Introducción
Por alguna razón, los problemas de regresión y clasificación acaban acaparando la mayor parte de la atención en el mundo del aprendizaje automático. La gente no se da cuenta de la amplia variedad de problemas de aprendizaje automático que pueden existir.
A mí, por otro lado, me encanta explorar diferentes tipos de problemas y compartir mi aprendizaje con la comunidad aquí.
Anteriormente, compartí mis aprendizajes sobre algoritmos genéticos con la comunidad. Continuando con mi búsqueda, tengo la intención de cubrir un tema que tiene un problema mucho menos extendido pero que es un problema persistente en la comunidad de ciencia de datos, que es la clasificación de múltiples etiquetas.
En este artículo, le daré una explicación intuitiva de lo que implica la clasificación de etiquetas múltiples, junto con una ilustración de cómo resolver el problema. Espero que les muestre el horizonte de lo que abarca la ciencia de datos. ¡Así que sigamos adelante!
Tabla de contenido
- ¿Qué es la clasificación de etiquetas múltiples?
- Multi-Class v / s Multi-Label
- Carga y generación de conjuntos de datos de etiquetas múltiples
- Técnicas para resolver un problema de clasificación de etiquetas múltiples
- Método de transformación de problemas
- Método de algoritmo adaptado
- Enfoques de conjunto
- Estudios de caso
1. ¿Qué es la clasificación de etiquetas múltiples?
Echemos un vistazo a la imagen de abajo.

¿Y si te pregunto si esta imagen contiene una casa? La opcion sera SÍ o NO.
Considere otro caso, como qué todas las cosas (o etiquetas) son relevantes para esta imagen.

Este tipo de problemas, donde tenemos un conjunto de variables objetivo, se conocen como clasificación de etiquetas múltiples problemas. Entonces, ¿hay alguna diferencia entre estos dos casos? Claramente, sí, porque en el segundo caso cualquier imagen puede contener un conjunto diferente de estas múltiples etiquetas para diferentes imágenes.
Pero antes de profundizar en las múltiples etiquetas, solo quería aclarar una cosa, ya que muchos de ustedes podrían estar confundidos acerca de en qué se diferencia esto del problema de las múltiples clases.
Entonces, intentemos comprender la diferencia entre estos dos conjuntos de problemas.
2. Multi-etiqueta v / s multi-clase
Considere un ejemplo para comprender la diferencia entre estos dos. Para ello, espero que la imagen de abajo deje las cosas bastante claras. Tratemos de entenderlo.
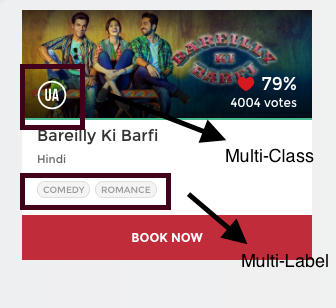
Para cualquier película, la Junta Central de Certificación de Películas, emite un certificado según el contenido de la película.
Por ejemplo, si miras arriba, esta película ha sido calificada como ‘U / A’ (que significa ‘supervisión de los padres para niños menores de 12 años’) certificado. Hay otros tipos de clases de certificados como ‘A’ (Restringido a adultos) o ‘U’ (Exposición pública sin restricciones), pero es seguro que cada película solo se puede categorizar con solo uno de esos tres tipos de certificados.
En resumen, hay múltiples categorías pero a cada instancia se le asigna una sola, por lo tanto, estos problemas se conocen como clasificación de clases múltiples problema.
Nuevamente, si miras hacia atrás en la imagen, esta película ha sido categorizada en género de comedia y romance. Pero hay una diferencia en que esta vez cada película podría caer en uno o más conjuntos de categorías diferentes.
Por lo tanto, a cada instancia se le pueden asignar múltiples categorías, por lo que estos tipos de problemas se conocen como clasificación de etiquetas múltiples problema, donde tenemos un conjunto de etiquetas de destino.
¡Excelente! Ahora puede distinguir entre un problema de varias etiquetas y de clases múltiples. Entonces, comencemos a lidiar con este tipo de problemas.
3. Carga y generación de conjuntos de datos de etiquetas múltiples
Scikit-learn ha proporcionado una biblioteca separada scikit-multilearn para clasificación de etiquetas múltiples.
Para una mejor comprensión, comencemos a practicar con un conjunto de datos de múltiples etiquetas. Puede encontrar un conjunto de datos del mundo real en el repositorio proporcionado por el paquete MULAN. Estos conjuntos de datos están presentes en formato ARFF.
