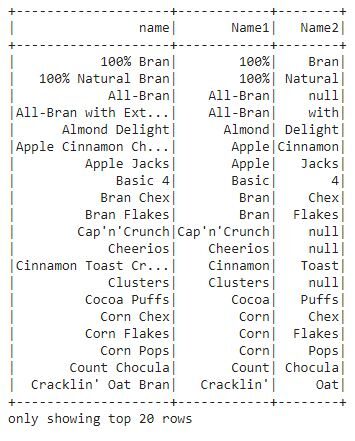
En esta salida, podemos ver que la columna de nombre está dividida en columnas.
- iluminado(): La función iluminada se usa para agregar una nueva columna al marco de datos que contiene literales o algún valor constante.
Agreguemos una columna «cantidad de ingesta» que contiene un valor constante para cada uno de los cereales junto con el nombre del cereal respectivo.
from pyspark.sql.functions import lit
df2 = df.select(col("name"),lit("75 gm").alias("intake quantity"))
df2.show()
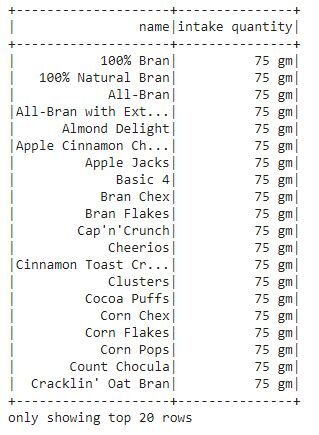
En la salida, podemos ver que se crea una nueva columna “cantidad ingerida” que contiene la cantidad ingerida de cada cereal.
- cuando(): El cuándo se utiliza la función para mostrar la salida en función de la condición particular. Evalúa la condición proporcionada y luego devuelve los valores en consecuencia. Es una función SQL que admite PySpark para verificar múltiples condiciones en una secuencia y devolver el valor. Esta función funciona de manera similar como instrucciones if-then-else y switch.
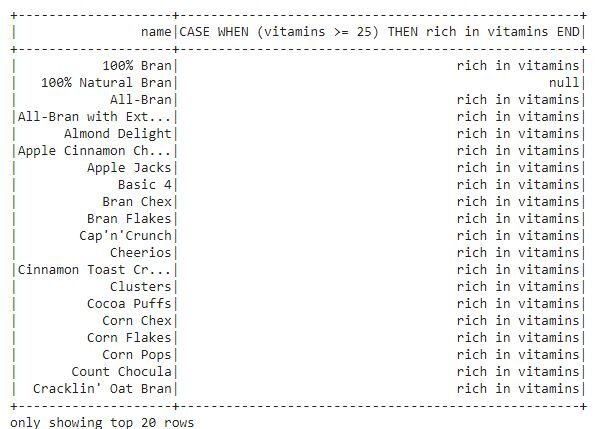
Veamos los cereales que son ricos en vitaminas.
from pyspark.sql.functions import when
df.select("name", when(df.vitamins >= "25", "rich in vitamins")).show()
- filtrar(): La función de filtro se utiliza para filtrar datos en filas según los valores de columna en particular. Por ejemplo, podemos filtrar los cereales que tienen calorías iguales a 100.
from pyspark.sql.functions import filter
df.filter(df.calories == "100").show()
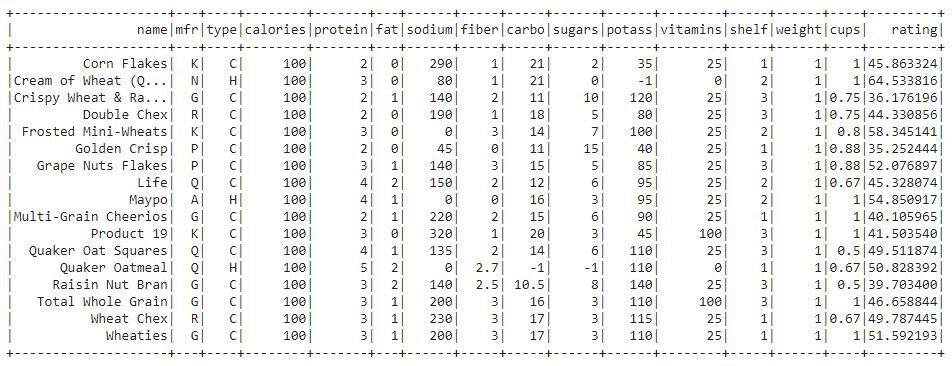
En esta salida, podemos ver que los datos se filtran según los cereales que tienen 100 calorías.
- isNull () / isNotNull (): Estas dos funciones se utilizan para averiguar si hay algún valor nulo presente en el DataFrame. Es la función más esencial para el procesamiento de datos. Es la principal herramienta utilizada para la limpieza de datos.
Averigüemos si hay algún valor nulo presente en el conjunto de datos.
#isNotNull()
from pyspark.sql.functions import * #filter data by null values df.filter(df.name.isNotNull()).show()

No hay valores nulos presentes en este conjunto de datos. Por lo tanto, se muestra todo el marco de datos.
es nulo():
df.filter(df.name.isNull()).show()
Nuevamente, no hay valores nulos. Por lo tanto, se muestra un marco de datos vacío.
En este blog, hemos discutido las 9 funciones más útiles para un procesamiento de datos eficiente. Estas funciones de PySpark son la combinación de los lenguajes Python y SQL.
Gracias por leer. Hágame saber si hay algún comentario o retroalimentación.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





