Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Esto ha estado trabajando convencionalmente con el plan comercial y las tendencias de noticias. Con la llegada de la ciencia de datos y el aprendizaje automático, se han diseñado varios enfoques de investigación para automatizar este proceso manual. Este proceso de negociación automatizado ayudará a dar sugerencias en el momento adecuado con mejores cálculos. Una estrategia de negociación automatizada que ofrezca el máximo beneficio es muy deseable para los fondos mutuos y los fondos de cobertura. El tipo de rendimiento rentable que se espera conllevará cierto riesgo potencial. Diseñar una estrategia comercial automatizada rentable es una tarea compleja.
Todo ser humano quiere ganar su máximo potencial en el mercado de valores. Es muy importante diseñar una estrategia equilibrada y de bajo riesgo que pueda beneficiar a la mayoría de las personas. Uno de estos enfoques habla sobre el uso de agentes de aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas.... para proporcionarnos estrategias comerciales automatizadas basadas en datos históricos.
Aprendizaje reforzado
El aprendizaje por refuerzo es un tipo de aprendizaje automático en el que hay entornos y agentes. Estos agentes toman acciones para maximizar las recompensas. El aprendizaje por refuerzo tiene un potencial enorme cuando se utiliza para simulaciones para entrenar un modelo de IA. No hay una etiqueta asociada con ningún dato, el aprendizaje por refuerzo puede aprender mejor con muy pocos puntos de datos. Todas las decisiones, en este caso, se toman de forma secuencial. El mejor ejemplo se encontraría en Robótica y Juegos.
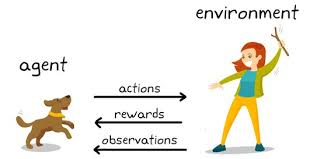
Q – Aprendizaje
Q-learning es un algoritmo de aprendizaje por refuerzo sin modelos. Informa al agente qué acción emprender según las circunstancias. Es un método basado en valores que se utiliza para proporcionar información a un agente para la acción inminente. Se considera un algoritmo fuera de la política, ya que la función q-learning aprende de acciones que están fuera de la política actual, como tomar acciones aleatorias y, por lo tanto, no se necesita una política.
Q aquí significa Calidad. La calidad se refiere a la calidad de la acción en cuanto a qué tan beneficiosa será esa recompensa de acuerdo con la acción tomada. Se crea una Q-table con dimensiones [state,action]Un agente interactúa con el medio ambiente en cualquiera de las dos formas: explotar y explorar. Una opción de explotación sugiere que se consideren todas las acciones y se tome la que le dé el máximo valor al medio ambiente. Una opción de exploración es aquella en la que se considera una acción aleatoria sin considerar la recompensa máxima futura.
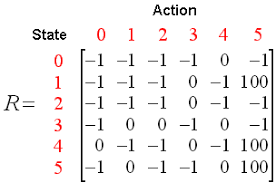

Q de st y at está representado por una fórmula que calcula la recompensa futura descontada máxima cuando se realiza una acción en un estado s.
La función definida nos proporcionará la recompensa máxima al final del número n de ciclos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... o iteraciones.
El comercio puede tener las siguientes llamadas: comprar, vender o retener
Q-learning calificará todas y cada una de las acciones y se seleccionará la que tenga el valor máximo. Q-Learning se basa en aprender los valores de la Q-table. Funciona bien sin las funciones de recompensa y las probabilidades de transición de estado.
Aprendizaje reforzado en el comercio de acciones
El aprendizaje por refuerzo puede resolver varios tipos de problemas. El comercio es una tarea continua sin ningún punto final. La negociación también es un proceso de decisión de Markov parcialmente observable, ya que no tenemos información completa sobre los comerciantes en el mercado. Como no conocemos la función de recompensa y la probabilidad de transición, utilizamos el aprendizaje por refuerzo sin modelo, que es Q-Learning.
Pasos para ejecutar un agente de RL:
-
Instalar bibliotecas
-
Obtener los datos
-
Definir el agente de Q-Learning
-
Entrena al agente
-
Prueba al agente
-
Trazar las señales
Instalar bibliotecas
Instale e importe las bibliotecas de finanzas necesarias de NumPy, pandas, matplotlib, seaborn y yahoo.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set() !pip install yfinance --upgrade --no-cache-dir from pandas_datareader import data as pdr import fix_yahoo_finance as yf from collections import deque import random Import tensorflow.compat.v1 as tf tf.compat.v1.disable_eager_execution()
Obtener los datos
Utilice la biblioteca de Yahoo Finance para obtener los datos de una acción en particular. Las acciones utilizadas aquí para nuestro análisis son las acciones de Infosys.
yf.pdr_override()
df_full = pdr.get_data_yahoo("INFY", start="2018-01-01").reset_index()
df_full.to_csv(‘INFY.csv',index=False)
df_full.head()
Este código creará un marco de datos llamado df_full que contendrá los precios de las acciones de INFY en el transcurso de 2 años.
