Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción:
Tecnología. Este conjunto de datos consta de dígitos escritos a mano del 0 al 9 y proporciona un pavimento para probar los sistemas de procesamiento de imágenes. Este se considera el ‘programa hola mundo en Machine Learning’ que involucra Deep Learning.
Los pasos involucrados son:
- Importar conjunto de datos
- Dividir el conjunto de datos en prueba y entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....
- Construcción del modelo
- Entrena el modelo
- Predecir la precisión
1) Importación de conjunto de datos:
Para continuar con el código, necesitamos el conjunto de datos. Entonces, pensamos en varias fuentes como conjuntos de datos, UCI, kaggle, etc. Pero como estamos usando Python con sus vastos módulos incorporados, tiene los datos MNIST en el módulo keras.datasets. Por lo tanto, no necesitamos descargar y almacenar los datos de forma externa.
from keras.datsets import mnist data = mnist.load_data()
Por lo tanto, desde el módulo keras.datasets importamos la función mnist que contiene el conjunto de datos.
Luego, el conjunto de datos se almacena en los datos variables utilizando la función mnist.load_data () que carga el conjunto de datos en los datos variables.
A continuación, veamos el tipo de datos que encontramos algo inusual ya que es del tipo tupla. Sabemos que el conjunto de datos mnist contiene imágenes de dígitos escritas a mano, almacenadas en forma de tuplas.
data type(data)
2) Divida el conjunto de datos en entrenar y probar:
Dividimos directamente el conjunto de datos en tren y prueba. Entonces, para eso, inicializamos cuatro variables X_train, y_train, X_test, y_test para dañar el tren y probar los datos de los valores dependientes e independientes respectivamente.
(X_train, y_train), (X_test, y_test) = data X_train[0].shape X_train.shape

Al imprimir la forma de cada imagen podemos encontrar que tiene un tamaño de 28 × 28. Lo que significa que la imagen tiene 28 píxeles x 28 píxeles.
Ahora, tenemos que remodelar de tal manera que podamos acceder a cada píxel de la imagen. La razón para acceder a cada píxel es que solo entonces podemos aplicar ideas de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y podemos asignar un código de color a cada píxel. Luego almacenamos la matriz remodelada en X_train, X_test respectivamente.
X_train = X_train.reshape((X_train.shape[0], 28*28)).astype('float32')
X_test = X_test.reshape((X_test.shape[0], 28*28)).astype('float32')
Conocemos el código de color RGB donde diferentes valores producen varios colores. También es difícil recordar todas las combinaciones de colores. Entonces, refiérase a esto Enlace para tener una breve idea sobre los códigos de color RGB.
Ya sabemos que cada píxel tiene su código de color único y también sabemos que tiene un valor máximo de 255. Para realizar Machine Learning, es importante convertir todos los valores de 0 a 255 para cada píxel a un rango de valores de 0 a 1. La forma más sencilla es dividir el valor de cada píxel por 255 para obtener los valores en el rango de 0 a 1.
X_train = X_train / 255 X_test = X_test / 255
Ahora hemos terminado de dividir los datos en prueba y entrenamiento, así como de preparar los datos para su uso posterior. Por lo tanto, ahora podemos pasar al Paso 3: Construcción de modelos.
3) Entrene al modelo:
Para realizar la construcción de modelos, tenemos que importar las funciones requeridas, es decir, secuencial y denso para ejecutar el aprendizaje profundo, que está disponible en la biblioteca de Keras.
Pero esto no está disponible directamente, por lo que debemos comprender este simple gráfico de líneasEl gráfico de líneas es una herramienta visual utilizada para representar datos a lo largo del tiempo. Consiste en una serie de puntos conectados por líneas, lo que permite observar tendencias, fluctuaciones y patrones en los datos. Este tipo de gráfico es especialmente útil en áreas como la economía, la meteorología y la investigación científica, facilitando la comparación de diferentes conjuntos de datos y la identificación de comportamientos a lo...:
1) Keras -> Modelos -> Secuencial
2) Keras -> Capas -> Denso
Veamos cómo podemos importar las funciones con la misma lógica que un código Python.
