Este artículo fue publicado como parte del Blogatón de ciencia de datos
Ciencia de datos, aprendizaje automático, MLops, ingeniería de datos, todas estas fronteras de datos avanzan con rapidez y precisión. El futuro de la ciencia de datos lo definen firmas más grandes como Microsoft, Amazon, Databricks, Google y estas empresas están impulsando la innovación en este campo. Debido a estos cambios tan rápidos, tiene sentido certificarse con cualquiera de estos grandes actores y conocer su oferta de productos. Además, con las soluciones de extremo a extremo proporcionadas por estas plataformas, desde lagos de datos escalables hasta clústeres escalables, tanto para pruebas como para producción, lo que facilita la vida de los profesionales de datos. Desde una perspectiva empresarial, tiene toda la infraestructura bajo un mismo techo, en la nube y bajo demanda, y cada vez más empresas se inclinan o, además, se ven obligadas a trasladarse a la nube debido a la pandemia en curso.
¿Cómo ayuda DP-100 (Diseño e implementación de una solución de ciencia de datos en Azure) a un científico de datos o cualquier persona que trabaje con datos?
En resumen, las empresas recopilan datos de diversas fuentes, aplicaciones móviles, sistemas POS, herramientas internas, máquinas, etc., y todos estos se encuentran en varios departamentos o varias bases de datos, esto es especialmente cierto para las grandes empresas heredadas. Uno de los principales obstáculos para los científicos de datos es obtener datos relevantes bajo un mismo techo para construir modelos y usarlos en la producción. En el caso de Azure, todos estos datos se mueven a un lago de datos, la manipulación de datos se puede hacer usando grupos SQL o Spark, limpieza de datos, preprocesamiento de modelos, construcción de modelos usando clústeres de prueba (bajo costo), monitoreo de modelos, equidad de modelos, datos deriva e implementación mediante clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... (alto costo escalable más alto). El científico de datos puede concentrarse en resolver problemas y dejar que Azure haga el trabajo pesado.
Otro escenario de caso de uso es el seguimiento de modelos utilizando mlflow (proyecto de código abierto de Databricks). Cualquiera que haya participado en un hackathon de DS sabe que el seguimiento de modelos, el registro de métricas y la comparación de modelos es una tarea tediosa, si no ha configurado una canalización. En Azure, todo esto se facilita mediante el uso de experimentos llamados, todos los modelos se registran, las métricas se registran, los artefactos se registran, todo usando una sola línea de código.
Acerca de Azure DP-100
Azure DP-100 (Diseño e implementación de una solución de ciencia de datos en Azure) es la certificación de ciencia de datos de Microsoft para todos los entusiastas de los datos. Es una experiencia de aprendizaje a su propio ritmo, con libertad y flexibilidad. Después de la finalización, uno puede trabajar en azul sin problemas y construir modelos, rastrear experimentos, construir tuberías, ajustar hiperparámetros y Camino AZUR.
Requisitos
- El conocimiento básico de Python, después de haber trabajado en él durante al menos 3-6 meses, facilita la preparación para el examen.
- Conocimientos básicos de aprendizaje automático. Esto ayuda a entender los códigos y responder a las preguntas sobre AA durante el examen.
- Habiendo trabajado en el portátil Jupyter o en el laboratorio Jupyter, esto no es un mandato, ya que todos los laboratorios están en el portátil jupyter, es fácil trabajar con ellos.
- El conocimiento de Databricks y mlflow se puede aprovechar para obtener mejores calificaciones en la prueba. A partir de julio de 2021, estos conceptos se incluyen en DP-100.
- Rs. 4500 tasas de examen.
- Regístrese para obtener una cuenta gratuita de Azure, recibirá créditos de 13.000 rupias con los que se puede explorar Azure ML. Esto es más que suficiente. Pero Azure ML es gratuito solo durante los primeros 30 días. Así que haz un buen uso de esta suscripción.
- Lo más importante es establecer la fecha de su examen dentro de 30 días a partir de hoy, pagarlo, esto sirve como un buen factor de motivación.
Página del examen dp 100

¿Vale la pena?
El costo del examen es de aproximadamente 4.500 rupias y no muchas empresas esperan una certificación durante el reclutamiento, es bueno tenerla, pero muchas, ni los reclutadores lo exigen ni lo saben, entonces surge la pregunta: ¿vale la pena pagarlo? ¿Vale la pena mis fines de semana? La respuesta es sí, simplemente porque, aunque uno podría ser un gran maestro de aprendizaje automático o un experto en Python, pero el funcionamiento interno de Azure es específico de Azure, muchos métodos son específicos de Azure para impulsar mejoras de rendimiento. No se puede simplemente volcar un código Python y esperar que brinde un rendimiento óptimo. Muchos procesos están automatizados en azure, por ejemplo: el módulo automl crea modelos con solo una línea de código, el ajuste de hiperparámetros requiere una línea de código. Sin código ML es otra herramienta de arrastrar y soltar que hace que la construcción de modelos sea un juego de niños. Contenedores / almacenamiento / bóvedas clave / espacio de trabajo / experimentos / todos son herramientas y clases específicas de azul. Al crear instancias de cómputo, trabajar con la canalización, mlflow también ayuda a comprender los conceptos de Mlops. Definitivamente es una ventaja si está trabajando en Azure y desea explorar el meollo de la cuestión. En general, las recompensas superan el esfuerzo.
