Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Estas situaciones se pueden abordar entendiendo el caso de uso de cada métrica.
Todo el mundo conoce los conocimientos básicos de todas las métricas de clasificación de uso frecuente, pero cuando se trata de saber cuál es la adecuada para evaluar el rendimiento de su modelo de clasificación, muy pocos confían en el siguiente paso a dar.
El aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... normalmente se encuentra en regresión (tener objetivos continuos) o en clasificación (tener objetivos discretos). Sin embargo, en este artículo, intentaré centrarme en una parte muy pequeña pero muy importante del aprendizaje automático, que siendo el tema favorito de los entrevistadores, «quién sabe qué», también puede ayudarlo a obtener sus conceptos correctos en los modelos de clasificación y, finalmente, sobre cualquier problema comercial. Este artículo le ayudará a saber que cuando alguien le dice que un modelo ml está dando un 94% de precisión, qué preguntas debe hacer para saber si el modelo realmente está funcionando como se requiere.

Entonces, ¿cómo decidir las preguntas que ayudarán?
Ahora, ese es un pensamiento para el alma.
Responderemos a eso sabiendo evaluar un modelo de clasificación, de la manera correcta.
Repasaremos los siguientes temas en este artículo:
-
Precisión
-
Defectos
-
Matriz de confusión
-
Métricas basadas en la matriz de confusión
-
Resumen
Después de leer este artículo, tendrá los conocimientos sobre:
-
¿Qué es la matriz de confusión y por qué necesita usarla?
-
Cómo calcular una matriz de confusión para un problema de clasificación de 2 clases
-
Métricas basadas en la matriz de confusión y cómo usarlas
Precisión y sus defectos:
La precisión (ACC) mide la fracción de predicciones correctas. Se define como «la relación entre predicciones correctas y predicciones totales realizadas».

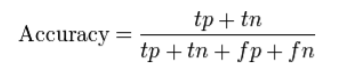
Problema con la precisión:
Oculta los detalles que necesita para comprender mejor el rendimiento de su modelo de clasificación. Puede seguir los siguientes ejemplos que lo ayudarán a comprender el problema:
-
VariableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de destino de varias clases: cuando sus datos tienen más de 2 clases. Con 3 o más clases, puede obtener una precisión de clasificación del 80%, pero no sabe si eso se debe a que todas las clases se predicen igualmente bien o si el modelo está descuidando una o dos clases.
-
Da desequilibrado
Un típico ejemplo de datos desequilibrados se encuentra en un problema de clasificación de correo electrónico en el que los correos electrónicos se clasifican como spam o no spam. Aquí, el recuento de correos electrónicos no deseados es considerablemente muy bajo (menos del 10%) que el número de correos electrónicos relevantes (no spam) (más del 90%). Entonces, la distribución original de dos clases conduce a un conjunto de datos desequilibrado.
Si tomamos dos clases, entonces los datos balanceados significarían que tenemos 50% de puntos para cada una de las clases. Además, si hay 60-65% puntos para una clase y 40% f
La precisión de la clasificación no resalta los detalles que necesita para diagnosticar el rendimiento de su modelo. Esto se puede resaltar utilizando una matriz de confusión.

Matriz de confusión:
Wikipedia define el término como “una matriz de confusión, también conocida como matriz de error, es un diseño de tabla específico que permite la visualización del rendimiento de un algoritmo”.