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(32, input_dim = 28 * 28, activation= 'relu')) model.add(Dense(64, activation = 'relu')) model.add(Dense(10, activation = 'softmax'))
Luego almacenamos la función en el modelo de variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos...., ya que facilita el acceso a la función cada vez en lugar de escribir la función cada vez, podemos usar la variable y llamar a la función.
Luego, convierta la imagen en un grupo denso de capas y apile cada capa una encima de la otra y usamos ‘relu’ como nuestra función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones..... La explicación de ‘relu’ está más allá del alcance de este blog. Para obtener más información al respecto, puede consultar eso.
Por otra parte, apilamos algunas capas más con ‘softmax’ como nuestra función de activación. Para obtener más información sobre la función ‘softmax’, puede consultar este artículo, ya que está más allá del alcance de este blog nuevamente, ya que mi objetivo principal es obtener la mayor precisión posible con el conjunto de datos MNIST.
Luego, finalmente compilamos el modelo completo y usamos entropía cruzada como nuestra función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y..., para optimizar el uso de nuestro modelo Adán como nuestro optimizador y utilizamos la precisión como métricas para evaluar nuestro modelo.
Para obtener una descripción general de nuestro modelo, usamos ‘model.summary ()’, que proporciona breves detalles sobre nuestro modelo.
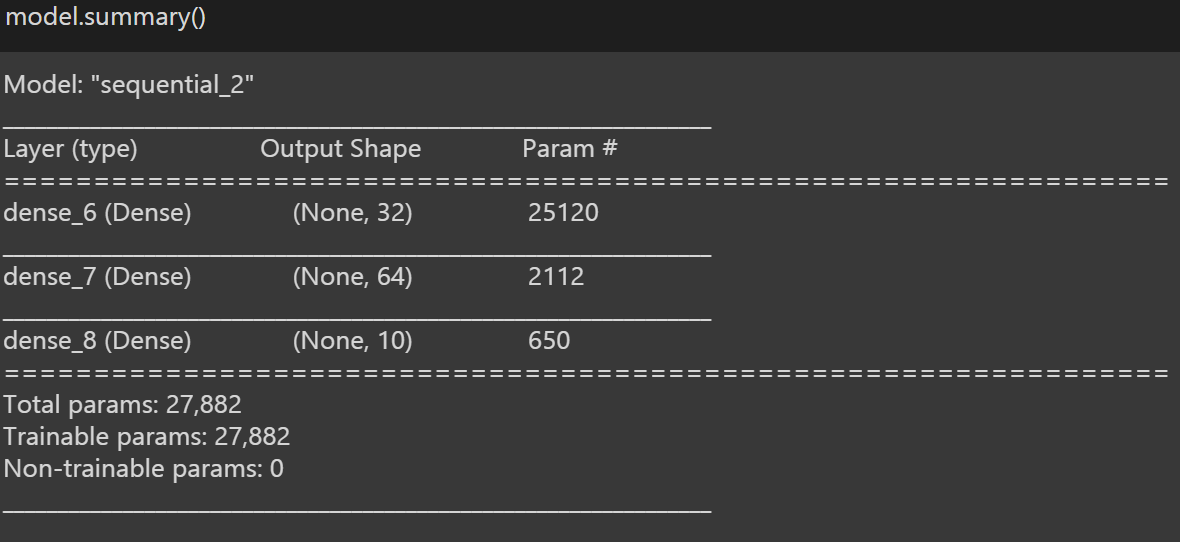
Ahora podemos pasar al Paso 4: Entrenar el modelo.
4) Entrene al modelo:
Este es el penúltimo paso en el que vamos a entrenar el modelo con una sola línea de código. Entonces, para eso, estamos usando la función .fit () que toma el conjunto de trenes de la variable dependiente y la independiente y dependiente como entrada, y establece epochs = 10, y establece batch_size como 100.