Entonces, para comenzar con cualquiera de estos conjuntos de datos, mire el código de Python a continuación para cargarlo en su cuaderno jupyter. Aquí he descargado el conjunto de datos de levadura del repositorio.
import scipy
from scipy.io import arff
data, meta = scipy.io.arff.loadarff('/Users/shubhamjain/Documents/yeast/yeast-train.arff')
df = pd.DataFrame(data)
Así es como se ve el conjunto de datos.
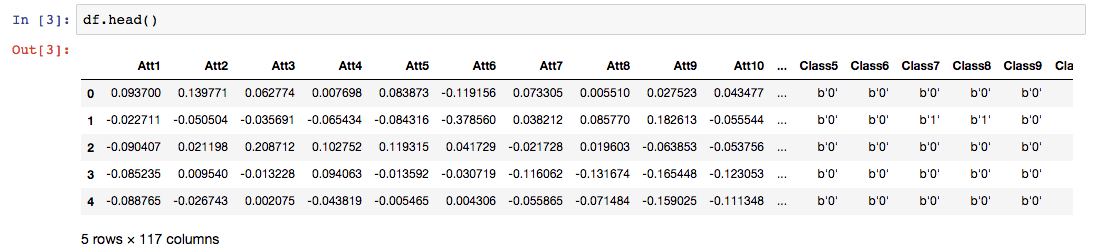
Aquí, Att representa los atributos o las variables independientes y Clase representa las variables de destino.
Para fines prácticos, tenemos otra opción para generar un conjunto de datos de etiquetas múltiples artificiales.
from sklearn.datasets import make_multilabel_classification # this will generate a random multi-label dataset X, y = make_multilabel_classification(sparse = True, n_labels = 20, return_indicator="sparse", allow_unlabeled = False)
Entendamos los parámetros utilizados anteriormente.
escaso: Si es Verdadero, devuelve una matriz dispersa, donde matriz dispersa significa una matriz que tiene una gran cantidad de elementos cero.
n_labels: El número medio de etiquetas de cada instancia.
return_indicator: Si ‘escaso’ regreso Y en el formato de indicador binario disperso.
allow_unlaoted: Si Cierto, es posible que algunas instancias no pertenezcan a ninguna clase.
Debe haber notado que hemos usado una matriz dispersa en todas partes, y scikit-multilearn también recomienda usar datos en forma dispersa porque es muy raro que un conjunto de datos del mundo real sea denso. Generalmente, el número de etiquetas asignadas a cada instancia es muy inferior.
Bien, ahora tenemos nuestros conjuntos de datos listos, así que aprendamos rápidamente las técnicas para resolver un problema de múltiples etiquetas.
4. Técnicas para resolver un problema de clasificación de etiquetas múltiples
Básicamente, existen tres métodos para resolver un problema de clasificación de etiquetas múltiples, a saber:
- Transformación de problemas
- Algoritmo adaptado
- Enfoques de conjunto
4.1 Transformación de problemas
En este método, intentaremos transformar nuestro problema de etiquetas múltiples en problemas de etiqueta única.
Este método se puede realizar de tres formas diferentes como:
- Relevancia binaria
- Cadenas clasificadoras
- Etiqueta Powerset
4.1.1 Relevancia binaria
Esta es la técnica más simple, que básicamente trata cada etiqueta como un problema de clasificación de una sola clase por separado.
Por ejemplo, consideremos un caso como se muestra a continuación. Tenemos el conjunto de datos como este, donde X es la característica independiente e Y es la variable objetivo.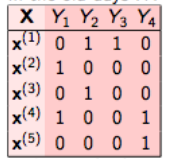
En relevancia binaria, este problema se divide en 4 problemas de clasificación de clase única diferentes, como se muestra en la figura siguiente.
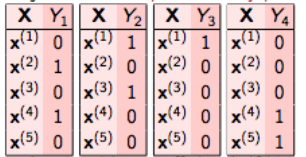
No tenemos que hacer esto manualmente, la biblioteca de aprendizaje múltiple proporciona su implementación en Python. Entonces, veamos rápidamente su implementación en los datos generados aleatoriamente.
