Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
En este artículo, aprenderemos cómo una de las técnicas de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... utilizadas para encontrar la precisión de Conjunto de datos de cáncer de mama, pero sé que la mayoría de los técnicos no saben de qué estamos hablando, comenzaremos desde lo fundamental y luego avanzaremos hacia nuestro tema. En primer lugar, haremos una breve introducción al aprendizaje profundo y luego, ¿qué es la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... artificial?
¿Qué es el aprendizaje profundo?
Si hablamos de aprendizaje profundo, simplemente comprenda que es un subconjunto o una subparte del aprendizaje automático. Podemos decir que el aprendizaje profundo es una función de IA que imita el cerebro humano y procesa esos datos y crea patrones para usar en la toma de decisiones.
El aprendizaje profundo es el tipo de aprendizaje automático que es algo así como el cerebro humano. Utiliza una estructura de algoritmos de varias capas llamadas redes neuronales. Sus algoritmos intentan copiar los datos que los humanos estarían analizando con una estructura lógica determinada. También se conoce como red neuronal profunda o aprendizaje neuronal profundo.
En el aprendizaje profundo hay un concepto llamado Red neuronal artificial que discutiremos brevemente a continuación:
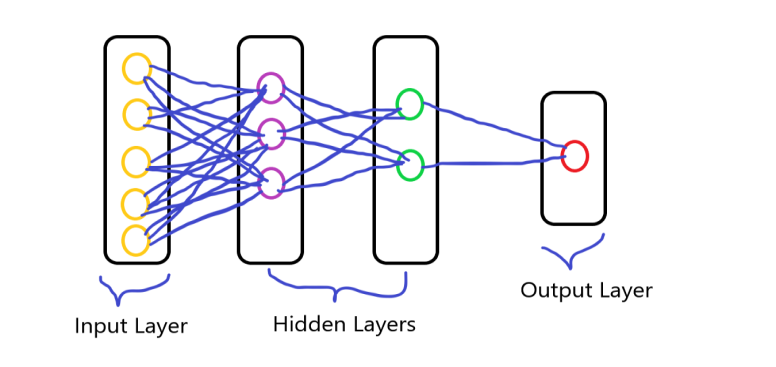
Red neuronal artificial
Como su nombre indica red neuronal artificial, es la red de neuronas artificiales. Se refiere a un modelo inspirado biológicamente en el cerebro. Podemos decir que suele ser una red computacional basada en redes neuronales biológicas que construyen la estructura del cerebro humano.
Todos ustedes saben que las neuronas están interconectadas entre sí en nuestro cerebro y el proceso de transmisión de datos. Es similar a las neuronas del cerebro humano que están interconectadas entre sí, la red neuronal consta de una gran cantidad de neuronas artificiales, que se denominan unidades dispuestas en una secuencia de capas. teniendo las diversas capas de las neuronas y formando una red completa. estas neuronas se denominan nodos.
Consiste en tres capas que es:
- Capa de entradaLa "capa de entrada" se refiere al nivel inicial en un proceso de análisis de datos o en arquitecturas de redes neuronales. Su función principal es recibir y procesar la información bruta antes de que esta sea transformada por capas posteriores. En el contexto de machine learning, una adecuada configuración de la capa de entrada es crucial para garantizar la efectividad del modelo y optimizar su rendimiento en tareas específicas....
- Capa oculta
- Capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados....
Crear ANN utilizando un conjunto de datos de cáncer de mama
Ahora pasamos a nuestro tema, aquí tomaremos el conjunto de datos y luego crearemos la red neuronal artificial y clasificaremos el diagnóstico, primero, tomamos un conjunto de datos del cáncer de mama y luego avanzamos.
Conjunto de datos: Conjunto de datos de cáncer de mama
Después de descargar el conjunto de datos, importaremos las bibliotecas importantes que se requieren para el proceso posterior.
Importar bibliotecas
#import pandas import pandas as pd #import numpy import numpy as np import matplotlib.pyplot as plt import seaborn as sb
Aquí importamos pandas, NumPy y algunas bibliotecas de visualización.
