Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Los datos están en todas partes en el mundo actual de los datos y solo podemos beneficiarnos de ellos si podemos extraer información de los datos. La visualización de datos es el aspecto más atractivo visualmente del análisis de datos porque nos permite interactuar con los datos. Es esa técnica mágica para transmitir información a grandes grupos de personas con un solo vistazo y crear historias interesantes a partir de datos. Pandas es una de las herramientas de análisis de datos más populares y ampliamente utilizadas en Python. También tiene una función de trazado incorporada para muestras. Sin embargo, cuando se trata de visualización interactiva, los usuarios de Python que no tienen habilidades de ingeniería de front-end pueden tener algunos desafíos, como muchas bibliotecas, como D3, chart.js, que requieren algunos conocimientos de JavaScript. Plotly y Gemelos son útiles en este punto.
Cuando hay una gran cantidad de datos y las empresas tienen dificultades para extraer información decisiva de ellos, la visualización de datos juega un papel importante en la toma de decisiones comerciales críticas.
Plotly es una biblioteca de gráficos construida sobre d3.js que se puede usar directamente con los marcos de datos de Pandas gracias a otra biblioteca llamada Cufflinks.
Le mostraremos cómo usar gráficos interactivos de Plotly con marcos de datos de Pandas en este tutorial rápido. Para simplificar las cosas, usaremos Jupyter Notebook (instalado usando Anaconda Distribution con Python) y el famoso conjunto de datos Titanic.
Visualización de datos en Python
Después de completar la limpieza y manipulación de datos, el siguiente paso en el proceso de análisis de datos es extraer información y conclusiones significativas de los datos, lo que se puede lograr mediante gráficos y tablas. Python tiene varias bibliotecas que se pueden usar para este propósito. Por lo general, solo se nos enseña sobre las dos bibliotecas matplotlib y seaborn. Estas bibliotecas incluyen herramientas para crear gráficos de líneas, gráficos circulares, diagramas de barras, diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... y una variedad de otros diagramas. Probablemente se esté preguntando por qué necesitamos otras bibliotecas para la visualización de datos si ya tenemos matplotlib y seaborn. Cuando escuché por primera vez sobre la trama y los gemelos, tenía la misma pregunta en mi cabeza.
Plotly
El lanzamiento más reciente de Plotly fue 5.1.0, mientras que el de gemelos fue 0.17.5. Debido a que las versiones anteriores de gemelos no son compatibles con las versiones de trazado recién lanzadas, es fundamental actualizar ambos paquetes al mismo tiempo o encontrar versiones compatibles. En Anaconda Prompt, ejecute los siguientes comandos para instalar plotly (o en Terminal si usa OS o Ubuntu)
Plotly es una biblioteca de gráficos y de código abierto que permite el trazado interactivo. Python, R, MATLAB, Arduino y REST, entre otros, se encuentran entre los lenguajes de programación compatibles con la biblioteca.
Cufflink es una biblioteca de Python que conecta plotly y pandas, lo que nos permite dibujar gráficos directamente en marcos de datos. Es esencialmente un complemento.
Los gráficos de gráficos son interactivos, lo que nos permite desplazarnos por encima de los valores, acercar y alejar los gráficos e identificar valores atípicos en el conjunto de datos. Las cartas de Matplotlib y Seaborn, por otro lado, son estáticas; no podemos acercar o alejar la imagen, y todos los valores del gráfico no están detallados. La característica más importante de Plotly es que nos permite crear gráficos web dinámicos directamente desde Python, lo que no es posible con matplotlib. También podemos hacer animaciones y gráficos interactivos a partir de datos geográficos, científicos, estadísticos y financieros utilizando plotly.
Instalar en pc «trama « y «gemelos« usando un entorno anaconda
conda install -c plotly plotly
conda install -c conda-forge cufflinks-py
o usando pip
pip install plotly --upgrade
pip install cufflinks --upgrade
Cargando Bibliotecas
Las bibliotecas Pandas, Plotly y Cufflinks se cargarán primero. Debido a que plotly es una plataforma en línea, requiere una credencial de inicio de sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... para usarla en línea. Usaremos el modo fuera de línea en este artículo, que es suficiente para Jupyter Notebook.