Juego de trenes => X_train; y_train
Épocas => Una época significa entrenar la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... con todos los datos de entrenamiento para un ciclo. Una época se compone de uno o más lotes, donde usamos una parte del conjunto de datos para entrenar la red neuronal. Lo que significa que enviamos el modelo a entrenar 10 veces para obtener una alta precisión. También puede cambiar el número de épocas según el rendimiento del modelo.
Tamaño del lote => El tamaño del lote es un término utilizado en el aprendizaje automático y se refiere a la cantidad de ejemplos de entrenamiento utilizados en una iteración. Entonces, básicamente, enviamos 100 imágenes para entrenar como un lote por iteración.
Veamos la parte de codificación.
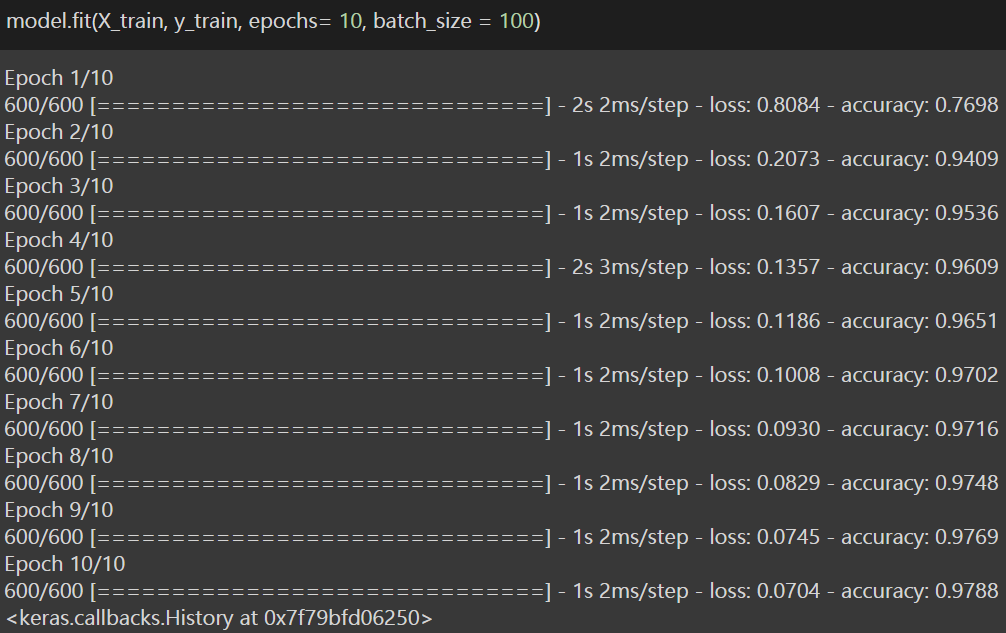
Por lo tanto, después de entrenar el modelo, hemos logrado una precisión del 97,88% para el conjunto de datos de entrenamiento. Ahora es el momento de ver cómo funciona el modelo en el conjunto de prueba y ver si hemos logrado la precisión requerida. Por lo tanto, ahora pasamos al último paso o Paso 5: Predecir la precisión.
5) Precisión de predicción:
Entonces, para saber qué tan bien funciona el modelo en el conjunto de datos de prueba, utilizo la variable de puntajes para almacenar el valor y uso la función .evaluate () que toma el conjunto de prueba de las variables dependientes e independientes como entrada. Esto calcula la pérdida y la precisión del modelo en el conjunto de prueba. Como nos enfocamos en la precisión, imprimimos solo la precisión.

Finalmente, hemos logrado el resultado y aseguramos una precisión de más del 96% en el conjunto de prueba que es muy apreciable, y se logra el motivo del blog. He escrito el enlace al computadora portátil para su referencia (lectores).
Por favor, siéntete libre de conectarte conmigo a través de Linkedin así como. Y gracias por leer el blog.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





