Visión general
- Aquí hay una introducción rápida a la creación de canalizaciones de aprendizaje automático con PySpark
- La capacidad de construir estas canalizaciones de aprendizaje automático es una habilidad imprescindible para cualquier aspirante a científico de datos.
- Este es un artículo práctico con un enfoque de código estructurado de PySpark, ¡así que prepare su IDE de Python favorito!
Introducción
Tómese un momento para reflexionar sobre esto: ¿cuáles son las habilidades que debe poseer un aspirante a científico de datos para obtener un puesto en la industria?
A aprendizaje automático El proyecto tiene muchos componentes móviles que deben unirse antes de que podamos ejecutarlo con éxito. La capacidad de saber cómo construir una canalización de aprendizaje automático de un extremo a otro es un activo valioso. Como científico de datos (aspirante o establecido), debe saber cómo funcionan estas canalizaciones de aprendizaje automático.
Esto es, en pocas palabras, la fusión de dos disciplinas: ciencia de datos e ingeniería de software. Estos dos van de la mano para un científico de datos. No se trata solo de construir modelos, necesitamos tener las habilidades de software para construir sistemas de nivel empresarial.

Entonces, en este artículo, nos enfocaremos en la idea básica detrás de la construcción de estas canalizaciones de aprendizaje automático usando PySpark. Este es un artículo práctico, así que inicie su IDE de Python favorito y ¡pongámonos en marcha!
Nota: Esta es la parte 2 de mi serie PySpark para principiantes. Puede consultar el artículo introductorio a continuación:
Tabla de contenido
- Realizar operaciones básicas en un marco de datos Spark
- Leer un archivo CSV
- Definiendo el esquema
- Exploración de datos usando PySpark
- Verifique las dimensiones de los datos
- Describe los datos
- Recuento de valores perdidos
- Encontrar recuento de valores únicos en una columna
- Codificar variables categóricas usandoPySpark
- Indexación de cadenas
- Una codificación en caliente
- Ensamblador de vectores
- Creación de canalizaciones de aprendizaje automático con PySpark
- Transformadores y estimadores
- Ejemplos de tuberías
Realizar operaciones básicas en un marco de datos Spark
Un paso esencial (y primer) en cualquier proyecto de ciencia de datos es comprender los datos antes de construir cualquier Aprendizaje automático modelo. La mayoría de los aspirantes a la ciencia de datos tropiezan aquí, simplemente no dedican suficiente tiempo a comprender con qué están trabajando. Hay una tendencia a apresurarse y construir modelos, una falacia que debe evitar.
Seguiremos este principio en este artículo. Seguiré un enfoque estructurado en todo momento para asegurarme de que no perdamos ningún paso crítico.
Primero, tomemos un momento y comprendamos cada variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... con la que trabajaremos aquí. Vamos a utilizar un conjunto de datos de un Partido de cricket India vs Bangladesh. Veamos las diferentes variables que tenemos en el conjunto de datos:
- Bateador: Identificación única del bateador (entero)
- Batsman_Name: Nombre del bateador (String)
- Jugador de bolos: Identificación única del jugador de bolos (entero)
- Bowler_Name: Nombre del jugador de bolos (String)
- Comentario: Descripción del evento tal como se transmitió (cadena)
- Detalle: Otra cadena que describe los eventos como ventanillas y entregas adicionales (Cadena)
- Despedido: Identificación única del bateador si se descarta (String)
- Identificación: ID de fila único (cadena)
- Isball: Si la entrega fue legal o no (booleano)
- Isboundary: Si el bateador golpeó un límite o no (binario)
- Iswicket: Si el bateador despidió o no (binario)
- Sobre: Sobre el número (Doble)
- Carreras: Se ejecuta en esa entrega en particular (entero)
- Marca de tiempo: Hora a la que se registraron los datos (marca de tiempo)
Así que comencemos, ¿de acuerdo?
Leer un archivo CSV
Cuando encendemos Spark, el SparkSession La variable está apropiadamente disponible bajo el nombre ‘Chispa – chispear‘. Podemos usar esto para leer varios tipos de archivos, como CSV, JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software..., TEXT, etc. Esto nos permite guardar los datos como un marco de datos Spark.
De forma predeterminada, considera el tipo de datos de todas las columnas como una cadena. Puede comprobar los tipos de datos utilizando el printSchema función en el marco de datos:

Definiendo el esquema
Ahora, no queremos que todas las columnas de nuestro conjunto de datos se traten como cadenas. Entonces, ¿qué podemos hacer al respecto?
Podemos definir el esquema personalizado para nuestro marco de datos en Spark. Para esto, necesitamos crear un objeto de StructType que tiene una lista de StructField. Y por supuesto, deberíamos definir StructField con un nombre de columna, el tipo de datos de la columna y si se permiten valores nulos para la columna en particular o no.
Consulte el siguiente fragmento de código para comprender cómo crear este esquema personalizado:
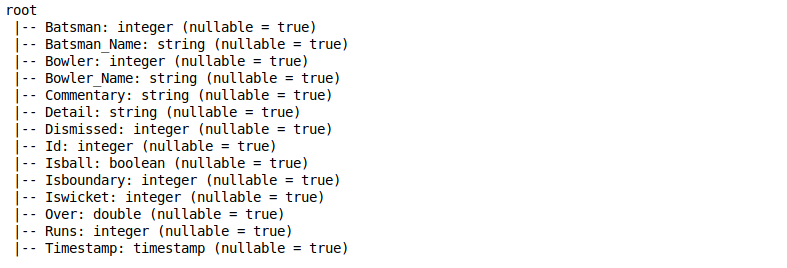
Eliminar columnas de los datos
En cualquier proyecto de aprendizaje automático, siempre tenemos algunas columnas que no son necesarias para resolver el problema. Estoy seguro de que también se ha enfrentado a este dilema antes, ya sea en la industria o en un hackathon en línea.
En nuestro caso, podemos usar la función de caída para eliminar la columna de los datos. Utilizar el asterisco

canalización de aprendizaje automático pyspark
Exploración de datos usando PySpark
Verifique las dimensiones de los datos
A diferencia de Pandas, los marcos de datos de Spark no tienen la función de forma para verificar las dimensiones de los datos. En su lugar, podemos usar el código a continuación para verificar las dimensiones del conjunto de datos:
Describe los datos Chispas describir La función nos da la mayoría de los resultados estadísticos como media, recuento, mínimo, máximo y desviación estándar. Puedes usar el resumen

canalización de aprendizaje automático pyspark
Recuento de valores perdidos
Es raro cuando obtenemos un conjunto de datos sin valores perdidos. ¿Puedes recordar la última vez que sucedió?
Es importante verificar el número de valores faltantes presentes en todas las columnas. Conocer el recuento nos ayuda a tratar los valores faltantes antes de crear cualquier modelo de aprendizaje automático con esos datos.

