Introducción
¿Alguna vez ha resuelto un problema de aprendizaje automático de una sola vez?
Resolver un problema mediante el aprendizaje automático no es sencillo. Implica varios pasos para llegar a una solución precisa. El proceso / pasos a seguir para resolver un problema de ml se conoce como ML PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, por ejemplo, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los... / ML Cycle.
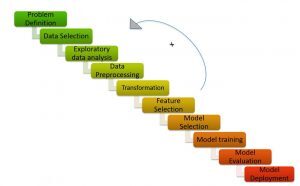
ML Pipeline / ML Cycle (Créditos: https://medium.com/analytics-vidhya/machine-learning-development-life-cycle-dfe88c44222e)
Como se muestra en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas...., la canalización de Machine Learning consta de diferentes pasos como:
Comprender el planteamiento del problema, la generación de hipótesis, el análisis de datos exploratorios, el preprocesamiento de datos, la ingeniería de características, la selección de características, la construcción de modelos, el ajuste de modelos y la implementación de modelos.
Recomendaría leer los artículos a continuación para obtener una comprensión detallada de la canalización del aprendizaje automático:
- ¡Explicación del ciclo de vida del aprendizaje automático!
- Pasos para completar un proyecto de aprendizaje automático
El proceso de resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... de un problema de aprendizaje automático implica mucho tiempo y esfuerzo humano. ¡Hip hip hurra! ¡Ya no es un proceso tedioso y lento! Gracias a AutoML por brindar soluciones instantáneas a los problemas de aprendizaje automático.
AutoML se trata de crear automáticamente el modelo de alto rendimiento con la menor intervención humana.
Las bibliotecas de AutoML ofrecen programación de código bajo y sin código.
Probablemente haya oído hablar de los términos «código bajo» y «sin código».
- Sin código Los frameworks son UI simples que permiten incluso a los usuarios no técnicos construir modelos sin escribir una sola línea de código.
- Código bajo se refiere a la codificación mínima.
Aunque las plataformas sin código facilitan el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de un modelo de aprendizaje automático mediante una interfaz de arrastrar y soltar, están limitadas en términos de flexibilidad. El ML de código bajo, por otro lado, es el punto óptimo y el término medio, ya que ofrecen flexibilidad y código fácil de usar.
En este artículo, entendamos cómo construir un modelo de clasificación de texto dentro de unas pocas líneas de código usando una biblioteca de AutoML de código bajo, PyCaret.
Tabla de contenido
- ¿Qué es PyCaret?
- ¿Por qué necesitamos PyCaret?
- Diferentes enfoques para resolver la clasificación de texto en PyCaret
- Modelado de temas
- Vectorizador de conteo
- Estudio de caso: clasificación de texto con PyCaret
¿Qué es PyCaret?
PyCaret es una biblioteca de aprendizaje automático de código bajo y de código abierto en Python que le permite pasar de preparar sus datos a implementar su modelo en unos pocos minutos.

PyCaret (Créditos: https://pycaret.org/)
PyCaret es esencialmente una biblioteca de código bajo que reemplaza cientos de líneas de código en scikit learn a 5-6 líneas de código. Aumenta la productividad del equipo y ayuda al equipo a centrarse en comprender el problema y la ingeniería de funciones en lugar de optimizar el modelo.
PyCaret (Créditos: https://pycaret.org/about/)
PyCaret está construido sobre una biblioteca scikit learn. Como resultado, todos los algoritmos de aprendizaje automático disponibles en scikit learn están disponibles en pycaret. A partir de ahora, PyCaret puede resolver problemas relacionados con la clasificación, regresión, agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo..., detección de anomalías, clasificación de texto, minería de reglas asociadas y series de tiempo.
Ahora, analicemos las razones detrás del uso de PyCaret.
¿Por qué necesitamos PyCaret?
PyCaret crea automáticamente el modelo de referencia dado un conjunto de datos dentro de 5-6 líneas de código. Veamos cómo pycaret simplifica cada paso en la canalización del aprendizaje automático.
- Preparación de datos: PyCaret realiza la limpieza y el preprocesamiento de datos con la menor intervención manual.
- Ingeniería de funciones: PyCaret crea las características matemáticas automáticamente y selecciona las características más importantes necesarias para el modelo
- Construcción del modelo: Simplifica enormemente la parte de modelado de su proyecto. Podemos construir diferentes modelos y seleccionar los modelos de mejor rendimiento con una sola línea de código.
- Ajuste del modelo: PyCaret afina el modelo sin pasar explícitamente los hiperparámetros a cada modelo.
A continuación, nos centraremos en resolver un problema de clasificación de texto en PyCaret.