# using binary relevance from skmultilearn.problem_transform import BinaryRelevance from sklearn.naive_bayes import GaussianNB # initialize binary relevance multi-label classifier # with a gaussian naive bayes base classifier classifier = BinaryRelevance(GaussianNB()) # train classifier.fit(X_train, y_train) # predict predictions = classifier.predict(X_test)
NOTA: Aquí, hemos utilizado el algoritmo Naive Bayes, pero puede utilizar cualquier otro algoritmo de clasificación.
Ahora, en un problema de clasificación de etiquetas múltiples, no podemos simplemente usar nuestras métricas normales para calcular la precisión de nuestras predicciones. Para ese propósito, usaremos puntuación de precisión métrico. Esta función calcula la precisión del subconjunto, lo que significa que el conjunto predicho de etiquetas debe coincidir exactamente con el verdadero conjunto de etiquetas.
Entonces, calculemos la precisión de las predicciones.
from sklearn.metrics import accuracy_score accuracy_score(y_test,predictions)
Por tanto, hemos obtenido una puntuación de precisión de 45%, que no está tan mal. Veamos rápidamente sus pros y contras.
Es el método más simple y eficiente, pero el único inconveniente de este método es que no considera la correlación de etiquetas porque trata cada variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de destino de forma independiente.
4.1.2 Cadenas clasificadoras
En esto, el primer clasificador se entrena solo en los datos de entrada y luego cada clasificador siguiente se entrena en el espacio de entrada y todos los clasificadores anteriores en la cadena.
Intentemos entender esto con un ejemplo. En el conjunto de datos que se muestra a continuación, tenemos X como espacio de entrada e Y como etiquetas.
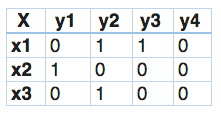
En las cadenas de clasificadores, este problema se transformaría en 4 problemas de etiqueta única diferentes, como se muestra a continuación. Aquí el color amarillo es el espacio de entrada y la parte blanca representa la variable de destino.

Esto es bastante similar a la relevancia binaria, la única diferencia es que forma cadenas para preservar la correlación de etiquetas. Entonces, intentemos implementar esto usando la biblioteca de aprendizaje múltiple.
# using classifier chains from skmultilearn.problem_transform import ClassifierChain from sklearn.naive_bayes import GaussianNB # initialize classifier chains multi-label classifier # with a gaussian naive bayes base classifier classifier = ClassifierChain(GaussianNB()) # train classifier.fit(X_train, y_train) # predict predictions = classifier.predict(X_test) accuracy_score(y_test,predictions)
0.21212121212121213
Podemos ver que usando esto obtuvimos una precisión de aproximadamente 21%, que es muy inferior al binario Relevancia. Esto quizás se deba a la ausencia de correlación de etiquetas, ya que hemos generado los datos de forma aleatoria.
4.1.3 Etiqueta Powerset
En esto, transformamos el problema en un problema de clases múltiples con un clasificador de clases múltiples entrenado en todas las combinaciones de etiquetas únicas que se encuentran en los datos de entrenamiento.
Entendamos con un ejemplo.
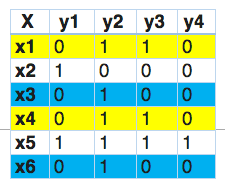
En esto, encontramos que x1 y x4 tienen las mismas etiquetas, de manera similar, x3 y x6 tienen el mismo conjunto de etiquetas. Por lo tanto, el conjunto de alimentación de etiquetas transforma este problema en un solo problema de varias clases, como se muestra a continuación.
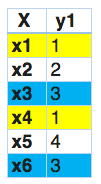
Por lo tanto, label powerset ha otorgado una clase única a cada combinación de etiquetas posible que está presente en el conjunto de entrenamiento.
Veamos su implementación en Python.
# using Label Powerset from skmultilearn.problem_transform import LabelPowerset from sklearn.naive_bayes import GaussianNB # initialize Label Powerset multi-label classifier # with a gaussian naive bayes base classifier classifier = LabelPowerset(GaussianNB()) # train classifier.fit(X_train, y_train) # predict predictions = classifier.predict(X_test) accuracy_score(y_test,predictions)
0.5757575757575758
Esto nos da la mayor precisión entre los tres que hemos discutido hasta ahora. La única desventaja de esto es que a medida que aumentan los datos de entrenamiento, aumenta el número de clases. Por lo tanto, aumenta la complejidad del modelo y daría lugar a una menor precisión.
Ahora, veamos el segundo método para resolver el problema de clasificación de múltiples etiquetas.
