Desde la última década, hemos visto a la GPU entrar en escena con más frecuencia en campos como HPC (Computación de alto rendimiento) y el campo más popular, es decir, los juegos. Las GPU han mejorado año tras año y ahora son capaces de hacer cosas increíblemente geniales, pero en los últimos años han captado aún más atención debido al aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....

Como los modelos de aprendizaje profundo pasan una gran cantidad de tiempo en el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., incluso las CPU potentes no eran lo suficientemente eficientes para manejar tantos cálculos en un momento dado y esta es el área donde las GPU simplemente superaron a las CPU debido a su paralelismo. Pero antes de sumergirnos en la profundidad, primero comprendamos algunas cosas sobre la GPU.
¿Qué es la GPU?
Una GPU o ‘Unidad de procesamiento de gráficos’ es una versión mini de una computadora completa, pero solo dedicada a una tarea específica. Es diferente a una CPU que realiza múltiples tareas al mismo tiempo. La GPU viene con su propio procesador que está integrado en su propia placa base junto con v-ram o video ram, y también un diseño térmico adecuado para ventilación y enfriamiento.
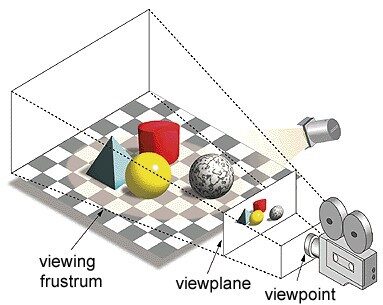
En el término ‘Unidad de procesamiento de gráficos’, ‘Gráficos’ se refiere a renderizar una imagen en coordenadas específicas en un espacio 2d o 3D. Una ventana o punto de vista es la perspectiva de un espectador de mirar un objeto según el tipo de proyección utilizada. La rasterización y el trazado de rayos son algunas de las formas de renderizar escenas en 3D, ambos conceptos se basan en un tipo de proyección llamada proyección en perspectiva. ¿Qué es la proyección en perspectiva?
En resumen, es la forma en que se forma una imagen en un plano de vista o lienzo donde las líneas paralelas convergen a un punto convergente llamado ‘centro de proyección’ también a medida que el objeto se aleja del punto de vista parece ser más pequeño , exactamente cómo se retratan nuestros ojos en el mundo real y esto también ayuda a comprender la profundidad de una imagen, esa es la razón por la que produce imágenes realistas.
Además, las GPU también procesan geometría compleja, vectores, fuentes de luz o iluminaciones, texturas, formas, etc. Como ahora tenemos una idea básica sobre la GPU, entendamos por qué se usa mucho para el aprendizaje profundo.
¿Por qué las GPU son mejores para el aprendizaje profundo?
Una de las características más admiradas de una GPU es la capacidad de calcular procesos en paralelo. Este es el punto donde el concepto de computación paralela entra en acción. Una CPU en general completa su tarea de manera secuencial. Una CPU se puede dividir en núcleos y cada núcleo realiza una tarea a la vez. Supongamos que una CPU tiene 2 núcleos. Luego, dos procesos de tareas diferentes pueden ejecutarse en estos dos núcleos, logrando así la multitarea.
Pero aún así, estos procesos se ejecutan en serie.
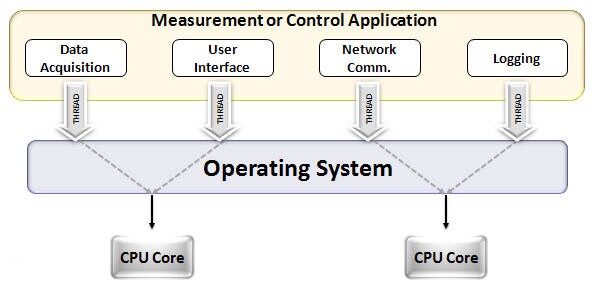
Esto no significa que las CPU no sean lo suficientemente buenas. De hecho, las CPU son realmente buenas para manejar diferentes tareas relacionadas con diferentes operaciones como manejar sistemas operativos, entregar hojas de cálculo, reproducir videos HD, extraer archivos zip grandes, todo al mismo tiempo. Estas son algunas de las cosas que una GPU simplemente no puede hacer.