#importing Pandas import pandas as pd #importing plotly and cufflinks in offline mode
import cufflinks as cf import plotly.offline cf.go_offline() cf.set_config_file(offline=False, world_readable=True)
Cargando conjunto de datos
Mencionamos que usaremos el conjunto de datos Titanic, que puede obtener de este kaggle_link. Solo se utilizará el archivo train.csv.
df=pd.read_csv("train.csv")
df.head()

Histograma
Los histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... se pueden utilizar para inspeccionar las distribuciones de una característica, como la característica «Edad» en este caso. Simplemente usamos el (dataframe[“column name”]) para seleccionar una columna y luego agregar la función iplot. Como ejemplo, podemos especificar el tamaño del contenedor, el tema, el título y los nombres de los ejes. Con el comando «help (df.iplot)», puede ver todos los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... del parámetro iplot.
df["Age"].iplot(kind="histogram", bins=20, theme="white", title="Passenger's Ages",xTitle="Ages", yTitle="Count")
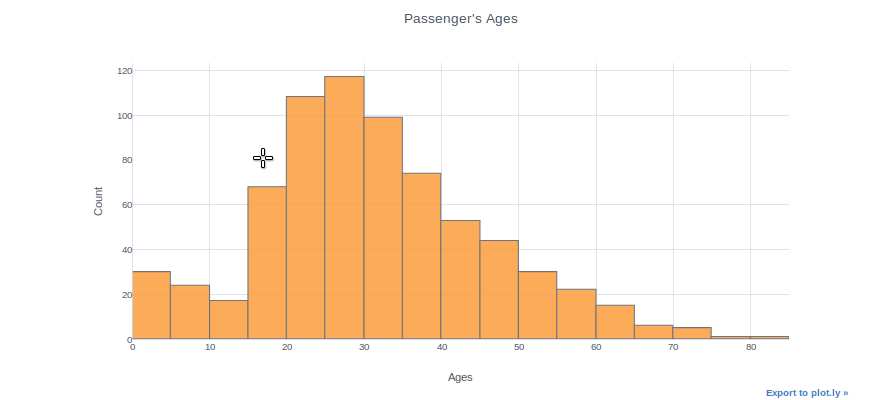
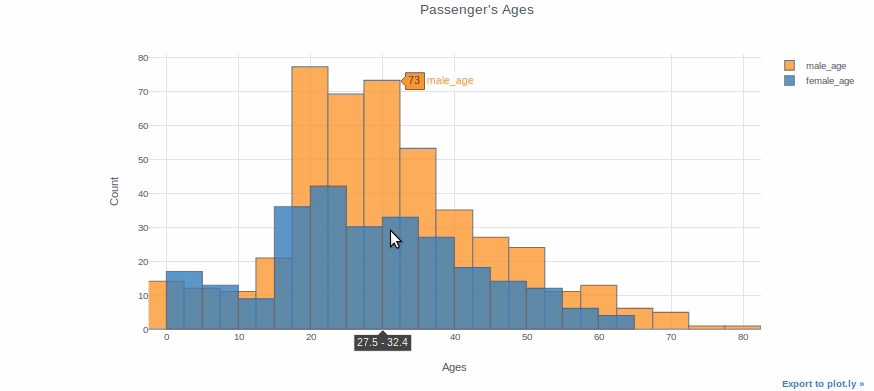
Puede trazar dos distribuciones diferentes como dos columnas diferentes si desea compararlas. Por ejemplo, trazaremos las edades de los pasajeros masculinos y femeninos en la misma parcela.
df["male_age"]=df[df["Sex"]=="male"]["Age"]
df["female_age"]=df[df["Sex"]=="female"]["Age"]df[["male_age","female_age"]].iplot(kind="histogram", bins=20, theme="white", title="Passenger's Ages",
xTitle="Ages", yTitle="Count")
Mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas....
Los mapas de calor se pueden usar para una variedad de propósitos, pero los usaremos para verificar la correlación entre características en un conjunto de datos como ejemplo.
