Introducción
El procesamiento del lenguaje natural (PNL) es un área de creciente atención debido al creciente número de aplicaciones como chatbots, traducción automática, etc. De alguna manera, toda la revolución de las máquinas inteligentes se basa en la capacidad de comprender e interactuar con los humanos.
He estado explorando la PNL desde hace algún tiempo. Mi viaje comenzó con la biblioteca NLTK en Python, que era la biblioteca recomendada para comenzar en ese momento. NLTK es una biblioteca perfecta para la educación y la investigación, se vuelve muy pesada y tediosa para completar incluso las tareas más simples.
Más tarde, me presentaron a TextBlob, que se basa en NLTK y Pattern. Una gran ventaja de esto es que es fácil de aprender y ofrece muchas características como análisis de sentimientos, etiquetado pos, extracción de frases nominales, etc. Ahora se ha convertido en mi biblioteca de referencia para realizar tareas de PNL.
En una nota al margenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial..., hay espacio, que es ampliamente reconocido como una de las bibliotecas poderosas y avanzadas que se utilizan para implementar tareas de PNL. Pero habiendo encontrado tanto spacy como TextBlob, todavía sugeriría TextBlob a un principiante debido a su interfaz simple.
Si es su primer paso en la PNL, TextBlob es la biblioteca perfecta para que la practique. La mejor manera de leer este artículo es seguir el código y realizar las tareas usted mismo. ¡Entonces empecemos!
Nota : Este artículo no describe las tareas de PNL en profundidad. Si desea revisar los conceptos básicos y volver aquí, siempre puede leer este artículo.
Tabla de contenido
- ¿Acerca de TextBlob?
- Configurar el sistema
- Prueba las tareas de PNL con TextBlob
- Tokenización
- Extracción de frases sustantivas
- POS-etiquetado
- Inflexión y lematización de palabras
- N-gramos
- Análisis de los sentimientos
- Otras cosas interesantes que hacer con TextBlob
- Corrección ortográfica
- Crear un breve resumen de un texto
- Traducción y detección de idiomas
- Clasificación de texto usando TextBlob
- Pros y contras
- Notas finales
1. ¿Acerca de TextBlob?
TextBlob es una biblioteca de Python y ofrece una API simple para acceder a sus métodos y realizar tareas básicas de PNL.
Lo bueno de TextBlob es que son como cadenas de python. Entonces, puedes transformarlo y jugar con él de la misma manera que lo hicimos en Python. A continuación, le he mostrado a continuación algunas tareas básicas. No se preocupe por la sintaxis, es solo para darle una idea de qué tan relacionado está TextBlob con las cadenas de Python.
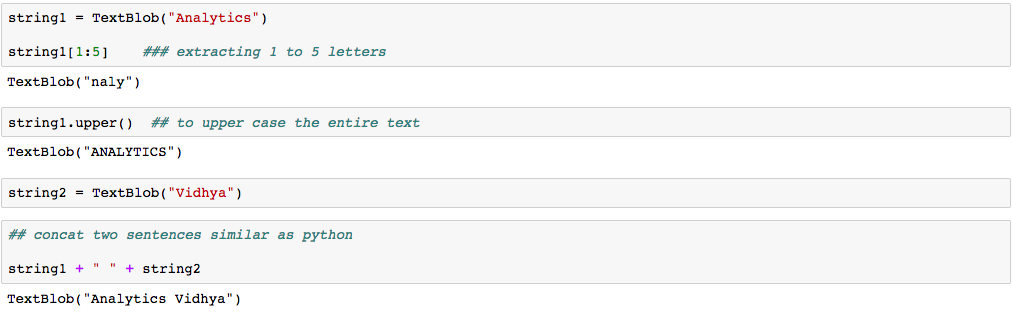 Entonces, para realizar estas cosas por su cuenta, instalemos rápidamente y comencemos a codificar.
Entonces, para realizar estas cosas por su cuenta, instalemos rápidamente y comencemos a codificar.