Preparación
- El examen se basa en MCQ con alrededor de 60 a 80 preguntas y el tiempo proporcionado es de 180 minutos. Este tiempo es más que suficiente para completar y revisar todas las preguntas.
- Se hacen dos preguntas de laboratorio o preguntas de tipo estudio de caso y estas son preguntas obligatorias y no se pueden omitir.
- Es una prueba supervisada, así que asegúrese de prepararse para el examen.
- Microsoft cambia el patrón aproximadamente dos veces al año, por lo que es mejor revisar la actualización patrón de examen.
- Es más fácil si la preparación del examen se divide en 2 pasos, teoría y laboratorio.
- La teoría es bastante detallada y necesita al menos 1-2 semanas de preparación y revisión. Todas las preguntas teóricas se pueden estudiar desde microsoft docs. Un estudio detallado de estos documentos será suficiente.
- Esta sección importante constituye el mayor número de preguntas – Cree y opere soluciones de aprendizaje automático con Azure Machine Learning.
- Los laboratorios también son importantes. Aunque no se harán preguntas prácticas de laboratorio, es útil comprender las clases y métodos específicos de Azure. Y estos constituyen la mayoría de las preguntas.
- No se harán preguntas sobre aprendizaje automático, por ejemplo, no se preguntará cuál es la puntuación R2. Lo que se puede preguntar es cómo registrar la puntuación R2 para un experimento. Entonces, la aplicación ML en azure debería ser el foco.
- Microsoft proporciona una guía dirigida por un instructor. curso pagado también para DP-100. No veo la necesidad de abordar esto, ya que todo se proporciona en los documentos de MS.
- Los laboratorios de práctica, alrededor de 14, practican al menos una vez para familiarizarse con el espacio de trabajo de Azure.
- Revise la teoría antes de presentarse a los exámenes, para no confundirse durante el examen.
Habilidades medidas:
- Configurar un área de trabajo de Azure Machine Learning
- Ejecute experimentos y entrene modelos
- Optimizar y administrar modelos
- Implementar y consumir modelos
Clone el repositorio para practicar azure labs:
git clone https://github.com/microsoftdocs/ml-basics
Algunos métodos / clases importantes de Azure:
## to create workspace
ws = Workspace.get(name="aml-workspace",
subscription_id='1234567-abcde-890-fgh...',
resource_group='aml-resources')
## register model
model = Model.register(workspace=ws,
model_name="classification_model",
model_path="model.pkl", # local path
description='A classification model',
tags={'data-format': 'CSV'},
model_framework=Model.Framework.SCIKITLEARN,
model_framework_version='0.20.3')
## Run a .py file in a piepeline
step2 = PythonScriptStep(name="train model",
source_directory = 'scripts',
script_name="train_model.py",
compute_target="aml-cluster")
# Define the parallel run step step configuration
parallel_run_config = ParallelRunConfig(
source_directory='batch_scripts',
entry_script="batch_scoring_script.py",
mini_batch_size="5",
error_threshold=10,
output_action="append_row",
environment=batch_env,
compute_target=aml_cluster,
node_count=4)
# Create the parallel run step
parallelrun_step = ParallelRunStep(
name="batch-score",
parallel_run_config=parallel_run_config,
inputs=[batch_data_set.as_named_input('batch_data')],
output=output_dir,
arguments=[],
allow_reuse=True
)
Algunos conceptos importantes (no es una lista exhaustiva):
- Cree un clúster de cómputo para pruebas y producciones
- Crear pasos de canalización
- Conecte el clúster de Databricks al espacio de trabajo de Azure ML
- Método de ajuste de hiperparámetros
- Trabajar con datos: conjuntos de datos y almacén de datos
- Deriva del modelo
- Privacidad diferencial
- Detectar la injusticia del modelo (preguntas de MCQ)
- Modele explicaciones usando explicadores shap.