¿Dónde está la diferencia?
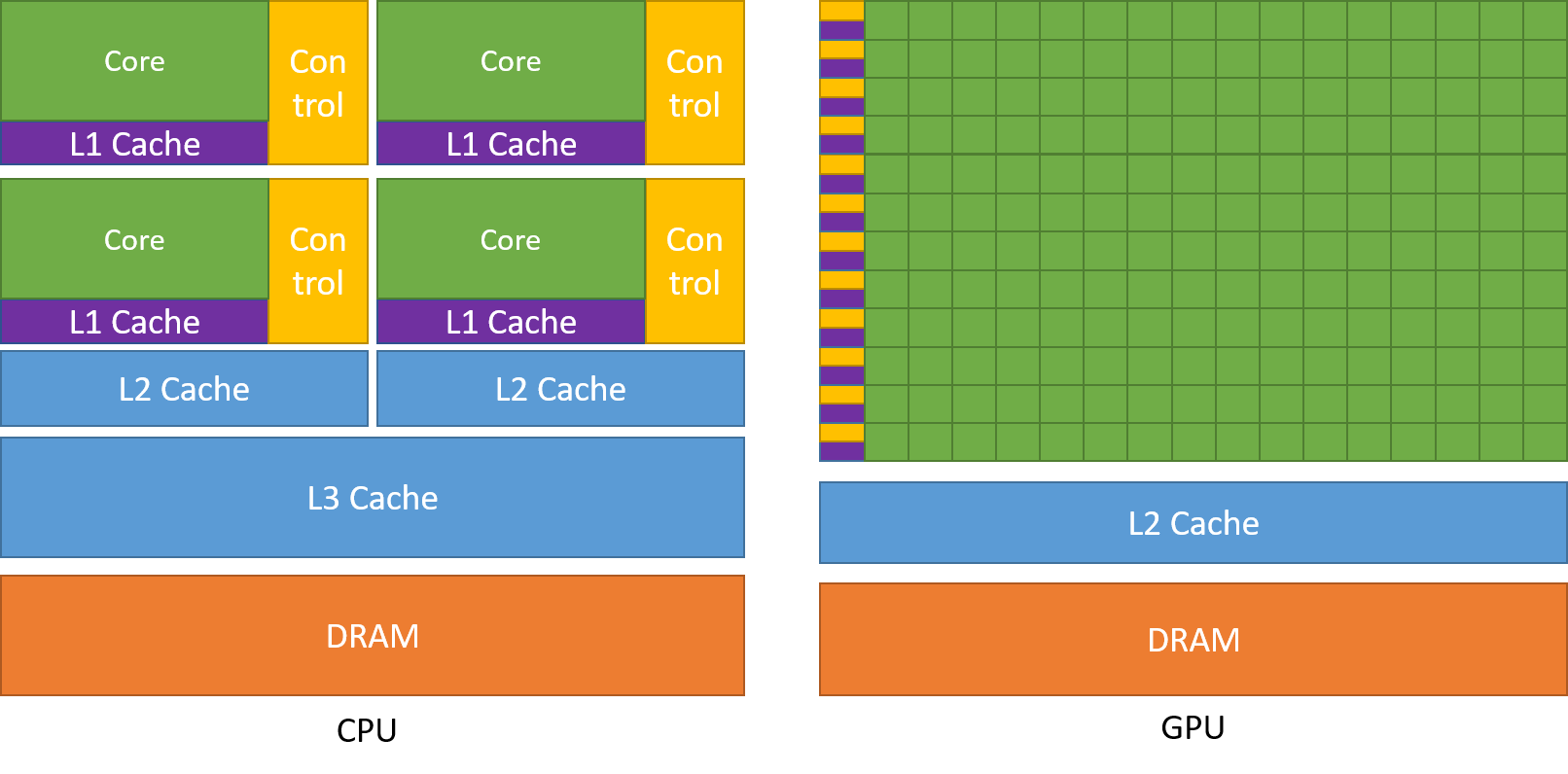
Como se mencionó anteriormente, una CPU se divide en múltiples núcleos para que puedan realizar múltiples tareas al mismo tiempo, mientras que la GPU tendrá cientos y miles de núcleos, todos los cuales están dedicados a una sola tarea. Estos son cálculos simples que se realizan con más frecuencia y son independientes entre sí. Y ambos almacenan los datos requeridos con frecuencia en su respectiva memoria caché, siguiendo así el principio de ‘referencia de localidad‘.