2. Configuración del sistema
Instalación de TextBlob en su sistema en una tarea simple, todo lo que necesita hacer es abrir el indicador anaconda (o terminal si usa Mac OS o Ubuntu) e ingresar los siguientes comandos:
pip install -U textblob
Esto instalará TextBlob. Para los no iniciados: el trabajo práctico en el procesamiento del lenguaje natural generalmente utiliza grandes cantidades de datos lingüísticos, o corpora. Para descargar los corpus necesarios, puede ejecutar el siguiente comando
python -m textblob.download_corpora
3. Tareas de PNL con TextBlob
3.1 Tokenización
La tokenización se refiere a dividir texto o una oración en una secuencia de tokens, que corresponden aproximadamente a «palabras». Esta es una de las tareas básicas de la PNL. Para hacer esto usando TextBlob, siga los dos pasos:
- Crear un textblob objeto y pasar una cuerda con él.
- Llama funciones de textblob para realizar una tarea específica.
Entonces, creemos rápidamente un objeto textblob para jugar.
from textblob import TextBlob
blob = TextBlob("DataPeaker is a great platform to learn data science. n It helps community through blogs, hackathons, discussions,etc.")
Ahora, este bloque de texto se puede convertir en una oración y luego en palabras. Veamos el código que se muestra a continuación.
3.2 Extracción de frases sustantivas
Como extrajimos las palabras en la sección anterior, en lugar de eso, podemos simplemente extraer las frases nominales del bloque de texto. La extracción de frases sustantivas es particularmente importante cuando desea analizar el «quién» en una oración. Veamos un ejemplo a continuación.
blob = TextBlob("DataPeaker is a great platform to learn data science.")
for np in blob.noun_phrases:
print (np)
>> analytics vidhya
great platform
data science
Como vemos, los resultados no son del todo correctos, pero debemos ser conscientes de que estamos trabajando con máquinas.
3.3 Etiquetado de parte de la voz
El etiquetado de parte de la oración o el etiquetado gramatical es un método para marcar palabras presentes en un texto sobre la base de su definición y contexto. En palabras simples, dice si una palabra es un sustantivo, un adjetivo, un verbo, etc. Esta es solo una versión completa de la extracción de sintagmas nominales, donde queremos encontrar todas las partes del discurso en una oración.
Revisemos las etiquetas de nuestro bloque de texto.
for words, tag in blob.tags:
print (words, tag)
>> Analytics NNS
Vidhya NNP
is VBZ
a DT
great JJ
platform NN
to TO
learn VB
data NNS
science NN
Aquí, NN representa un sustantivo, DT representa un determinante, etc. Puede consultar la lista completa de etiquetas en aquí para saber mas.
3.4 Inflexión y lematización de palabras
Inflexión es un proceso de palabra formación en la que se añaden caracteres a la forma base de un palabra para expresar significados gramaticales. La inflexión de palabras en TextBlob es muy simple, es decir, las palabras que hemos tokenizado de un textblob se pueden cambiar fácilmente a singular o plural.
blob = TextBlob("DataPeaker is a great platform to learn data science. n It helps community through blogs, hackathons, discussions,etc.")
print (blob.sentences[1].words[1])
print (blob.sentences[1].words[1].singularize())
>> helps
help
La biblioteca TextBlob también ofrece un objeto integrado conocido como Palabra. Solo necesitamos crear un objeto de palabra y luego aplicarle una función directamente como se muestra a continuación.
from textblob import Word
w = Word('Platform')
w.pluralize()
>>'Platforms'
También podemos usar las etiquetas para declinar un tipo particular de palabras como se muestra a continuación.
## using tags for word,pos in blob.tags: if pos == 'NN': print (word.pluralize()) >> platforms sciences
Las palabras se pueden lematizar utilizando la lematizar función.