A continuación se muestra una matriz de confusión para dos clases (+, -).
Hay cuatro cuadrantes en la matriz de confusión, que se simbolizan a continuación.
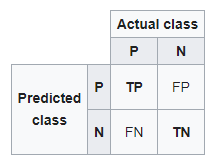
matriz de confusión
- : El número de en
- Predijo que un correo es spam y en realidad lo es.
- Falso negativo (FN): El número de instancias que fueron positivas (+) y se clasificaron incorrectamente como negativas (-). También se conoce como Error tipo 2.
- Predijo que un correo no es spam y en realidad lo es.
- Verdadero negativo (TN): El número de instancias que fueron negativas (-) y se clasificaron correctamente como (-).
- Predijo que un correo no es spam y en realidad no lo es.
- Falso positivo (FP): El número de instancias que fueron negativas (-) y se clasificaron incorrectamente como (+). Esto también conocido como Error tipo 1.
- Predijo que un correo no es spam y en realidad lo es.
Para agregar un poco de claridad:
Arriba a la izquierda: verdaderos positivos para valores de eventos correctamente predichos.
Derecha superior: falsos positivos para valores de eventos predichos incorrectamente.
Abajo a la izquierda: falsos negativos para valores sin eventos correctamente predichos.
Abajo a la derecha: Negativos verdaderos para valores sin eventos predichos incorrectamente.
Métricas basadas en matriz de confusión:
-
Precisión
-
Recordar
-
Puntuación F1
Precisión
La precisión calcula la capacidad de un clasificador de no etiquetar una observación negativa verdadera como positiva.
Precision=TP/(TP+FP)
Usando precisión
Usamos precisión cuando trabaja en un modelo similar al conjunto de datos de detección de spam, ya que Recall en realidad calcula cuántos de los positivos reales captura nuestro modelo al etiquetarlo como positivo.
Recordar (sensibilidad)
Recall calcula la capacidad de un clasificador para encontrar observaciones positivas en el conjunto de datos. Si quisiera estar seguro de encontrar todas las observaciones positivas, podría maximizar la memoria.
Recall=TP/(TP+FN)
Siempre tendemos a utilizar el retiro cuando necesitamos identificar correctamente los escenarios positivos, como en un conjunto de datos de detección de cáncer o un caso de detección de fraude. La exactitud o la precisión no serán tan útiles aquí.
Medida F
Para comparar dos modelos cualesquiera, utilizamos F1-Score. Es difícil comparar dos modelos con baja precisión y alta recuperación o viceversa. La puntuación F1 ayuda a medir la recuperación y la precisión al mismo tiempo. Utiliza la media armónica en lugar de la media aritmética al castigar más los valores extremos.
Entendiendo la Matriz de Confusión
Digamos que tenemos un problema de clasificación binaria en el que queremos predecir si un paciente tiene cáncer o no, en función de los síntomas (las características) introducidos en el modelo de aprendizaje automático (clasificador).
Como se estudió anteriormente, el lado izquierdo de la matriz de confusión muestra la clase predicha por el clasificador. Mientras tanto, la fila superior de la matriz muestra las etiquetas de clase reales de los ejemplos.
Si el conjunto de problemas tiene más de dos clases, la matriz de confusión simplemente crece por el número respectivo de clases. Por ejemplo, si hay cuatro clases, sería una matriz de 4 x 4.
En palabras simples, no importa el número de clases, el principal seguirá siendo el mismo: el lado izquierdo de la matriz son los valores predichos y el superior los valores reales. Lo que tenemos que comprobar es dónde se cruzan para ver el número de ejemplos predichos para cualquier clase dada frente al número real de ejemplos para esa clase.
Si bien puede calcular manualmente métricas como la matriz de confusión, la precisión y la recuperación, la mayoría de las bibliotecas de aprendizaje automático, como Scikit-learn para Python, tienen métodos integrados para obtener estas métricas.
Generando una matriz de confusión en Scikit Learn
Ya hemos cubierto la teoría sobre el funcionamiento de la matriz de confusión, aquí compartiremos los comandos de Python para obtener la salida de cualquier clasificador como una matriz.
Para obtener la matriz de confusión para nuestro clasificador, necesitamos crear una instancia de la matriz de confusión que importamos de Sklearn y pasarle los argumentos relevantes: los valores verdaderos y nuestras predicciones.
de sklearn.metrics importar confusion_matrix
c_matrix = confusion_matrx (prueba_y, predicciones)
imprimir (c_matrix)
Resumen
En un breve resumen, analizamos:
-
precisión
-
problemas que puede traer a la mesa
-
matriz de confusión para comprender mejor el modelo de clasificación
-
precisión y recuperación y escenario sobre dónde usarlos
Nos inclinamos hacia el uso de la precisión porque todos tienen una idea de lo que significa. Es necesario aumentar el uso de métricas más adecuadas, como la recuperación y la precisión, que pueden parecer extrañas. Ahora tiene una idea intuitiva de por qué funcionan mejor para algunos problemas, como las tareas de clasificación desequilibradas.

Las estadísticas nos proporcionan definiciones formales para evaluar estas medidas. Nuestro trabajo como científico de datos consiste en conocer las herramientas adecuadas para el trabajo correcto, y esto conlleva la necesidad de ir más allá de la precisión al trabajar con modelos de clasificación.
El uso de recuperación, precisión y puntuación F1 (media armónica de precisión y recuperación) nos permite evaluar modelos de clasificación y también nos hace pensar en usar solo la precisión de un modelo, especialmente para problemas desequilibrados. Como hemos aprendido, la precisión no es una herramienta de evaluación útil en varios problemas, así que implementemos otras medidas agregadas a nuestro arsenal para evaluar el modelo.
Pantalón Rohit