Ahora cargamos nuestro conjunto de datos usando pandas:
df = pd.read_csv('Breast_cancer.csv')
df
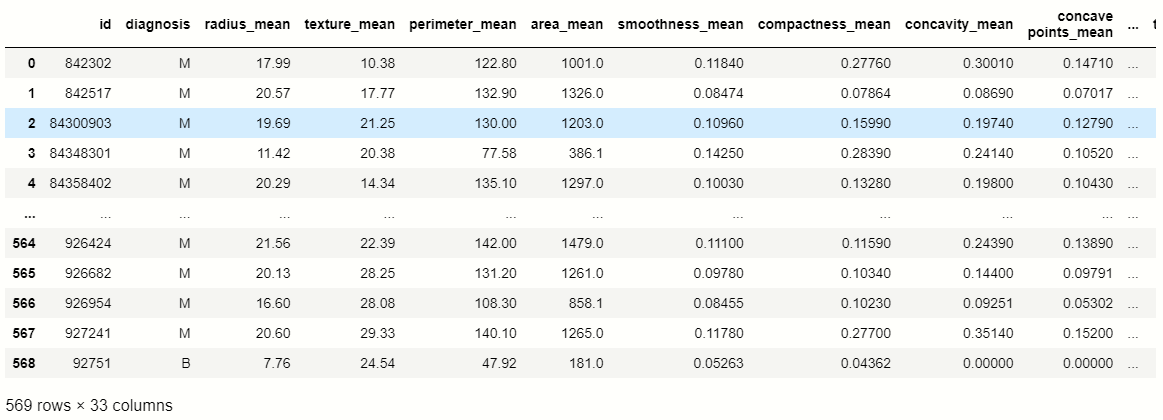
En este conjunto de datos, apuntamos a la ‘diagnóstico’ columna de características, por lo que verificamos el recuento de valores de esa columna usando pandas:
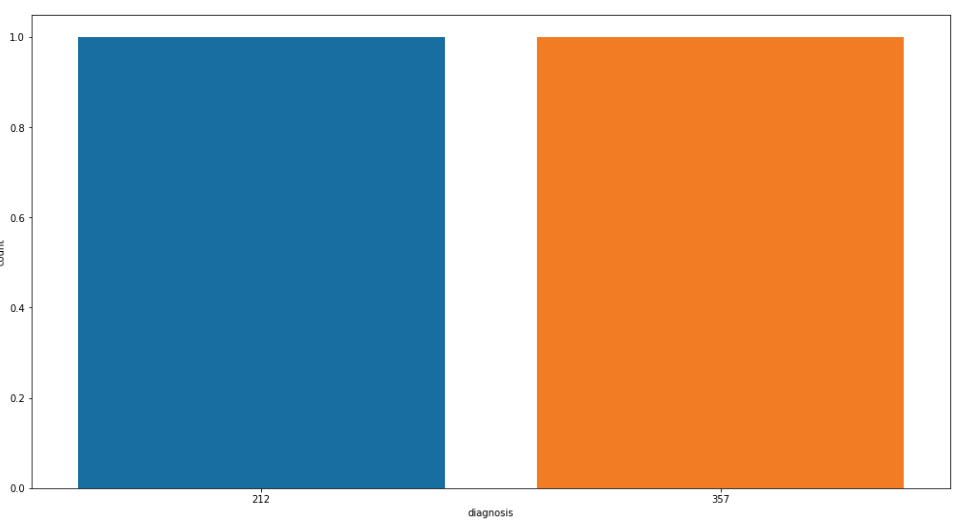
# counting values of variables in 'diagnosis' df['diagnosis'].value_counts()

Ahora visualizamos los recuentos de valores de las ‘columnas de diagnóstico: para una mejor comprensión
Visualizar cuentas de valor
plt.figure(figsize=[17,9]) sb.countplot(df['diagnosis'].value_counts()) plt.show()
Valores nulos
En el conjunto de datos, tenemos que verificar los valores nulos que están presentes dentro de las variables para las que usamos pandas:
df.isnull().sum()
Después de ejecutar el programa, llegamos a la conclusión de que el nombre de la función ‘Sin nombre: 32’ contiene todos los valores nulos, por lo que eliminamos o descartamos esa columna.