## lemmatization
w = Word('running')
w.lemmatize("v") ## v here represents verb
>> 'run'
3,5 N-gramos
Una combinación de varias palabras juntas se llama N-Grams. Los N gramas (N> 1) son generalmente más informativos en comparación con las palabras y pueden usarse como características para el modelado del lenguaje. Se puede acceder fácilmente a N-gramas en TextBlob usando el ngramas función, que devuelve una tupla de n palabras sucesivas.
for ngram in blob.ngrams(2):
print (ngram)
>> ['Analytics', 'Vidhya']
['Vidhya', 'is']
['is', 'a']
['a', 'great']
['great', 'platform']
['platform', 'to']
['to', 'learn']
['learn', 'data']
['data', 'science']
3.6 Análisis de sentimiento
El análisis de sentimientos es básicamente el proceso de determinar la actitud o la emoción del escritor, es decir, si es positiva, negativa o neutral.
los sentimiento función de textblob devuelve dos propiedades, polaridad, y subjetividad.
La polaridad es flotante que se encuentra en el rango de [-1,1] donde 1 significa declaración positiva y -1 significa declaración negativa. Las oraciones subjetivas generalmente se refieren a opiniones, emociones o juicios personales, mientras que las objetivas se refieren a información fáctica. La subjetividad es también un flotador que se encuentra en el rango de [0,1].
Revisemos el sentimiento de nuestro blob.
print (blob) blob.sentiment >> DataPeaker is a great platform to learn data science. Sentiment(polarity=0.8, subjectivity=0.75)
Podemos ver que la polaridad es 0,8, lo que significa que la declaración es positiva y 0,75 la subjetividad se refiere a que mayoritariamente es una opinión pública y no una información fáctica.
4. Otras cosas interesantes que hacer
4.1 Corrección ortográfica
La corrección ortográfica es una característica interesante que ofrece TextBlob, se puede acceder a nosotros utilizando el correcto funcionar como se muestra a continuación.
blob = TextBlob('DataPeaker is a gret platfrm to learn data scence')
blob.correct()
>> TextBlob("DataPeaker is a great platform to learn data science")
También podemos comprobar la lista de palabras sugeridas y su confianza utilizando el corrector ortográfico función.
blob.words[4].spellcheck()
>> [('great', 0.5351351351351351),
('get', 0.3162162162162162),
('grew', 0.11216216216216217),
('grey', 0.026351351351351353),
('greet', 0.006081081081081081),
('fret', 0.002702702702702703),
('grit', 0.0006756756756756757),
('cret', 0.0006756756756756757)]
4.2 Crear un breve resumen de un texto
Este es un truco simple que utilizaremos las cosas que aprendimos anteriormente. Primero, eche un vistazo al código que se muestra a continuación y comprenda usted mismo.
import random
blob = TextBlob('DataPeaker is a thriving community for data driven industry. This platform allows
people to know more about analytics from its articles, Q&A forum, and learning paths. Also, we help
professionals & amateurs to sharpen their skillsets by providing a platform to participate in Hackathons.')
nouns = list()
for word, tag in blob.tags:
if tag == 'NN':
nouns.append(word.lemmatize())
print ("This text is about...")
for item in random.sample(nouns, 5):
word = Word(item)
print (word.pluralize())
>> This text is about...
communities
platforms
forums
platforms
industries
Simple, ¿no es así? Lo que hicimos anteriormente es que extrajimos una lista de sustantivos del texto para dar una idea general al lector sobre las cosas con las que se relaciona el texto.
4.3 Traducción y detección de idiomas
¿Puedes adivinar lo que está escrito en la siguiente línea?
