Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Hay muchas formas de comparar texto en Python. Sin embargo, a menudo buscamos una forma sencilla de comparar texto. La comparación de texto es necesaria para diversos fines de análisis de texto y procesamiento del lenguaje natural.
Una de las formas más fáciles de comparar texto en Python es usar la biblioteca fuzzy-wuzzy. Aquí, obtenemos una puntuación de 100, según la similitud de las cadenas. Básicamente, se nos da el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de similitud. La biblioteca utiliza la distancia de Levenshtein para calcular la diferencia entre dos cadenas.

Distancia de Levenshtein
La distancia de Levenshtein es una métrica de cadena para calcular la diferencia entre dos cadenas diferentes. El matemático soviético Vladimir Levenshtein formuló este método y lleva su nombre.
La distancia de Levenshtein entre dos cuerdas a, b (de longitud {| a | y | b | respectivamente) viene dado por lev (a, b) dónde
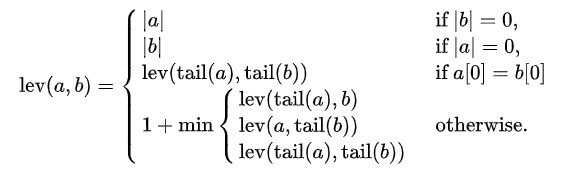
donde el cola de alguna cuerda X es una cadena de todos menos el primer carácter de X, y X[n] es el norteth carácter de la cadena X comenzando con el carácter 0.
(Fuente: https://en.wikipedia.org/wiki/Levenshtein_distance)
FuzzyWuzzy
Fuzzy Wuzzy es una biblioteca de código abierto desarrollada y lanzada por SeatGeek. Puedes leer su blog original aquí. La implementación simple y la puntuación única (sobre 100) metic hacen que sea interesante usar FuzzyWuzzy para la comparación de texto y tiene numerosas aplicaciones.
Instalación:
pip install fuzzywuzzy
pip install python-Levenshtein
Estos son los requisitos que se deben instalar.
Comencemos ahora con el código importando las bibliotecas necesarias.
from fuzzywuzzy import fuzz from fuzzywuzzy import process
Se hacen las importaciones necesarias.
#string comparison #exactly same text fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio('London is a big city.', 'London is a big city.')
Salida: 100
Como las dos cadenas son exactamente iguales aquí, obtenemos el resultado 100, que indica cadenas idénticas.
#string comparison #not same text fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio('London is a big city.', 'London is a very big city.')
Salida: 89
Como las cuerdas ahora son diferentes, la puntuación es 89. Entonces, vemos el funcionamiento de Fuzzy Wuzzy.
#now let us do conversion of cases a1 = "Python Program" a2 = "PYTHON PROGRAM" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(a1.lower(),a2.lower()) print(Ratio)
Salida: 100
Aquí, en este caso, aunque las dos cadenas diferentes tenían casos diferentes, se realizó la conversión de ambas a minúsculas y la puntuación fue 100.
Coincidencia de subcadenas
Ahora, a menudo pueden surgir varios casos de coincidencia de texto en los que necesitamos comparar dos cadenas diferentes donde una podría ser una subcadena de la otra. Por ejemplo, estamos probando un resumen de texto y tenemos que comprobar qué tan bien se está desempeñando. Entonces, el texto resumido será una subcadena de la cadena original. FuzzyWuzzy tiene funciones poderosas para lidiar con estos casos.
#fuzzywuzzy functions to work with substring matching b1 = "The Samsung Group is a South Korean multinational conglomerate headquartered in Samsung Town, Seoul." b2 = "Samsung Group is a South Korean company based in Seoul" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(b1.lower(),b2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(b1.lower(),b2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio)
Producción:
Ratio: 64 Partial Ratio: 74
Aquí, podemos ver que la puntuación para la función de Razón Parcial es mayor. Esto indica que es capaz de reconocer el hecho de que la cadena b2 tiene palabras de b1.