Definir el agente de Q-Learning
La primera función es la clase Agente define el tamaño del estado, tamaño de la ventana, tamaño del lote, deque que es la memoria utilizada, inventario como una lista. También define algunas variables estáticas como épsilon, decaimiento, gamma, etc. Se definen dos capas de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... para la compra, retención y venta de llamadas. También se utiliza GradientDescentOptimizer.
El Agente tiene funciones definidas para opciones de compra y venta. La función get_state y act hace uso de la red neuronal para generar el siguiente estado de la red neuronal. Las recompensas se calculan posteriormente sumando o restando el valor generado al ejecutar la opción call. La acción tomada en el siguiente estado está influenciada por la acción tomada en el estado anterior. 1 se refiere a una llamada de compra, mientras que 2 se refiere a una llamada de venta. En cada iteración, el estado se determina sobre la base del cual se toma una acción que comprará o venderá algunas acciones. Las recompensas generales se almacenan en la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de beneficio total.
df= df_full.copy()
name="Q-learning agent"
class Agent:
def __init__(self, state_size, window_size, trend, skip, batch_size):
self.state_size = state_size
self.window_size = window_size
self.half_window = window_size // 2
self.trend = trend
self.skip = skip
self.action_size = 3
self.batch_size = batch_size
self.memory = deque(maxlen = 1000)
self.inventory = []
self.gamma = 0.95
self.epsilon = 0.5
self.epsilon_min = 0.01
self.epsilon_decay = 0.999
tf.reset_default_graph()
self.sess = tf.InteractiveSession()
self.X = tf.placeholder(tf.float32, [None, self.state_size])
self.Y = tf.placeholder(tf.float32, [None, self.action_size])
feed = tf.layers.dense(self.X, 256, activation = tf.nn.relu)
self.logits = tf.layers.dense(feed, self.action_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.GradientDescentOptimizer(1e-5).minimize(
self.cost
)
self.sess.run(tf.global_variables_initializer())
def act(self, state):
if random.random() <= self.epsilon:
return random.randrange(self.action_size)
return np.argmax(
self.sess.run(self.logits, feed_dict = {self.X: state})[0]
)
def get_state(self, t):
window_size = self.window_size + 1
d = t - window_size + 1
block = self.trend[d : t + 1] if d >= 0 else -d * [self.trend[0]] + self.trend[0 : t + 1]
res = []
for i in range(window_size - 1):
res.append(block[i + 1] - block[i])
return np.array([res])
def replay(self, batch_size):
mini_batch = []
l = len(self.memory)
for i in range(l - batch_size, l):
mini_batch.append(self.memory[i])
replay_size = len(mini_batch)
X = np.empty((replay_size, self.state_size))
Y = np.empty((replay_size, self.action_size))
states = np.array([a[0][0] for a in mini_batch])
new_states = np.array([a[3][0] for a in mini_batch])
Q = self.sess.run(self.logits, feed_dict = {self.X: states})
Q_new = self.sess.run(self.logits, feed_dict = {self.X: new_states})
for i in range(len(mini_batch)):
state, action, reward, next_state, done = mini_batch[i]
target = Q[i]
target[action] = reward
if not done:
target[action] += self.gamma * np.amax(Q_new[i])
X[i] = state
Y[i] = target
cost, _ = self.sess.run(
[self.cost, self.optimizer], feed_dict = {self.X: X, self.Y: Y}
)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return cost
def buy(self, initial_money):
starting_money = initial_money
states_sell = []
states_buy = []
inventory = []
state = self.get_state(0)
for t in range(0, len(self.trend) - 1, self.skip):
action = self.act(state)
next_state = self.get_state(t + 1)
if action == 1 and initial_money >= self.trend
inventory.append(self.trend
initial_money -= self.trend
states_buy.append
print('day %d: buy 1 unit at price %f, total balance %f'% (t, self.trend
elif action == 2 and len(inventory):
bought_price = inventory.pop(0)
initial_money += self.trend
states_sell.append
try:
invest = ((close
except:
invest = 0
print(
'day %d, sell 1 unit at price %f, investment %f %%, total balance %f,'
% (t, close
)
state = next_state
invest = ((initial_money - starting_money) / starting_money) * 100
total_gains = initial_money - starting_money
return states_buy, states_sell, total_gains, invest
def train(self, iterations, checkpoint, initial_money):
for i in range(iterations):
total_profit = 0
inventory = []
state = self.get_state(0)
starting_money = initial_money
for t in range(0, len(self.trend) - 1, self.skip):
action = self.act(state)
next_state = self.get_state(t + 1)
if action == 1 and starting_money >= self.trend
inventory.append(self.trend
starting_money -= self.trend
elif action == 2 and len(inventory) > 0:
bought_price = inventory.pop(0)
total_profit += self.trend
starting_money += self.trend
invest = ((starting_money - initial_money) / initial_money)
self.memory.append((state, action, invest,
next_state, starting_money < initial_money))
state = next_state
batch_size = min(self.batch_size, len(self.memory))
cost = self.replay(batch_size)
if (i+1) % checkpoint == 0:
print('epoch: %d, total rewards: %f.3, cost: %f, total money: %f'%(i + 1, total_profit, cost,
starting_money))
Entrena al agente
Una vez definido el agente, inicialícelo. Especifique el número de iteraciones, dinero inicial, etc. para capacitar al agente para que decida las opciones de compra o venta.
