Introducción
Resolvamos los entornos Cartpole, Lunar Lander y Pong de OpenAI con el algoritmo REFORZAR.
El aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas.... es posiblemente la rama más genial de la inteligencia artificial. Ya ha demostrado su destreza: asombrar al mundo, vencer a los campeones mundiales en partidas de Ajedrez, Go e incluso DotA 2.
En este artículo, analizaría un algoritmo bastante rudimentario y mostraría cómo incluso esto puede lograr un nivel sobrehumano de rendimiento en ciertos juegos.
Ofertas de aprendizaje por refuerzo with diseñando «Agentes» que interactúa con un «Medio ambiente» y aprende por sí mismo cómo «resolver» el medio ambiente por ensayo y error sistemáticos. Un entorno podría ser un juego como el ajedrez o las carreras, o incluso podría ser una tarea como resolver un laberinto o lograr un objetivo. El agente es el bot que realiza la actividad.
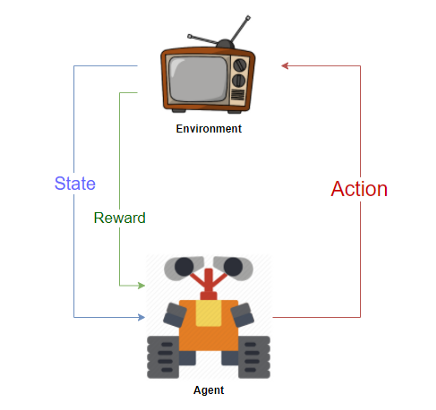
Un agente recibe «recompensas» al interactuar con el medio ambiente. El agente aprende a realizar las «acciones» necesarias para maximizar la recompensa que recibe del entorno. Un entorno se considera resuelto si el agente acumula algún umbral de recompensa predefinido. Esta charla nerd es cómo enseñamos a los bots a jugar ajedrez sobrehumano o a los androides bípedos a caminar.
REFORZAR Algoritmo
REINFORCE pertenece a una clase especial de algoritmos de aprendizaje por refuerzo llamados algoritmos de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... de políticas. Una implementación simple de este algoritmo implicaría la creación de un Política: un modelo que toma un estado como entrada y genera la probabilidad de realizar una acción como salida. Una política es esencialmente una guía o una hoja de trucos para el agente que le dice qué acción tomar en cada estado. Luego, la política se repite y se modifica ligeramente en cada paso hasta que obtenemos una política que resuelve el entorno.
La política suele ser una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... que toma el estado como entrada y genera una distribución de probabilidad en el espacio de acción como salida.
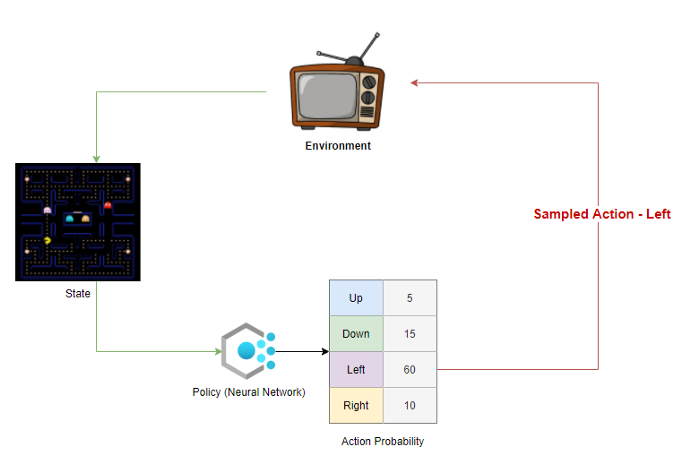
El objetivo de la política es maximizar la “Recompensa esperada”.
Cada política genera la probabilidad de realizar una acción en cada estación del entorno.
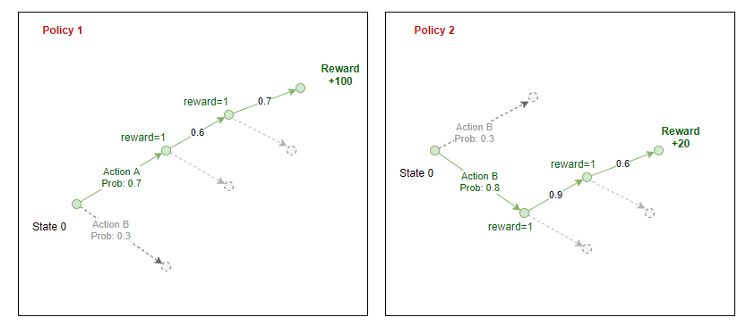
El agente toma muestras de estas probabilidades y selecciona una acción para realizar en el entorno. Al final de un episodio, sabemos las recompensas totales que el agente puede obtener si sigue esa política. Repropagamos la recompensa a través de la ruta que tomó el agente para estimar la «recompensa esperada» en cada estado para una política determinada.