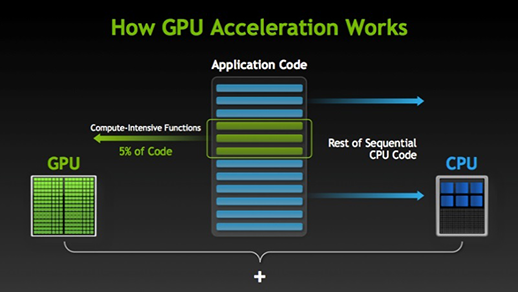
Hay muchos programas y juegos que pueden aprovechar las GPU para su ejecución. La idea detrás de esto es hacer que algunas partes de la tarea o el código de la aplicación sean paralelas, pero no todos los procesos. Esto se debe a que la mayoría de los procesos de la tarea solo deben ejecutarse de manera secuencial. Por ejemplo, iniciar sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... en un sistema o aplicación no necesita ser paralelo.
Cuando hay parte de la ejecución que se puede hacer en paralelo, simplemente se cambia a GPU para su procesamiento, donde al mismo tiempo se ejecuta la tarea secuencial en la CPU, luego ambas partes de la tarea se combinan nuevamente.
En el mercado de GPU, hay dos jugadores principales, es decir, AMD y Nvidia. Las GPU de Nvidia se utilizan ampliamente para el aprendizaje profundo porque tienen un amplio soporte en el software del foro, los controladores, CUDA y cuDNN. Entonces, en términos de inteligencia artificial y aprendizaje profundo, Nvidia es pionera durante mucho tiempo.
Se dice que las redes neuronales son vergonzosamente paralelo, lo que significa que los cálculos en redes neuronales se pueden ejecutar en paralelo fácilmente y son independientes entre sí.
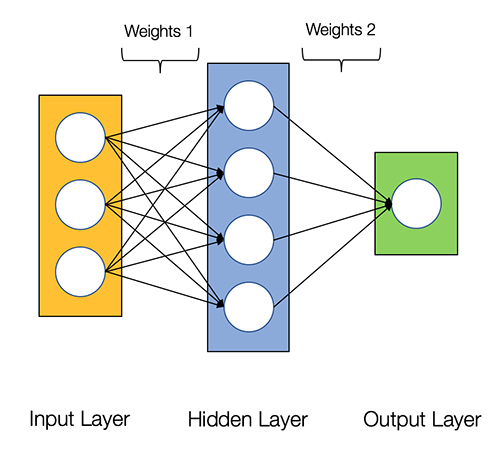
Algunos cálculos como el cálculo de pesos y funciones de activación de cada capa, la retropropagación se pueden realizar en paralelo. También hay muchos artículos de investigación disponibles al respecto.
Las GPU de Nvidia vienen con núcleos especializados conocidos como CUDA núcleos que ayudan a acelerar el aprendizaje profundo.
¿Qué es CUDA?