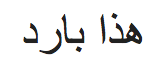
¡Ja ja! ¿Puedes adivinar qué idioma es este? No te preocupes, detectémoslo usando textblob…
blob.detect_language() >> 'ar'
Entonces, es árabe. Ahora, busquemos traducirlo al inglés para que podamos saber qué está escrito usando TextBlob.
blob.translate(from_lang='ar', to ='en')
>> TextBlob("that's cool")
Incluso si no define explícitamente el idioma de origen, TextBlob detectará automáticamente el idioma y lo traducirá al idioma deseado.
blob.translate(to= 'en') ## or you can directly do like this
>> TextBlob("that's cool")
¡¡¡Esto es realmente genial !!! 😀
5. Clasificación de texto mediante TextBlob
Construyamos un modelo de clasificación de texto simple usando TextBlob. Para esto, primero, necesitamos preparar un entrenamiento y datos de prueba.
training = [
('Tom Holland is a terrible spiderman.','pos'),
('a terrible Javert (Russell Crowe) ruined Les Miserables for me...','pos'),
('The Dark Knight Rises is the greatest superhero movie ever!','neg'),
('Fantastic Four should have never been made.','pos'),
('Wes Anderson is my favorite director!','neg'),
('Captain America 2 is pretty awesome.','neg'),
('Lets pretend "Batman and Robin" never happened..','pos'),
]
testing = [
('Superman was never an interesting character.','pos'),
('Fantastic Mr Fox is an awesome film!','neg'),
('Dragonball Evolution is simply terrible!!','pos')
]
Textblob proporciona un módulo de clasificadores incorporado para crear un clasificador personalizado. Entonces, importémoslo rápidamente y creemos un clasificador básico.
from textblob import classifiers classifier = classifiers.NaiveBayesClassifier(training)
Como puede ver arriba, hemos pasado los datos de entrenamiento al clasificador.
Tenga en cuenta que aquí hemos utilizado el clasificador Naive Bayes, pero TextBlob también ofrece un clasificador de árbol de decisión que se muestra a continuación.
## decision tree classifier dt_classifier = classifiers.DecisionTreeClassifier(training)
Ahora, verifiquemos la precisión de este clasificador en el conjunto de datos de prueba y también TextBlob nos proporciona para verificar las características más informativas.
print (classifier.accuracy(testing))
classifier.show_informative_features(3)
>> 1.0
Most Informative Features
contains(is) = True neg : pos = 2.9 : 1.0
contains(terrible) = False neg : pos = 1.8 : 1.0
contains(never) = False neg : pos = 1.8 : 1.0
Como, podemos ver que si el texto contiene «es», entonces hay una alta probabilidad de que la declaración sea negativa.
Para dar un poco más de idea, revisemos nuestro clasificador en un texto aleatorio.
blob = TextBlob('the weather is terrible!', classifier=classifier)
print (blob.classify())
>> neg
Entonces, según el entrenamiento en el conjunto de datos anterior, nuestro clasificador nos ha proporcionado el resultado correcto.
Tenga en cuenta que aquí podríamos haber hecho algo de preprocesamiento y limpieza de datos, pero aquí mi objetivo era darle una idea de cómo podemos hacer la clasificación de texto usando TextBlob.
6. Pros y contras
Pros:
- Dado que, está construido sobre los hombros de NLTK y Pattern, por lo tanto, lo hace simple para los principiantes al proporcionar una interfaz intuitiva para NLTK.
- Proporciona traducción y detección de idiomas que funciona con Google Translate (no se proporciona con Spacy).
Contras:
- Es un poco más lento en comparación con el espacio, pero más rápido que NLTK. (Espacio> TextBlob> NLTK)
- No proporciona características como análisis de dependencias, vectores de palabras, etc. que proporciona spacy.
7. Notas finales
Espero que te diviertas aprendiendo sobre esta biblioteca. TextBlob, en realidad, proporcionó una interfaz muy fácil para que los principiantes aprendan tareas básicas de PNL.
Recomendaría a todos los principiantes que comiencen con esta biblioteca y luego, para hacer un trabajo avanzado, también pueden aprender a ser espaciados. Seguiremos usando TextBlob para la creación inicial de prototipos en casi todos los proyectos de PNL.
Puede encontrar el código completo de este artículo en mi github repositorio.
Además, ¿le resultó útil este artículo? Comparta sus opiniones / pensamientos en la sección de comentarios a continuación.