canalización de aprendizaje automático pyspark
Recuentos de valor de una columna A diferencia de Pandas, no tenemos la value_counts () función en los marcos de datos de Spark. Puedes usar el agrupar por
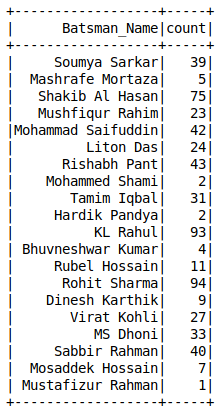
canalización de aprendizaje automático pyspark
Codificar variables categóricas usando PySpark
La mayoría de los algoritmos de aprendizaje automático aceptan los datos solo en forma numérica. Por lo tanto, es esencial convertir cualquier variable categórica presente en nuestro conjunto de datos en números.
Recuerde que no podemos simplemente eliminarlos de nuestro conjunto de datos, ya que pueden contener información útil. ¡Sería una pesadilla perder eso solo porque no queremos descubrir cómo usarlos!
Veamos algunos de los métodos para codificar variables categóricas usando PySpark.
Indexación de cadenas
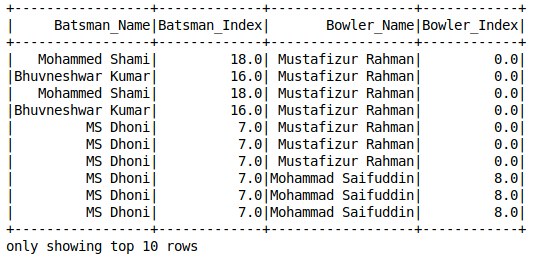
canalización de aprendizaje automático pyspark
Codificación One-Hot
La codificación one-hot es un concepto que todo científico de datos debería conocer. He confiado en él varias veces al tratar con valores perdidos. ¡Es un salvavidas! Aquí está la advertencia: Spark’s OneHotEncoder
no codifica directamente la variable categórica. Primero, necesitamos usar String Indexer para convertir la variable en forma numérica y luego usar OneHotEncoderEstimator
para codificar varias columnas del conjunto de datos.
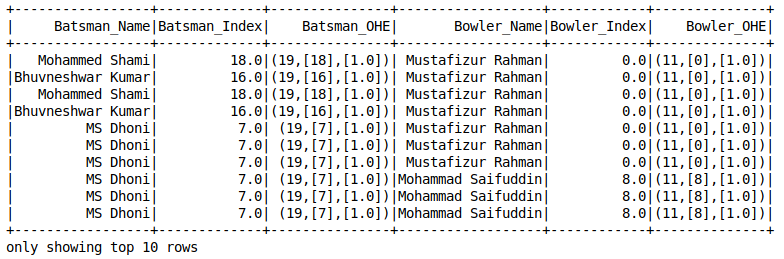
canalización de aprendizaje automático pyspark
Ensamblador de vectores
Un ensamblador de vectores combina una lista dada de columnas en una sola columna de vector.
Esto se suele utilizar al final de los pasos de exploración de datos y preprocesamiento. En esta etapa, generalmente trabajamos con algunas características sin procesar o transformadas que se pueden usar para entrenar nuestro modelo. Vector Assembler los convierte en una sola columna de características para entrenar el modelo de aprendizaje automático

canalización de aprendizaje automático pyspark
Creación de canalizaciones de aprendizaje automático con PySpark
Un proyecto de aprendizaje automático generalmente implica pasos como el preprocesamiento de datos, la extracción de características, el ajuste del modelo y la evaluación de resultados. Necesitamos realizar muchas transformaciones en los datos en secuencia. Como puede imaginar, hacer un seguimiento de ellos puede convertirse en una tarea tediosa.
Aquí es donde entran las canalizaciones de aprendizaje automático.
Un pipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, por ejemplo, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los... nos permite mantener el flujo de datos de todas las transformaciones relevantes que se requieren para alcanzar el resultado final. Necesitamos definir las etapas de la canalización que actúan como una cadena de mando para que Spark se ejecute. Aquí,
cada etapa es un transformador o un estimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos.....
Transformadores y estimadores Como el nombre sugiere, Transformadores
convierta un marco de datos en otro actualizando los valores actuales de una columna en particular (como convertir columnas categóricas en numéricas) o mapeándolo a algunos otros valores usando una lógica definida. Un estimador implementa el encajar() método en un marco de datos y produce un modelo. Por ejemplo, Regresión logística es un estimador que entrena un modelo de clasificación cuando llamamos al encajar()
método.
Entendamos esto con la ayuda de algunos ejemplos.
Ejemplos de tuberías

canalizaciones de aprendizaje automático pyspark
- Hemos creado el marco de datos. Supongamos que tenemos que transformar los datos en el siguiente orden: stage_1: Label Encode o String Index la columna
- Categoría 1 stage_2: Label Encode o String Index la columna
- categoría_2 stage_3: One-Hot Encode la columna indexada
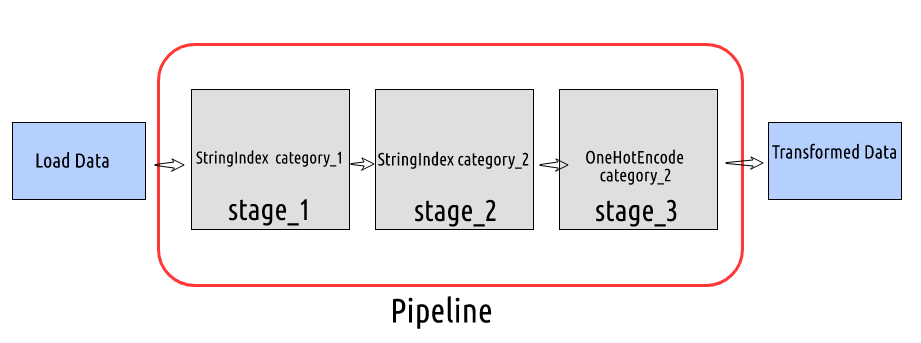
canalizaciones de aprendizaje automático pyspark En cada etapa, pasaremos el nombre de la columna de entrada y salida y configuraremos la canalización pasando las etapas definidas en la lista de Tubería
objeto.