4.2 Algoritmo adaptado
Algoritmo adaptado, como su nombre indica, adaptando el algoritmo para realizar directamente la clasificación de múltiples etiquetas, en lugar de transformar el problema en diferentes subconjuntos de problemas.
Por ejemplo, la versión de múltiples etiquetas de kNN está representada por MLkNN. Entonces, implementemos esto rápidamente en nuestro conjunto de datos generados aleatoriamente.
from skmultilearn.adapt import MLkNN classifier = MLkNN(k=20) # train classifier.fit(X_train, y_train) # predict predictions = classifier.predict(X_test) accuracy_score(y_test,predictions)
0.69
¡Excelente! Ha logrado una puntuación de precisión de 69% en sus datos de prueba.
Sci-kit learn proporciona soporte incorporado de clasificación de etiquetas múltiples en algunos de los algoritmos como la regresión de Random Forest y Ridge. Por lo tanto, puede llamarlos directamente y predecir la salida.
Puedes consultar el biblioteca de aprendizaje múltiple si desea obtener más información sobre otros tipos de algoritmos adaptados.
4.3 Enfoques por conjuntos
Ensemble siempre produce mejores resultados. La biblioteca Scikit-Multilearn proporciona diferentes funciones de clasificación de conjuntos, que puede utilizar para obtener mejores resultados.
Para la implementación directa, puede consultar aquí.
5. Estudios de casos
Los problemas de clasificación de etiquetas múltiples son muy comunes en el mundo real. Entonces, echemos un vistazo a algunas de las áreas en las que podemos encontrar el uso de ellos.
1. Categorización de audio
Ya hemos visto canciones clasificadas en diferentes géneros. También se clasifican sobre la base de emociones o estados de ánimo como «calma relajante», «tristeza-soledad», etc.
Fuente: Enlace
2. Categorización de imágenes
La clasificación de etiquetas múltiples utilizando imágenes también tiene una amplia gama de aplicaciones. Las imágenes se pueden etiquetar para indicar diferentes objetos, personas o conceptos.

3. Bioinformática
La clasificación de etiquetas múltiples tiene mucho uso en el campo de la bioinformática, por ejemplo, la clasificación de genes en el conjunto de datos de levadura.
También se utiliza para predecir múltiples funciones de proteínas utilizando varias proteínas no marcadas. Puedes comprobar esto papel para más información.
4. Categorización del texto
Todos deben consultar una vez las noticias de Google. Entonces, lo que hace Google News es etiquetar todas las noticias en una o más categorías de modo que se muestren en diferentes categorías. Por ejemplo, mire la imagen a continuación.
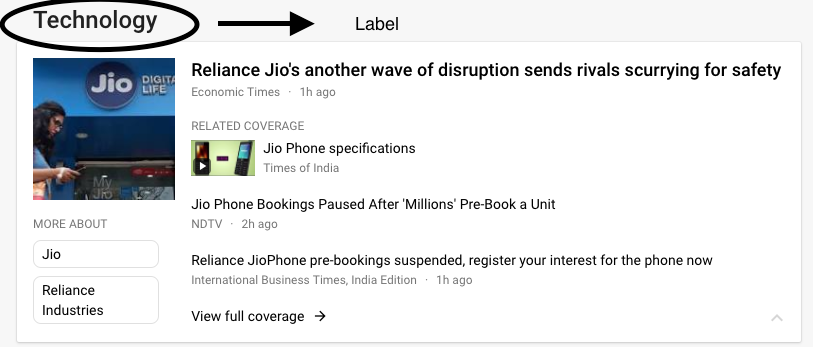
Fuente de imagen: Noticias de Google
Esa misma noticia está presente en las categorías de India, Tecnología, Últimas, etc. porque ha sido clasificada en estas diferentes etiquetas. Por lo tanto, es un problema de clasificación de etiquetas múltiples.
Hay muchas otras áreas, así que explore y comente a continuación si desea compartirlo con la comunidad.
6. Notas finales
En este artículo, le presenté el concepto de problemas de clasificación de etiquetas múltiples. También he cubierto los enfoques para resolver este problema y los casos de uso práctico en los que es posible que deba manejarlo utilizando la biblioteca de aprendizaje múltiple en Python.
Espero que este artículo le dé una ventaja cuando se enfrente a este tipo de problemas. Si tiene alguna duda / sugerencia, ¡no dude en comunicarse conmigo a continuación!