Diferentes enfoques para resolver la clasificación de texto en PyCaret
Resolvamos un problema de clasificación de texto en PyCaret usando 2 técnicas diferentes:
- Modelado de temas
- Vectorizador de conteo
Tocaré cada enfoque en detalle
Modelado de temas
El modelado de temas, como su nombre lo indica, es una técnica para identificar diferentes temas presentes en los datos del texto.
Los temas se definen como un grupo repetido de símbolos (o palabras) estadísticamente significativos en un corpus. Aquí, la significación estadística se refiere a palabras importantes del documento. En general, las palabras que aparecen con frecuencia con puntuaciones TF-IDF más altas se consideran palabras estadísticamente significativas.
El modelado de temas es una técnica no supervisada para encontrar automáticamente los temas ocultos en los datos de texto. También se puede denominar el enfoque de minería de texto para encontrar patrones recurrentes en documentos de texto.
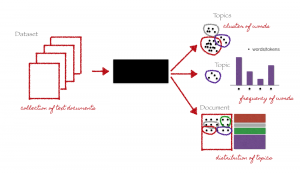
Modelado de temas (Créditos: https://medium.com/analytics-vidhya/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045)
Algunos casos de uso comunes del modelado de temas son los siguientes:
-  Resolver problemas de clasificación / regresión de texto
- Creación de etiquetas relevantes para documentos
- Genere información para formularios de comentarios de clientes, reseñas de clientes, resultados de encuestas, etc.
Ejemplo de modelado de temas
Supongamos que trabaja para un bufete de abogados y está trabajando con una empresa en la que se ha malversado algo de dinero y sabe que hay información clave en los correos electrónicos que se han distribuido en la empresa.
- Entonces, revisa los correos electrónicos y hay cientos de miles de correos electrónicos. Ahora, lo que debe hacer es averiguar cuáles están relacionados con el dinero en comparación con otros temas.
- Puede etiquetarlos a mano según lo que lea en el texto, lo que llevaría mucho tiempo, o puede usar la técnica llamada modelado de temas para averiguar cuáles son estas etiquetas y etiquetar automáticamente todos estos correos electrónicos.
Como se explicó anteriormente, el objetivo del modelado de temas es extraer diferentes temas del texto sin procesar. Pero, ¿cuál es el algoritmo subyacente para lograrlo?
Esto nos lleva a los diferentes algoritmos / técnicas para el modelado de temas: asignación de Dirichlet latente (LDA), factorización de matriz no negativa (NNMF), asignación semántica latente (LSA).
Le recomendaría que consulte los siguientes recursos para leer en detalle sobre los algoritmos
- Parte 2: Modelado de temas y asignación de Dirichlet latente (LDA) usando Gensim y Sklearn
- Guía para principiantes sobre modelado de temas en Python
- Modelado de temas con LDA: una introducción práctica
Llegando al modelado de temas, es un proceso de 2 pasos:
- Distribución de tema a término: Encuentra los temas más importantes del corpus.
- Distribución de documento a tema: Asigne puntuaciones de cada tema a cada documento.
Habiendo entendido el modelado de temas, veremos cómo resolver la clasificación de texto utilizando el modelado de temas con la ayuda de un ejemplo.
Considere un corpus:
- Documento 1: Quiero desayunar frutas.
- Documento 2: Me gusta comer almendras, huevos y frutas.
- Documento 3: Me llevaré frutas y galletas cuando vaya al zoológico.
- Documento 4: El cuidador del zoológico alimenta al león con mucho cuidado.
- Documento 5: Se deben dar galletas de buena calidad a sus perros.
El algoritmo de modelado de temas (LDA) identifica los temas más importantes de los documentos.
- Tema 1: 30% frutas, 15% huevos, 10% galletas,… (comida)
- Tema 2: 20% león, 10% perros, 5% zoológico,… (animales)
A continuación, asigna puntuaciones de cada tema a los documentos de la siguiente manera.
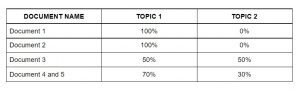
Asignar temas a cada documento mediante LDA
Esta matriz actúa como características del algoritmo de aprendizaje automático. A continuación, veremos la bolsa de palabras.
Bolsa de palabras
Bag Of Words (BOW) es otro algoritmo popular para representar texto en números. Depende de la frecuencia de las palabras del documento. BOW tiene numerosas aplicaciones como clasificación de documentos, modelado de temas y similitud de texto. En BOW, cada documento se representa como la frecuencia de palabras presentes en el documento. Entonces, la frecuencia de las palabras representa la importancia de las palabras en el documento.
