- s = estado
- a = acción
- r = recompensa
- t = paso de tiempo
- γ = tasa de descuento
- α = tasa de aprendizaje
Tanto la tasa de aprendizaje como la tasa de descuento están entre 0 y 1. La última determina cuánto nos preocupamos por la recompensa futura. Cuanto más cerca de 1, más nos importa.
El inconveniente de Q-learning es que tiene problemas con enormes espacios de acción y estado. Memorizar cada par de acciones y estados posibles necesita mucha memoria. Por esta razón, necesitamos combinar Q-learning con técnicas de Deep Learning.
Aprendizaje profundo de Q
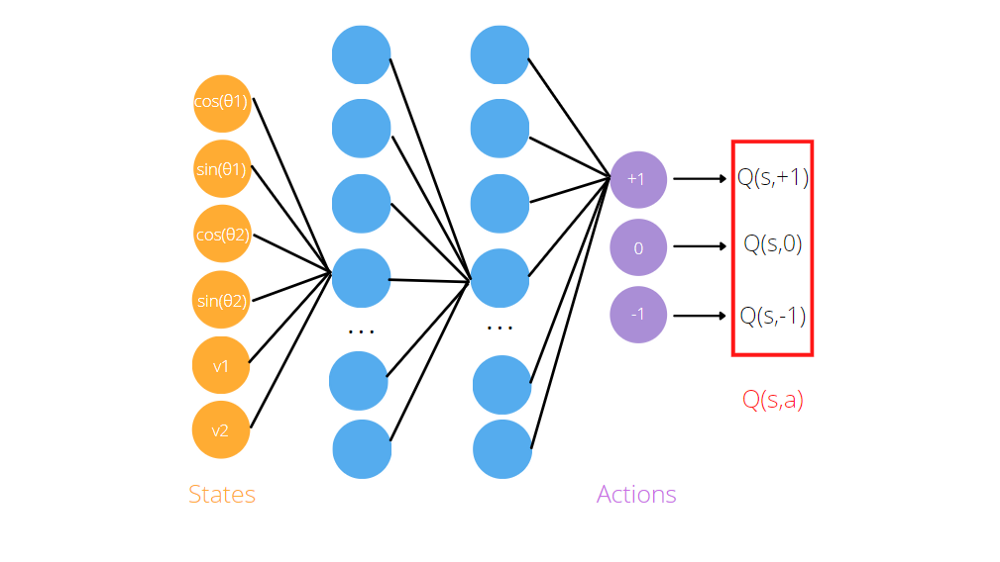
Como vimos, el algoritmo Q-learning necesita aproximadores de funciones, como redes neuronales artificiales, para memorizar los tripletes (estado, acción, valor Q). La idea del aprendizaje de Deep Q es utilizar redes neuronales para predecir los valores de Q para cada acción dado el estado. Si volvemos a considerar el juego Acrobot, lo pasamos a la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... artificial como entrada la información es sobre el agente (sen y cos de ángulos articulares, velocidades). Para obtener las predicciones, necesitamos entrenar la red antes y definir la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y..., que generalmente es la diferencia entre el valor Q predicho y el valor Q objetivo.
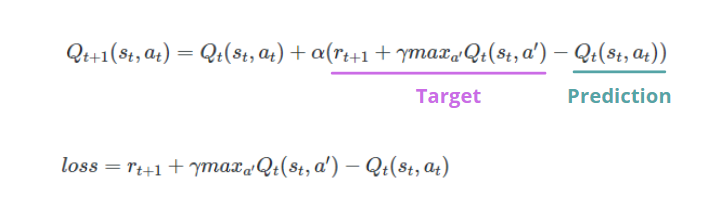
A diferencia del aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en..., no tenemos ninguna etiqueta que identifique el valor Q correcto para cada par de estado-acción. En DQL, inicializamos dos redes neuronales artificiales idénticas, llamadas Red de destino y Red de políticas. El primero se utilizará para calcular los valores objetivo, mientras que el segundo para determinar la predicción.