canalizaciones de aprendizaje automático pyspark
Ahora, tomemos un ejemplo más complejo de cómo configurar una canalización. Aquí, haremos transformaciones en los datos y construiremos un modelo de regresión logística.

canalizaciones de aprendizaje automático pyspark
- Ahora, suponga que este es el orden de nuestra canalización: stage_1: Label Encode o String Index la columna
- feature_2 stage_2: Label Encode o String Index la columna
- feature_3 stage_3: One Hot Encode la columna indexada de feature_2 y
- feature_3
- stage_4: Cree un vector de todas las características necesarias para entrenar un modelo de regresión logística
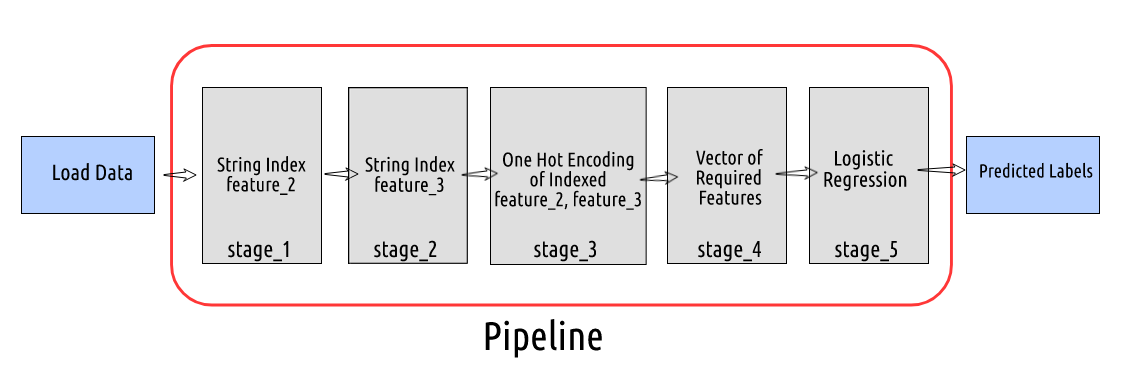
canalizaciones de aprendizaje automático pyspark
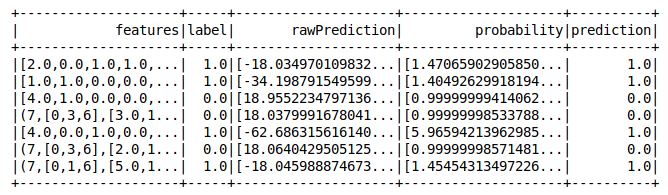
canalizaciones de aprendizaje automático pyspark
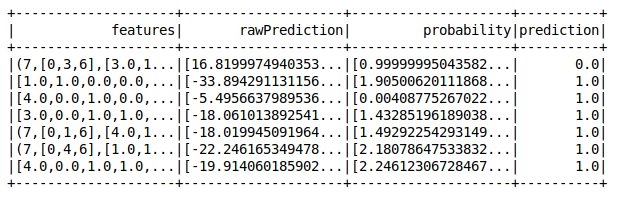
canalizaciones de aprendizaje automático pyspark
¡Perfecto!
Notas finales
Este fue un artículo breve pero intuitivo sobre cómo construir pipelines de aprendizaje automático usando PySpark. Lo reiteraré de nuevo porque es tan importante: necesita saber cómo funcionan estas tuberías. Esta es una gran parte de su papel como científico de datos.
¿Ha trabajado antes en un proyecto de aprendizaje automático de un extremo a otro? ¿O ha sido parte de un equipo que construyó estas tuberías en un entorno industrial? Conectemos en la sección de comentarios a continuación y discutamos.
Nos vemos en el próximo artículo sobre esta serie de PySpark para principiantes. ¡Feliz aprendizaje!
Relacionado