CUDA significa ‘Compute Unified Device Architecture’ que se lanzó en el año 2007, es una forma en la que puede lograr la computación en paralelo y obtener el máximo rendimiento de la potencia de su GPU de una manera optimizada, lo que da como resultado un rendimiento mucho mejor al ejecutar tareas.
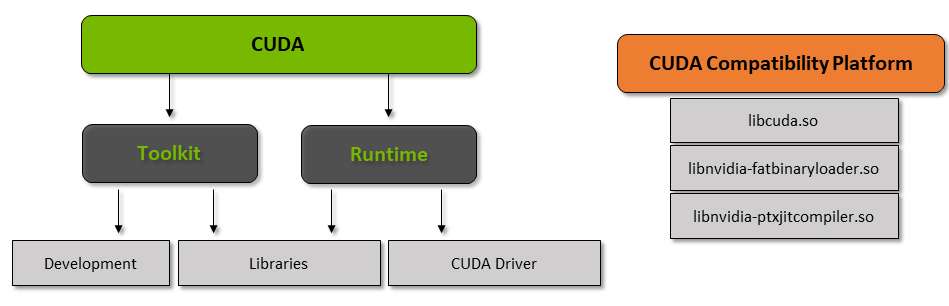
El kit de herramientas CUDA es un paquete completo que consta de un entorno de desarrollo que se utiliza para crear aplicaciones que utilizan GPU. Este kit de herramientas contiene principalmente el compilador, el depurador y las bibliotecas de c / c ++. Además, el tiempo de ejecución de CUDA tiene sus controladores para que pueda comunicarse con la GPU. CUDA también es un lenguaje de programación que está diseñado específicamente para instruir a la GPU para realizar una tarea. También se conoce como programación de GPU.
A continuación se muestra un programa simple de hola mundo solo para tener una idea de cómo se ve el código CUDA.
/* hello world program in cuda * #include<stdio.h> #include<stdlib.h> #include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program"); }int main() { printf("From main!n"); demo<<<1,1>>>(); return 0; }

¿Qué es cuDNN?

cuDNN es una biblioteca de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... que está optimizada para GPU y puede aprovechar al máximo la GPU de Nvidia. Esta biblioteca consiste en la implementación de convolución, propagación hacia adelante y hacia atrás, funciones de activación y agrupación. Es una biblioteca imprescindible sin la cual no puede usar GPU para entrenar redes neuronales.
¡Un gran salto con los núcleos Tensor!
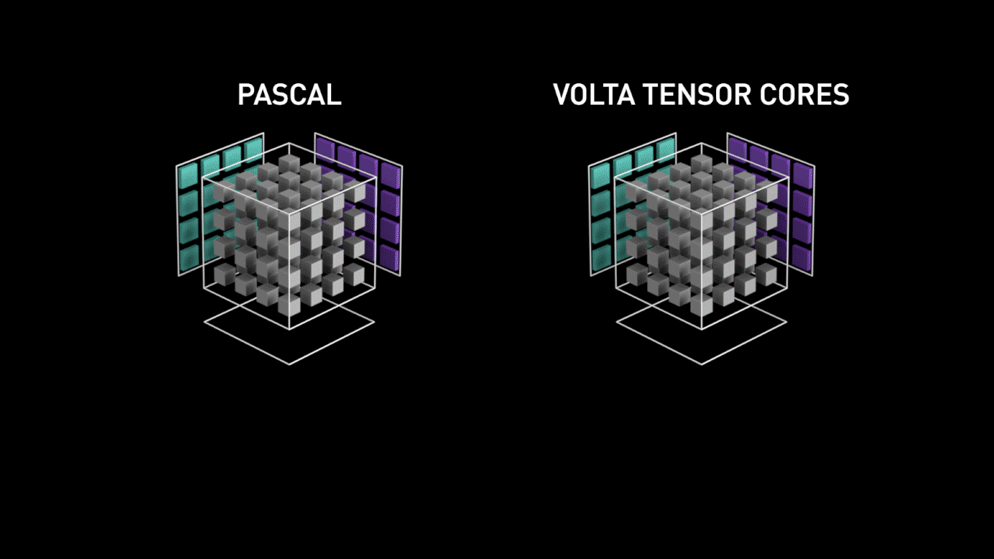
En el año 2018, Nvidia lanzó una nueva línea de sus GPU, es decir, la serie 2000. También llamadas RTX, estas tarjetas vienen con núcleos tensores dedicados al aprendizaje profundo y basados en la arquitectura Volta.