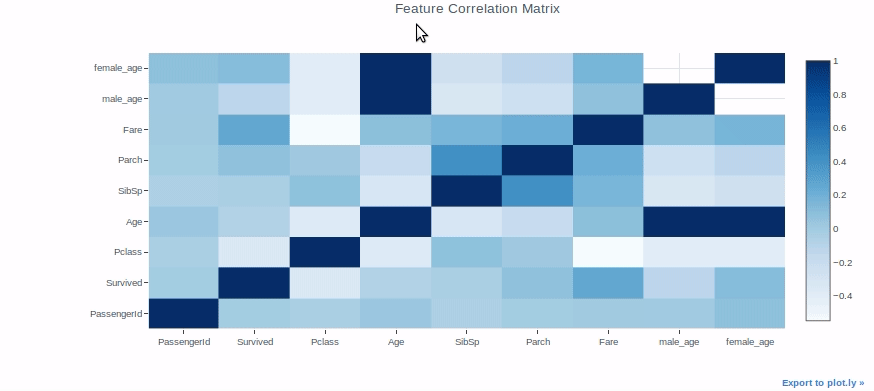
Diagrama de caja
Los diagramas de caja son extremadamente útiles para interpretar rápidamente la asimetría de los datos, los valores atípicos y los rangos de cuartiles. Ahora usaremos un diagrama de caja para mostrar la distribución de «Tarifa» para cada clase de Titanic.
#we will get help from pivot tables to get Fare values in different columns for each class. df[['Pclass', 'Fare']].pivot(columns="Pclass", values="Fare").iplot(kind='box')
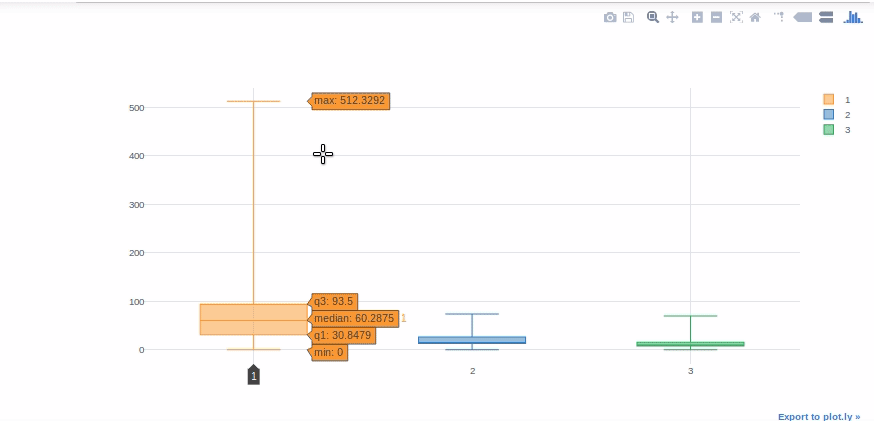
Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....
Los diagramas de dispersión se utilizan comúnmente para visualizar la relación entre dos variables numéricas. Para las variables «Tarifa» y «Edad», usaremos diagramas de dispersión. “Categorías” nos permite mostrar las variables de una característica seleccionada en varios colores (sexo de los pasajeros en este caso).
df.iplot(kind="scatter", theme="white",x="Age",y="Fare",
categories="Sex")
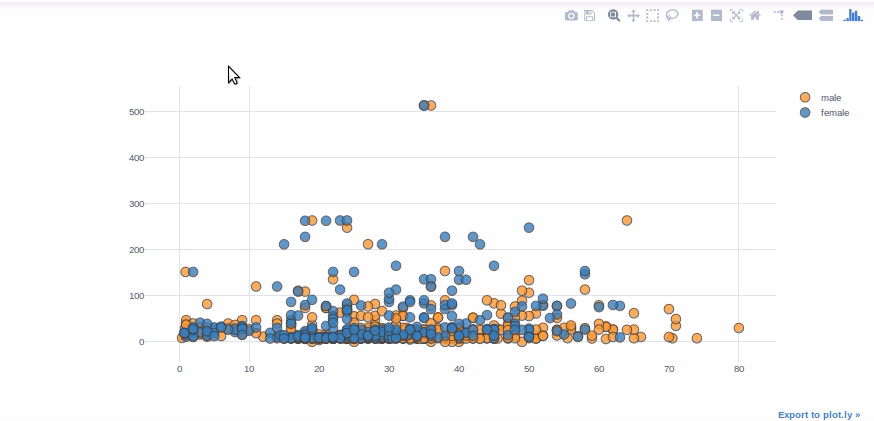
un recordatorio rápido: el parámetro «categorías» debe ser una cadena o una columna de tipo float64. Por ejemplo, en el ejemplo del gráfico de burbujas, debe convertir la columna «Sobrevivido» de tipo entero en float64 o cadena.
Gráfico de burbujas
Podemos usar gráficos de burbujas para ver múltiples relaciones de variables al mismo tiempo. Con los parámetros de «categorías» y «tamaño» en la gráfica, podemos ajustar fácilmente las subcategorías de color y tamaño. Con el parámetro «texto», también podemos especificar la columna de texto flotante.