Proporción de clasificación de tokens
Pero el método anterior de comparación de subcadenas no es infalible. A menudo, las palabras se mezclan y no siguen un orden. De manera similar, en el caso de oraciones similares, el orden de las palabras es diferente o está mezclado. En este caso, usamos una función diferente.
c1 = "Samsung Galaxy SmartPhone" c2 = "SmartPhone Samsung Galaxy" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(c1.lower(),c2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(c1.lower(),c2.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(c1.lower(),c2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio)
Producción:
Ratio: 56 Partial Ratio: 60 Token Sort Ratio: 100
Entonces, aquí, en este caso, podemos ver que las cadenas son solo versiones mezcladas entre sí. Y las dos cadenas muestran el mismo sentimiento y también mencionan la misma entidad. La función estándar de fuzz muestra que la puntuación entre ellos es 56. Y la función Token Sort Ratio muestra que la similitud es 100.
Entonces, queda claro que en algunas situaciones o aplicaciones, el índice de clasificación de tokens será más útil.
Proporción de conjunto de fichas
Pero, ahora si las dos cadenas tienen diferentes longitudes. Es posible que las funciones de relación de clasificación de tokens no funcionen bien en esta situación. Para ello, disponemos de la función Token Set Ratio.
d1 = "Windows is built by Microsoft Corporation" d2 = "Microsoft Windows" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(d1.lower(),d2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(d1.lower(),d2.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.lower(),d2.lower()) Token_Set_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.lower(),d2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio) print("Token Set Ratio:",Token_Set_Ratio)
Producción:
Ratio: 41 Partial Ratio: 65 Token Sort Ratio: 59 Token Set Ratio: 100
¡Ah! La puntuación de 100. Bueno, la razón es que la cadena d2 los componentes están completamente presentes en la cadena d1.
Ahora, modifiquemos ligeramente la cadena d2.
d1 = "Windows is built by Microsoft Corporation" d2 = "Microsoft Windows 10" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(d1.lower(),d2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(d1.lower(),d2.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.lower(),d2.lower()) Token_Set_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.lower(),d2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio) print("Token Set Ratio:",Token_Set_Ratio)
Por, modificando ligeramente el texto d2 podemos ver que la puntuación se reduce a 92. Esto se debe a que el texto “10«No está presente en la cadena d1.
WRatio ()
Esta función ayuda a administrar las mayúsculas, minúsculas y algunos otros parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.....
#fuzz.WRatio() print("Slightly change of cases:",fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarI LAFerrari'))
Producción:
Slightly change of cases: 100
Intentemos eliminar un espacio.
#fuzz.WRatio() print("Slightly change of cases and a space removed:",fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarILAFerrari'))
Producción:
Slightly change of cases and a space removed: 97
Probemos con algunos signos de puntuación.
#handling some random punctuations g1='Microsoft Windows is good, but takes up lof of ram!!!' g2='Microsoft Windows is good but takes up lof of ram?' print(fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio(g1,g2 ))
Salida: 99
Por lo tanto, podemos ver que FuzzyWuzzy tiene muchas funciones interesantes que pueden usarse para realizar interesantes tareas de comparación de texto.
Algunas aplicaciones adecuadas:
FuzzyWuzzy puede tener algunas aplicaciones interesantes.
Se puede utilizar para evaluar resúmenes de textos más extensos y juzgar su similitud. Esto se puede utilizar para medir el rendimiento de los resúmenes de texto.
Según la similitud de los textos, también se puede utilizar para identificar la autenticidad de un texto, artículo, noticia, libro, etc. A menudo, nos encontramos con varios textos / datos incorrectos. A menudo, no es posible verificar todos y cada uno de los datos de texto. Utilizando la similitud de texto, se puede realizar una verificación cruzada de varios textos.
FuzzyWuzzy también puede resultar útil para seleccionar el mejor texto similar entre varios textos. Entonces, las aplicaciones de FuzzyWuzzy son numerosas.
La similitud de texto es una métrica importante que se puede utilizar para varios propósitos de análisis de texto y PNL. Lo interesante de FuzzyWuzzy es que las similitudes se dan como una puntuación de 100. Esto permite una puntuación relativa y también genera una nueva característica / datos que se pueden utilizar con fines analíticos / ML.