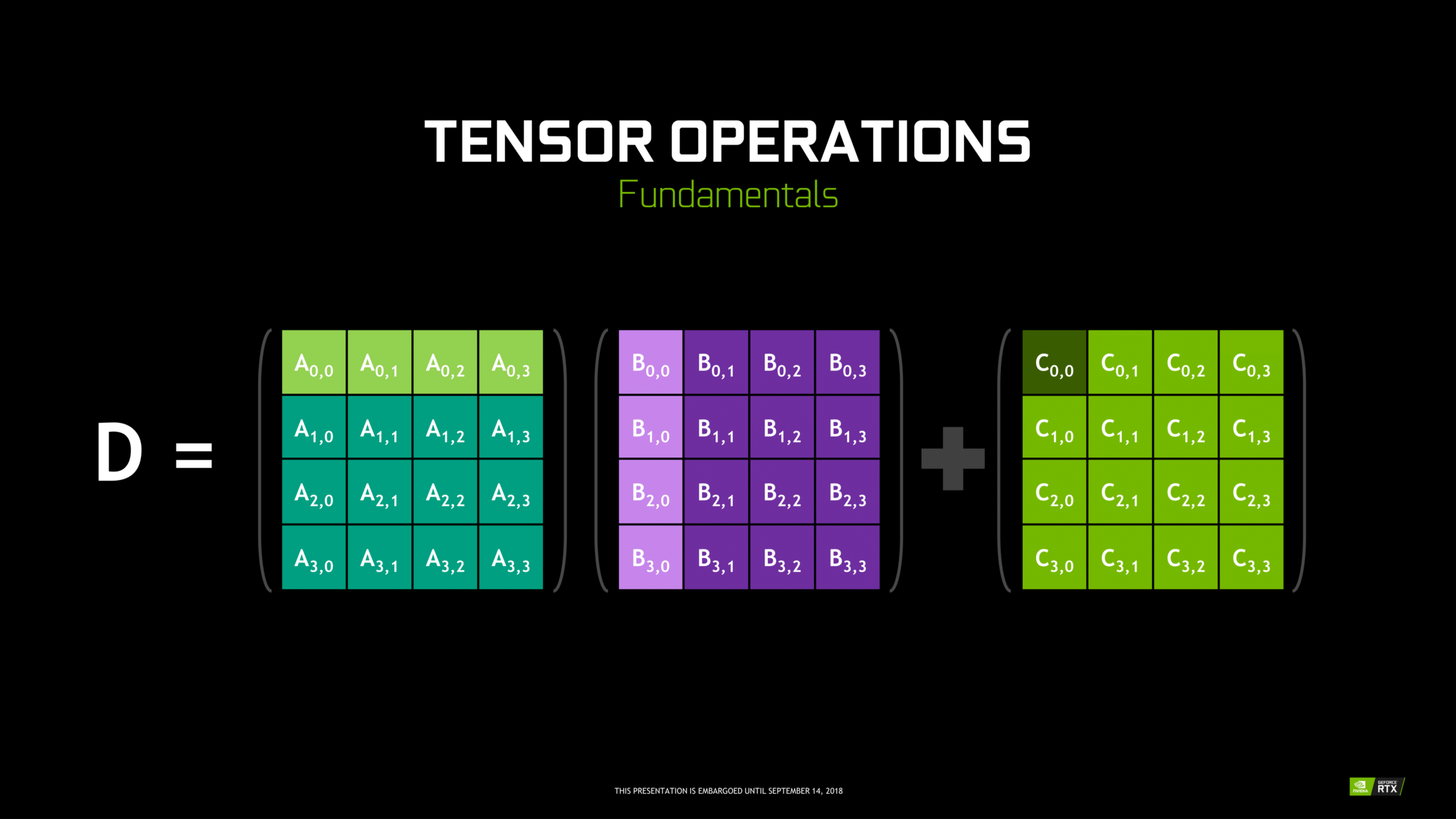
Los núcleos tensores son núcleos particulares que realizan la multiplicación de matrices 4 x 4 FP16 y la suma con 4 x 4 matriz FP16 o FP32 en media precisión, la salida dará como resultado una matriz 4 x 4 FP16 o FP32 con total precisión.