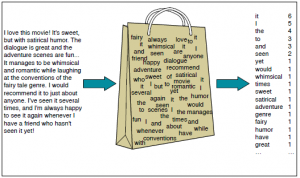
Bolsa de palabras (Créditos: Jurafsky et al., 2018)
Siga el artículo a continuación para obtener una comprensión detallada de Bag Of Words:
En la siguiente sección, resolveremos el problema de clasificación de texto en PyCaret.
Estudio de caso: clasificación de texto con PyCaret
Entendamos el enunciado del problema antes de resolverlo.
Comprensión del enunciado del problema
Steam es un servicio de distribución digital de videojuegos con una vasta comunidad de jugadores a nivel mundial. Muchos jugadores escriben reseñas en la página del juego y tienen la opción de elegir si recomendarían este juego a otros o no. Sin embargo, determinar este sentimiento automáticamente a partir del texto puede ayudar a Steam a etiquetar automáticamente las reseñas extraídas de otros foros de Internet y puede ayudarlos a juzgar mejor la popularidad de los juegos.
Dado el texto de revisión con la recomendación del usuario, la tarea es predecir si el revisor recomendó los títulos de juegos disponibles en el conjunto de prueba sobre la base del texto de revisión y otra información.
En términos más simples, la tarea en cuestión es identificar si una revisión de usuario determinada es buena o mala. Puede descargar el conjunto de datos desde aquí.
Implementación
Para clasificar las reseñas de juegos de Steam usando PyCaret, he discutido 2 enfoques diferentes en el artículo.
- El primer enfoque utiliza el modelado de temas utilizando PyCaret.
- El segundo enfoque utiliza las características de Bag Of Words. Utilice estas funciones para la clasificación mediante PyCaret.
Implementaremos el enfoque BOW ahora.
Nota: El tutorial está implementado en Google Colab. Recomendaría ejecutar el código en el mismo.
Instalación de PyCaret
Puede instalar PyCaret como cualquier otra biblioteca de Python.
- Instalación de PyCaret en Google Colab o Azure Notebooks
Importación de bibliotecas
Cargando datos
Como PyCaret no admite el vectorizador de conteo, importe el módulo CountVectorizer de sklearn.feature_extraction.
Luego, inicializo un objeto CountVectorizer llamado ‘tf_vectorizer’.
¿Qué hace exactamente la función fit_transform con sus datos?
- «Ajustar» extrae las características del conjunto de datos.
- «Transformar» en realidad realiza las transformaciones en el conjunto de datos.
Convirtamos la salida de fit_transform al marco de datos.
Ahora, concatene las características y el objetivo a lo largo de la columna.
A continuación, dividiremos el conjunto de datos en datos de prueba y de tren.
Ahora que la extracción de características está lista. Usemos estas funciones para construir diferentes modelos. Entonces, el siguiente paso es configurar el entorno en PyCaret.
Configurando el medio ambiente
- Esta función configura el marco de entrenamiento y construye el proceso de transición. La función de configuración debe llamarse antes de que se pueda llamar a cualquier otra función.
- El único parámetro obligatorio son los datos y el objetivo.
Creación de modelos
Ajuste del modelo
De la salida anterior, podemos observar que las métricas del modelo ajustado son mejores que las métricas del modelo base.
Evaluar y predecir el modelo
Aquí, he predicho los valores de la bandera para nuestro conjunto de datos procesados, ‘tuned_lightgbm’.
Notas finales
PyCaret, que entrena modelos de aprendizaje automático en un entorno de código bajo, despertó mi interés. Desde su entorno de portátil preferido, PyCaret le ayuda a pasar de la preparación de datos a la implementación de modelos en segundos. Antes de usar PyCaret, probé otros métodos tradicionales para resolver el problema del hackathon JanataHack NLP, ¡pero los resultados no fueron muy satisfactorios!
PyCaret ha demostrado ser exponencialmente rápido y eficiente en comparación con las otras bibliotecas de aprendizaje automático de código abierto y también tiene la ventaja de reemplazar varias líneas de código con solo unas pocas palabras.
Aquí, si evita la primera parte de mi enfoque donde uso las técnicas de incrustación de vectorizador de conteo en mi conjunto de datos y luego pasa a configurar y crear modelos usando PyCaret, entonces puede notar que todas las transformaciones, como la codificación en caliente , la imputación de valores perdidos, etc., sucederá detrás de escena automáticamente, y luego obtendrá un marco de datos con predicciones, ¡como lo que obtuvimos!
Espero haber dejado claro mi enfoque general para el hackathon.