#droping feature df.drop(['Unnamed: 32','id'],axis=1,inplace=True)
Variables independientes y dependientes
Ahora es el momento de dividir el conjunto de datos en variables independientes y dependientes, para eso creamos dos variables, una representa independiente y la otra representa dependiente.
# independent variables
x = df.drop('diagnosis',axis=1)
#dependent variables
y = df.diagnosis
Manejo del valor categórico
Cuando imprimimos la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente y luego vemos que contienen datos categóricos y tenemos que convertir datos categóricos al formato binario para un proceso posterior. Por lo tanto, usamos Scikit learn Label Encoder para codificar los datos categóricos.
from sklearn.preprocessing import LabelEncoder #creating the object lb = LabelEncoder() y = lb.fit_transform(y)
División de datos
Ahora es el momento de dividir los datos en partes de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y prueba:
from sklearn.model_selection import train_test_split xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3,random_state=40)
Escalar los datos
Cuando creamos la red neuronal artificial, tenemos que escalar los datos a números más pequeños porque el algoritmo de aprendizaje profundo multiplica los pesos y los datos de entrada de los nodos y lleva mucho tiempo, por lo que para reducir ese tiempo escalamos los datos.
Para escalar, usamos el scikit learn Escalador estándar módulo, escalamos el conjunto de datos de entrenamiento y prueba:
#importing StandardScaler from sklearn.preprocessing import StandardScaler #creating object sc = StandardScaler() xtrain = sc.fit_transform(xtrain) xtest = sc.transform(xtest)
A partir de aquí comenzamos a crear la red neuronal artificial, para eso importamos las bibliotecas importantes que se utilizan para crear ANN:
#importing keras import keras #importing sequential module from keras.models import Sequential # import dense module for hidden layers from keras.layers import Dense #importing activation functions from keras.layers import LeakyReLU,PReLU,ELU from keras.layers import Dropout
Creando Capas
Después de importar esas bibliotecas, creamos los tres tipos de capas:
- Capa de entrada
- Capa oculta
- Capa de salida
Primero, creamos el modelo:
#creating model classifier = Sequential()
A secuencial El modelo es apropiado para una pila simple de capas donde cada capa tiene exactamente un tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos.... de entrada y un tensor de salida.
Ahora creamos las capas de la red neuronal:
#first hidden layer classifier.add(Dense(units=9,kernel_initializer="he_uniform",activation='relu',input_dim=30)) #second hidden layer classifier.add(Dense(units=9,kernel_initializer="he_uniform",activation='relu')) # last layer or output layer classifier.add(Dense(units=1,kernel_initializer="glorot_uniform",activation='sigmoid'))
En el siguiente código, se usa el método Dense para crear las capas, en el que usamos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... fundamentales. El primer parámetro es Nodos de salida, el El segundo es el inicializador para la matriz de ponderaciones del núcleo, el tercero es la función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.... y el último parámetro son los nodos de entrada o el número de características independientes.
Después de ejecutar este código tomamos el resumen del mismo usando:
#taking summary of layers
classifier.summary()

Compilando ANN
Ahora compilamos nuestro modelo con el optimizador:
#compiling the ANN classifier.compile(optimizer="adam",loss="binary_crossentropy",metrics=['accuracy'])
Adaptación de la ANN a los datos de entrenamiento
Después de compilar el modelo, tenemos que ajustar la ANN en los datos de entrenamiento para la predicción:
#fitting the ANN to the training set model = classifier.fit(xtrain,ytrain,batch_size=100,epochs=100)

los encajar() El método ajusta la ANN a los datos de entrenamiento, en los parámetros establecemos los valores específicos de cada variable como tamaño de lote, épocas, etc. Por fin, encontramos una puntuación de precisión excelente, por lo que nuestro modelo se adapta perfectamente a los datos de entrenamiento.
Después de entrenar los datos, también tenemos que probar la puntuación de precisión de los datos de la prueba, veamos a continuación:
#now testing for Test data y_pred = classifier.predict(test)
Al ejecutar este código, encontramos que y_pred contenía los diferentes valores, por lo que convertimos los valores de predicción en valores de umbral como Verdadero, Falso.
#converting values y_pred = (y_pred>0.5) print(y_pred)

Matriz de puntuación y confusión
Ahora verificamos la matriz de confusión y la puntuación de los valores predichos.