- Método para recordar
- Scriptrunconfig
- PipelineData
- ParallelRunConfig
- PipelineEndpoint
- RunConfiguration
- init () ejecutar ()
- PublicadoPipeline
- ComputeTarget.attach
- métodos de datasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.... / datastore
Sesión de preparación para el examen de Azure DP-100
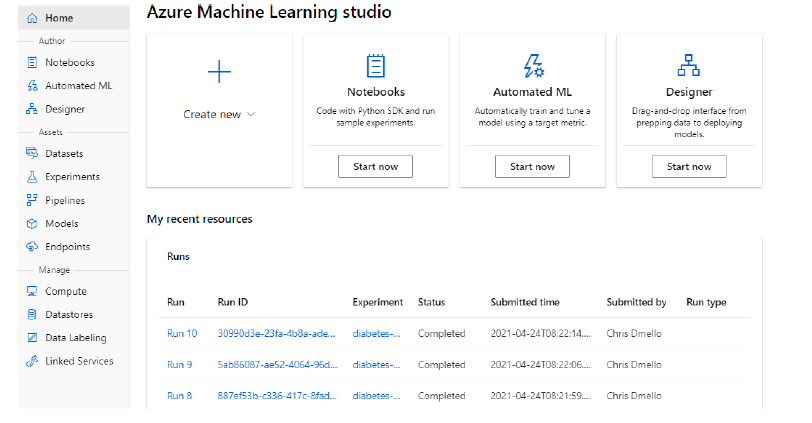
Espacio de trabajo de Azure Machine Learning:
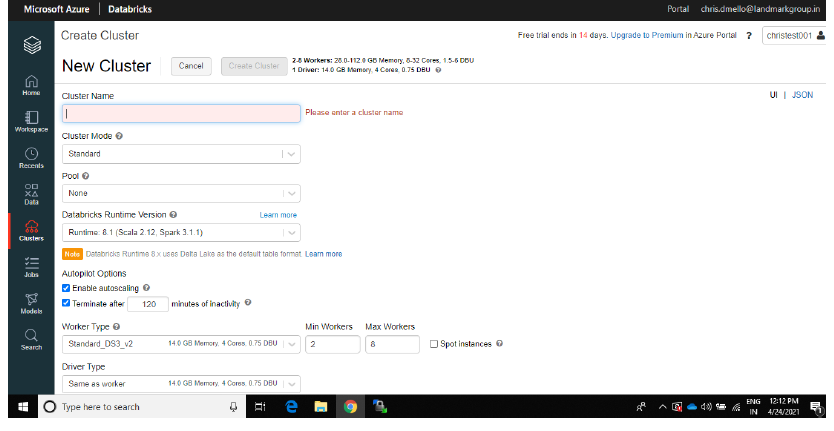
Azure DatabricksAzure Databricks es una plataforma de análisis de datos basada en Apache Spark, diseñada para facilitar la colaboración entre científicos de datos e ingenieros. Proporciona un entorno integrado que permite la ingesta, procesamiento y análisis de grandes volúmenes de datos. Con su escalabilidad y herramientas avanzadas de inteligencia artificial, Azure Databricks optimiza el flujo de trabajo y acelera la toma de decisiones en proyectos de datos complejos.... crea un clúster:
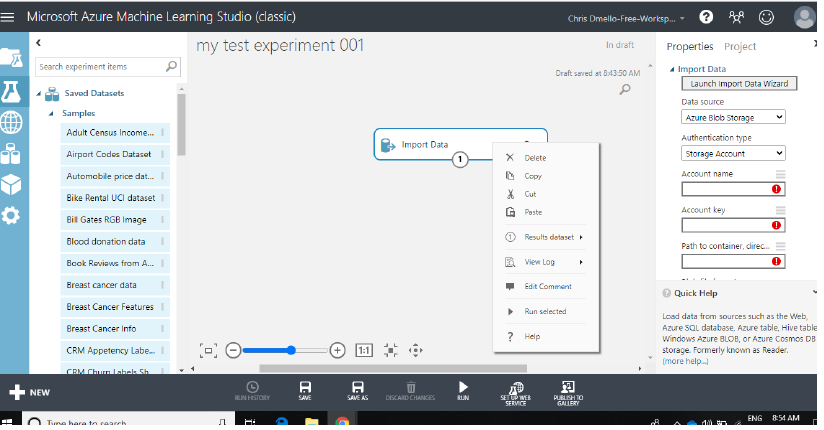
Diseñador de Azure:
Día del examen
- Asegúrese de probar su sistema un día antes. Las computadoras portátiles de trabajo a veces causan problemas, por lo que es mejor usar computadoras portátiles personales.
- No se permiten libros / papeles / bolígrafos u otros artículos de papelería.
- El supervisor realiza las comprobaciones básicas iniciales y le permite iniciar el examen.
- Una vez que se envía el examen, los puntajes se proporcionan en la pantalla y luego en un correo electrónico. Así que no olvide revisar su correo.
- La certificación es válida solo por 2 años.
¡Buena suerte! Tu próximo objetivo debería ser DP-203 (Ingeniería de datos en Microsoft Azure).
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