Por ejemplo, el modelo para el juego de Acrobat es una red neuronal artificial que toma como entrada las observaciones del entorno, el pecado y el cos de los dos ángulos de articulación rotacional y las dos velocidades angulares. Devuelve tres salidas, Q (s, + 1), Q (s, -1), Q (s, 0), donde s es el estado, pasado como entrada a la red. De hecho, el objetivo de la red neuronal es predecir el rendimiento esperado de tomar cada acción dada la entrada actual.
Experiencia de repetición
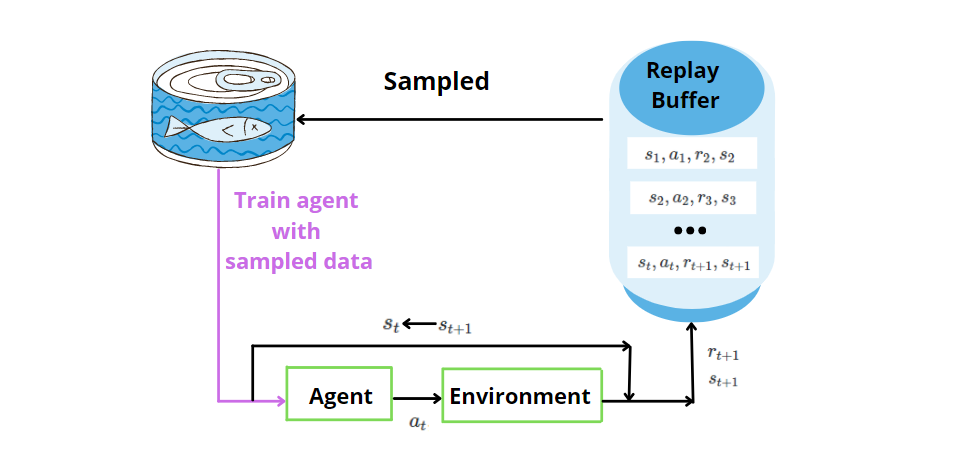
La ANN no es suficiente sola. La experiencia es una técnica en la que almacenamos los datos pasados descubiertos por el agente para (estado, acción, recompensa, siguiente estado) en cada paso de tiempo. Más tarde, tomamos muestras de la memoria al azar para un mini lote de experiencia y la usamos para entrenar la red neuronal artificial. Al muestrear aleatoriamente, permitimos proporcionar datos no correlacionados al modelo de red neuronal y mejorar la eficiencia de los datos.
Exploración vs Explotación
La exploración y la explotación son conceptos clave en el algoritmo Deep RL. Se refiere a la forma en que el agente selecciona las acciones. ¿Qué son exploración y explotación? Supongamos que queremos ir a un restaurante. La exploración es cuando quieres probar un nuevo restaurante, mientras que la explotación es cuando quieres permanecer en tu zona de confort, por lo que irás directamente a tu restaurante favorito. Lo mismo ocurre con el agente. Al principio, quiere explorar el medio ambiente. Mientras interactúe con el medio ambiente, tomará decisiones más basadas en la explotación que en la exploración.
Hay dos estrategias posibles:
- ε-codicioso, donde el agente realiza una acción aleatoria con probabilidad ε, luego explora el entorno y selecciona la acción codiciosa con probabilidad 1-ε, entonces estamos en una situación de explotación.
- suave-max, donde el agente selecciona las acciones óptimas en función de los valores Q devueltos por la red neuronal artificial.
¡Felicidades! Ahora comprende los conceptos de RL y DRL a través del ejemplo de Acrobot que le presentó este nuevo mundo. El aprendizaje de Deep Q ha ganado mucha atención después de las aplicaciones en los juegos de Atari y Go. Espero que esta guía no te asuste y te anime a profundizar en el tema. Gracias por leer. ¡Que tenga un lindo día!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