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
cm = confusion_matrix(ytest,y_pred)
score = accuracy_score(ytest,y_pred)
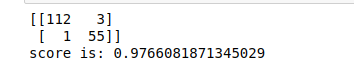
print(cm)
print('score is:',score)
Producción:-
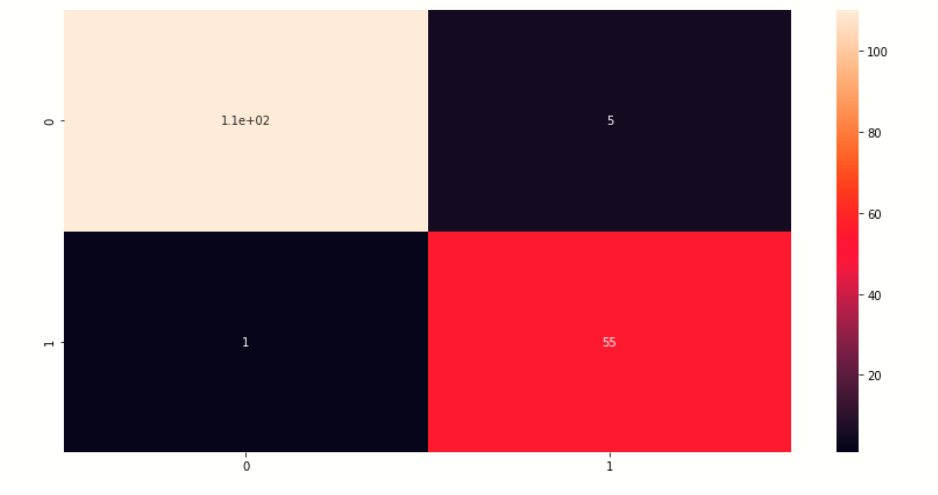
Visualizar matriz de confusión
Aquí visualizamos la matriz de confusión de los valores de predicción.
# creating heatmap of comfussion matrix plt.figure(figsize=[14,7]) sb.heatmap(cm,annot=True) plt.show()
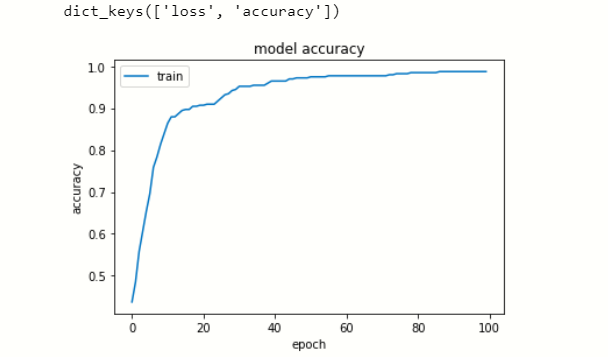
Visualizar el historial de datos
Ahora visualizamos la pérdida y precisión en cada época.
# list all data in history
print(model.history.keys())
# summarize history for accuracy
plt.plot(model.history['accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc="upper left")
plt.show()
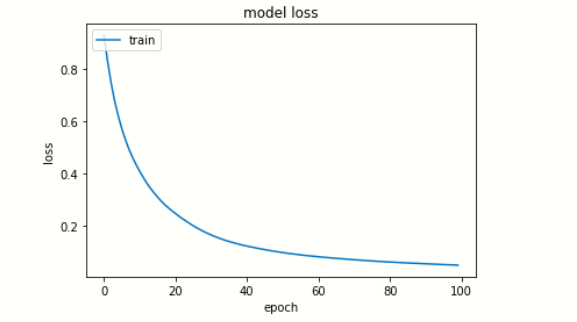
# summarize history for loss
plt.plot(model.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc="upper left")
plt.show()
Modelo de ahorro
Por fin, salvamos nuestro modelo.
#saving the model
classifier.save('File_name.h5')
EndNote
Esta es mi primera ANN creada en aprendizaje profundo, soy un principiante en aprendizaje profundo. Hago todo lo posible para explicar este artículo, espero que les guste. Gracias por leer este artículo.
Conéctese conmigo en LinkedIn: Perfil
Gracias.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