Aquí la recompensa con descuento es la suma de todas las recompensas que recibe el agente en ese futuro descontadas por un factor Gamma.

La recompensa con descuento en cualquier etapa es la recompensa que recibe en el siguiente paso + una suma con descuento de todas las recompensas que el agente reciba en el futuro.
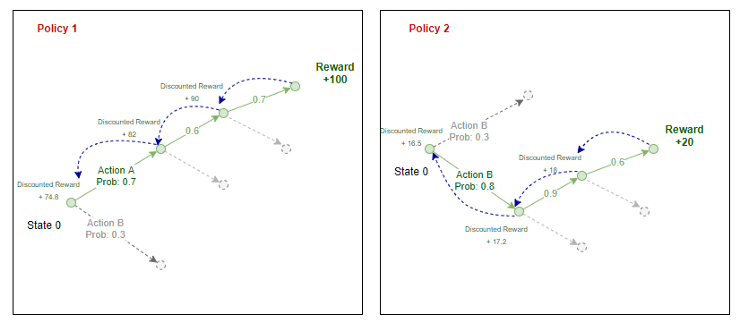
Para la ecuación anterior, así es como calculamos la recompensa esperada:
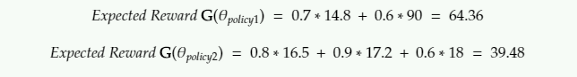
Según la implementación original del algoritmo REFORZAR, la recompensa esperada es la suma de los productos de un registro de probabilidades y recompensas descontadas.
Pasos del algoritmo
Los pasos involucrados en la implementación de REFORZAR serían los siguientes:
- Inicializar una política aleatoria (una NN que toma el estado como entrada y devuelve la probabilidad de acciones)
- Utilice la política para jugar N pasos del juego: registrar las probabilidades de acción, de la política, la recompensa del entorno, la acción, muestreada por el agente
- Calcule la recompensa con descuento para cada paso mediante retropropagación
- Calcule la recompensa esperada G
- Ajuste los pesos de la política (error de propagación inversa en NN) para aumentar G
- Repetir desde 2
Consulte la implementación usando Pytorch en mi Github.
Población
He probado el algoritmo en Pong, CartPole y Lunar Lander. Se tarda una eternidad en entrenar en Pong y Lunar Lander: más de 96 horas de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... cada uno en una GPU en la nube. Hay varias actualizaciones en este algoritmo que pueden hacer que converja más rápido, que no he discutido ni implementado aquí. Consulte los modelos de actor crítico y la optimización de políticas próximas si está interesado en obtener más información.
Carrito

Estado:
Posición horizontal, velocidad horizontal, ángulo del polo, velocidad angular
Comportamiento:
Empuje el carro hacia la izquierda, Empuje el carro hacia la derecha
Juego de política aleatorio:
Política de agentes capacitados con REFORZAR:
Lander lunar
Agente de juego aleatorio
Estado:
El estado es una matriz de 8 vectores. No estoy seguro de lo que representan.
Comportamiento:
0: no hacer nada
1: motor izquierdo de fuego
2: Motor de incendio
3: motor derecho de fuego
Política de agentes capacitados con REFORZAR:
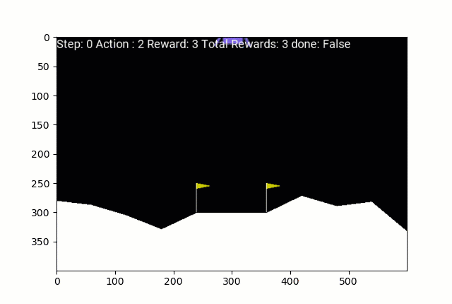
Lunar Lander entrenado con REFORZAR
Apestar
Esto fue mucho más difícil de entrenar. Capacitado en un servidor en la nube de GPU durante días.
Estado: Imagen
Comportamiento: Mover paleta a la izquierda, mover paleta a la derecha
Agente capacitado
El aprendizaje por refuerzo ha progresado a pasos agigantados más allá de REFORZAR. Mi objetivo en este artículo era 1. aprender los conceptos básicos del aprendizaje por refuerzo y 2. mostrar cuán poderosos pueden ser incluso métodos tan simples para resolver problemas complejos. Me encantaría probarlos en algunos «juegos» para hacer dinero como el comercio de acciones … supongo que ese es el santo grial entre los científicos de datos.
Repositorio de Github: https://github.com/kvsnoufal/reinforce
Hombros de gigantes:
- Algoritmos de gradiente de políticas (https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html)
- Derivando REFORZAR (https://medium.com/@thechrisyoon/deriving-policy-gradients-and-implementing-reinforce-f887949bd63)
- Curso de aprendizaje por refuerzo de Udacity (https://github.com/udacity/deep-reinforcement-learning)
Sobre el Autor

Noufal kvs
Trabajo en Dubai Holding, EAU como científico de datos. Puedes comunicarte conmigo en [email protected] o https://www.linkedin.com/in/kvsnoufal/