close = df.Close.values.tolist()
initial_money = 10000
window_size = 30
skip = 1
batch_size = 32
agent = Agent(state_size = window_size,
window_size = window_size,
trend = close,
skip = skip,
batch_size = batch_size)
agent.train(iterations = 200, checkpoint = 10, initial_money = initial_money)
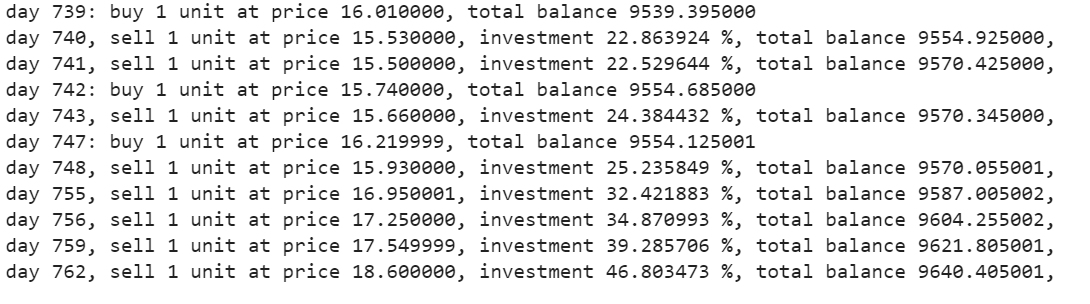
Producción –

Prueba al agente
La función de compra devolverá las cifras de compra, venta, beneficio e inversión.
states_buy, states_sell, total_gains, invest = agent.buy(initial_money = initial_money)
Trazar las llamadas
Grafique las ganancias totales frente a las cifras invertidas. Todas las llamadas de compra y venta se han marcado adecuadamente de acuerdo con las opciones de compra / venta sugeridas por la red neuronal.
fig = plt.figure(figsize = (15,5))
plt.plot(close, color="r", lw=2.)
plt.plot(close, '^', markersize=10, color="m", label="buying signal", markevery = states_buy)
plt.plot(close, 'v', markersize=10, color="k", label="selling signal", markevery = states_sell)
plt.title('total gains %f, total investment %f%%'%(total_gains, invest))
plt.legend()
plt.savefig(name+'.png')
plt.show()
Producción –
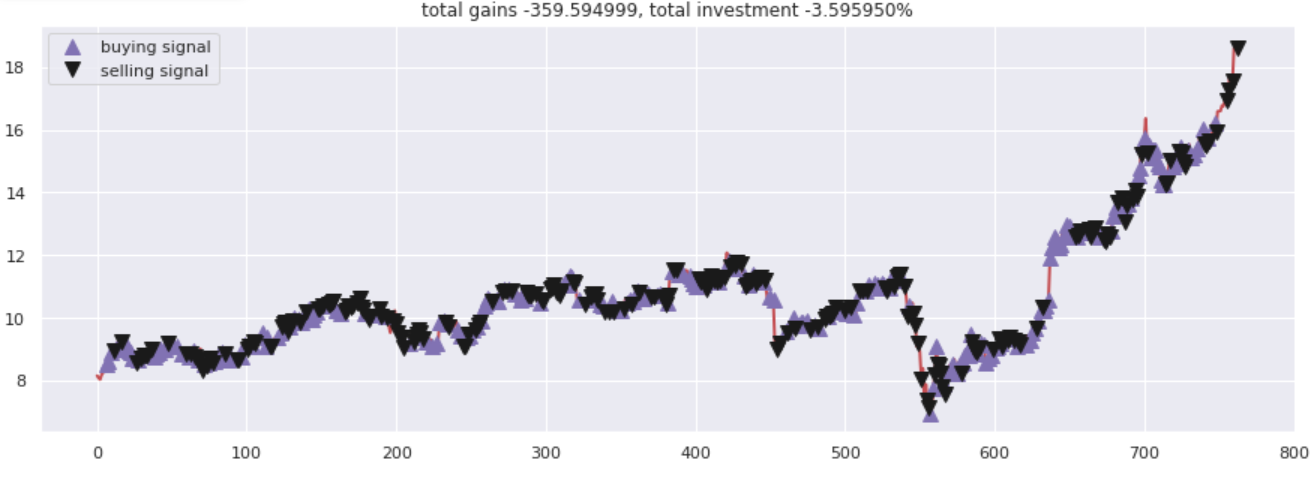
Notas finales
Q-Learning es una técnica que le ayuda a desarrollar una estrategia comercial automatizada. Se puede utilizar para experimentar con las opciones de compra o venta. Hay muchos más agentes comerciales de aprendizaje por refuerzo con los que se puede experimentar. Intente jugar con los diferentes tipos de agentes de RL con diferentes acciones.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