Similitud resumida:
#uses of fuzzy wuzzy #summary similarity input_text="Text Analytics involves the use of unstructured text data, processing them into usable structured data. Text Analytics is an interesting application of Natural Language Processing. Text Analytics has various processes including cleaning of text, removing stopwords, word frequency calculation, and much more. Text Analytics has gained much importance these days. As millions of people engage in online platforms and communicate with each other, a large amount of text data is generated. Text data can be blogs, social media posts, tweets, product reviews, surveys, forum discussions, and much more. Such huge amounts of data create huge text data for organizations to use. Most of the text data available are unstructured and scattered. Text analytics is used to gather and process this vast amount of information to gain insights. Text Analytics serves as the foundation of many advanced NLP tasks like Classification, Categorization, Sentiment Analysis, and much more. Text Analytics is used to understand patterns and trends in text data. Keywords, topics, and important features of Text are found using Text Analytics. There are many more interesting aspects of Text Analytics, now let us proceed with our resume dataset. The dataset contains text from various resume types and can be used to understand what people mainly use in resumes. Resume Text Analytics is often used by recruiters to understand the profile of applicants and filter applications. Recruiting for jobs has become a difficult task these days, with a large number of applicants for jobs. Human Resources executives often use various Text Processing and File reading tools to understand the resumes sent. Here, we work with a sample resume dataset, which contains resume text and resume category. We shall read the data, clean it and try to gain some insights from the data."
Lo anterior es el texto original.
output_text="Text Analytics involves the use of unstructured text data, processing them into usable structured data. Text Analytics is an interesting application of Natural Language Processing. Text Analytics has various processes including cleaning of text, removing stopwords, word frequency calculation, and much more. Text Analytics is used to understand patterns and trends in text data. Keywords, topics, and important features of Text are found using Text Analytics. There are many more interesting aspects of Text Analytics, now let us proceed with our resume dataset. The dataset contains text from various resume types and can be used to understand what people mainly use in resumes."
Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(input_text.lower(),output_text.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(input_text.lower(),output_text.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(input_text.lower(),output_text.lower()) Token_Set_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(input_text.lower(),output_text.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio) print("Token Set Ratio:",Token_Set_Ratio)
Producción:
Ratio: 54 Partial Ratio: 79 Token Sort Ratio: 54 Token Set Ratio: 100
Podemos ver las distintas partituras. La relación parcial muestra que son bastante similares, lo que debería ser el caso. Además, la proporción del conjunto de fichas es 100, lo cual es evidente ya que el resumen está completamente tomado del texto original.
La mejor coincidencia de cadenas posible:
Usemos la biblioteca de procesos para encontrar la mejor coincidencia de cadenas posible entre una lista de cadenas.
#choosing the possible string match #using process library query = 'Stack Overflow' choices = ['Stock Overhead', 'Stack Overflowing', 'S. Overflow',"Stoack Overflow"] print("List of ratios: ") print(process.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.process.extract'}, '*')">extract(query, choices)) print("Best choice: ",process.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.process.extractOne'}, '*')">extractOne(query, choices))
Producción:
List of ratios:
[('Stoack Overflow', 97), ('Stack Overflowing', 90), ('S. Overflow', 85), ('Stock Overhead', 64)]
Best choice: ('Stoack Overflow', 97)
Por lo tanto, se dan las puntuaciones de similitud y la mejor coincidencia.
Ultimas palabras
La biblioteca FuzzyWuzzy se crea sobre la biblioteca difflib. Y python-Levenshtein utilizado para optimizar la velocidad. Entonces podemos entender que FuzzyWuzzy es una de las mejores formas de comparar cadenas en Python.
Verifique el código en Kaggle aquí.
Sobre mí:
Prateek Majumder
Ciencia de datos y análisis | Especialista en marketing digital | SEO | Creación de contenido
Conéctate conmigo en Linkedin.
Mis otros artículos sobre DataPeaker: Link.
Gracias.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