#converting Survived column to float64 to be able to use in plotly
df[['Survived']] = df[['Survived']].astype('float64', copy=False)df.iplot(kind='bubble', x="Fare",y="Age",categories="Survived", size="Pclass", text="Name", xTitle="Fare", yTitle="Age")
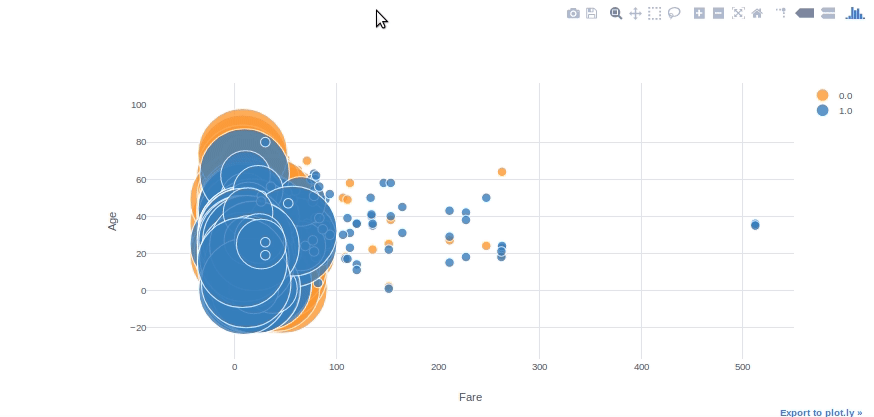
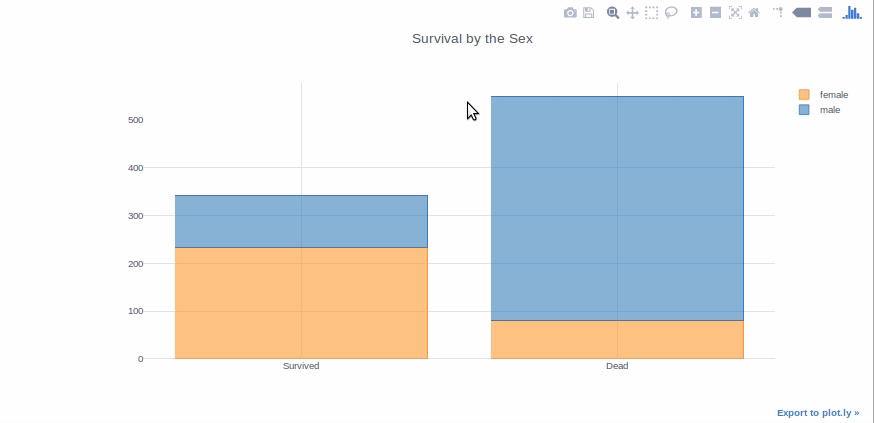
Gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad....
Los gráficos de barras son buenos para presentar los datos de diferentes grupos que se comparan entre sí. Además, se pueden usar apilados para mostrar diferentes efectos variables. Haremos un gráfico de barras para mostrar el recuento de pasajeros sobrevivientes por sexo.
survived_sex = df[df['Survived']==1]['Sex'].value_counts() dead_sex = df[df['Survived']==0]['Sex'].value_counts() df1 = pd.DataFrame([survived_sex,dead_sex]) df1.index = ['Survived','Dead'] df1.iplot(kind='bar',barmode="stack", title="Survival by the Sex")
Intenté explicar todo lo más simple posible. Espero que sea más fácil para los recién llegados entender la trama.
Plotly también proporciona gráficos científicos, gráficos 3D, mapas y animaciones. Puede visitar la documentación de plotly aquí para más detalles.
Eche un vistazo a EDA – Análisis de datos exploratorios con Python Pandas y SQL HAGA CLIC PARA LEER
EndNote
¡Gracias por leer!
Espero que haya disfrutado del artículo y haya aumentado sus conocimientos.
Por favor no dude en ponerse en contacto conmigo sobre Correo electrónico
¿Algo no mencionado o quieres compartir tus pensamientos? No dude en comentar a continuación y me pondré en contacto con usted.
Sobre el Autor
Hardikkumar M. Dhaduk
Analista de datos | Especialista en análisis de datos digitales | Estudiante de ciencia de datos
Conéctate conmigo en Linkedin
Conéctate conmigo en Github
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