Nota: ‘FP’ significa punto flotante para comprender más sobre el punto flotante y la precisión, compruebe esto Blog.
Como afirma Nvidia, los núcleos tensoriales de nueva generación basados en la arquitectura volta son mucho más rápidos que los núcleos CUDA basados en la arquitectura Pascal. Esto dio un gran impulso al aprendizaje profundo.
Al momento de escribir este blog, Nvidia anunció la última serie 3000 de su línea de GPU que viene con arquitectura Ampere. En esto, mejoraron el rendimiento de los núcleos tensoriales en 2x. También trae nuevos valores de precisión como TF32 (tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos.... float 32), FP64 (punto flotante 64). El TF32 funciona igual que el FP32 pero con una aceleración de hasta 20x, como resultado de todo esto, Nvidia afirma que el tiempo de inferencia o entrenamiento de los modelos se reducirá de semanas a horas.
AMD frente a Nvidia

AMD Las GPU son decentes para los juegos, pero tan pronto como el aprendizaje profundo entra en escena, simplemente Nvidia está muy por delante. No significa que las GPU de AMD sean malas. Es debido a la optimización del software y los controladores que no se actualizan activamente, en el lado de Nvidia tienen mejores controladores con actualizaciones frecuentes y en la parte superior de ese CUDA, cuDNN ayuda a acelerar el cálculo.
Algunas bibliotecas conocidas como Tensorflow, compatibilidad con PyTorch para CUDA. Significa que se pueden utilizar GPU de nivel de entrada de la serie GTX 1000. Por el lado de AMD, tiene muy poco soporte de software para sus GPU. En el lado del hardware, Nvidia ha introducido núcleos tensores dedicados. AMD tiene ROCm para la aceleración, pero no es bueno como núcleos tensoriales, y muchas bibliotecas de aprendizaje profundo no son compatibles con ROCm. Durante los últimos años, no se notó ningún gran salto en términos de rendimiento.
Debido a todos estos puntos, Nvidia simplemente sobresale en el aprendizaje profundo.
Resumen
Para concluir de todo lo que hemos aprendido, está claro que a partir de ahora Nvidia es el líder del mercado en términos de GPU, pero realmente espero que incluso AMD se ponga al día en el futuro o al menos haga algunas mejoras notables en la próxima línea de sus GPU. ya que ya están haciendo un gran trabajo con respecto a sus CPU, es decir, la serie Ryzen.
El alcance de las GPU en los próximos años es enorme a medida que realizamos nuevas innovaciones y avances en el aprendizaje profundo, el aprendizaje automático y la HPC. La aceleración de GPU siempre será útil para que muchos desarrolladores y estudiantes ingresen a este campo, ya que sus precios también se están volviendo más asequibles. También gracias a la amplia comunidad que también contribuye al desarrollo de IA y HPC.

Prathmesh Patil
Entusiasta del aprendizaje automático, ciencia de datos, desarrollador de Python.
LinkedIn: https://www.linkedin.com/in/prathmesh





