Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
La ciencia de datos es un campo emergente con numerosas oportunidades laborales. Todos debemos haber oído hablar de las mejores habilidades en ciencia de datos. Para empezar, la habilidad más fácil y esencial que todo aspirante a la ciencia de datos debe adquirir es SQL.
Hoy en día, la mayoría de las empresas se orientan hacia los datos. Estos datos se almacenan en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... y se gestionan y procesan a través de un sistema de gestión de bases de datos. DBMS hace que nuestro trabajo sea tan fácil y organizado. Por lo tanto, es esencial integrar el lenguaje de programación más popular con la increíble herramienta DBMS.
SQL es el lenguaje de programación más utilizado al trabajar con bases de datos y es compatible con varios sistemas de bases de datos relacionales, como MySQL, SQL Server y Oracle. Sin embargo, el estándar SQL tiene algunas características que se implementan de manera diferente en diferentes sistemas de bases de datos. Por tanto, SQL se convierte en uno de los conceptos más importantes a aprender en este campo de la ciencia de datos.
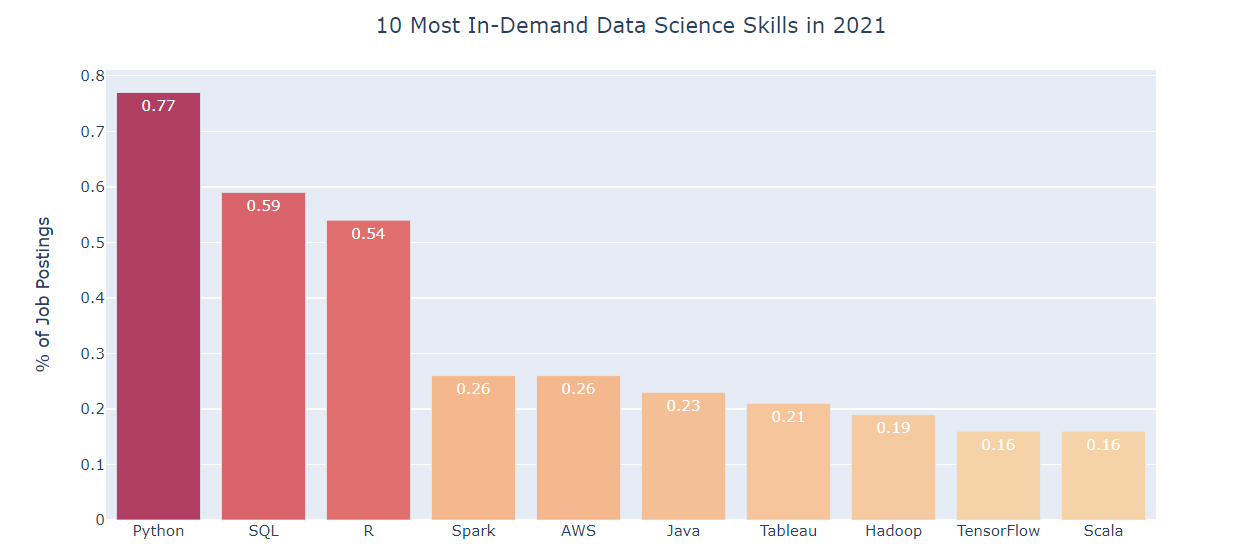
Fuente de imagen: KDnuggets
Necesidad de SQL en la ciencia de datos
SQL (Structured Query Language) se utiliza para realizar diversas operaciones en los datos almacenados en las bases de datos, como actualizar registros, eliminar registros, crear y modificar tablas, vistas, etc. SQL también es el estándar para las plataformas de big data actuales que usan SQL como su API clave para sus bases de datos relacionales.
La ciencia de datos es el estudio integral de datos. Para trabajar con datos, necesitamos extraerlos de la base de datos. Aquí es donde SQL entra en escena. La gestión de bases de datos relacionales es una parte crucial de la ciencia de datos. Un científico de datos puede controlar, definir, manipular, crear y consultar la base de datos mediante comandos SQL.
Muchas industrias modernas han equipado la gestión de datos de sus productos con tecnología NoSQL, pero SQL sigue siendo la opción ideal para muchas herramientas de inteligencia empresarial y operaciones en la oficina.
Muchas de las plataformas de bases de datos se basan en SQL. Es por eso que se ha convertido en un estándar para muchos sistemas de bases de datos. Los sistemas de big data modernos como Hadoop, Spark también utilizan SQL solo para mantener los sistemas de bases de datos relacionales y procesar datos estructurados.
Podemos decir eso:
1. Un científico de datos necesita SQL para manejar datos estructurados. Como los datos estructurados se almacenan en bases de datos relacionales. Por lo tanto, para consultar estas bases de datos, un científico de datos debe tener un buen conocimiento de los comandos SQL.
Las plataformas de Big Data como Hadoop y Spark proporcionan una extensión para realizar consultas mediante comandos SQL para manipular.
3.SQL es la herramienta estándar para experimentar con datos mediante la creación de entornos de prueba.
4. Para realizar operaciones analíticas con los datos que se almacenan en bases de datos relacionales como Oracle, Microsoft SQL, MySQL, necesitamos SQL.
5. SQL también es una herramienta esencial para la preparación y el procesamiento de datos. Por lo tanto, al tratar con diversas herramientas de Big Data, utilizamos SQL.
Elementos clave de SQL para la ciencia de datos
A continuación se muestran los aspectos clave de SQL que son más útiles para la ciencia de datos. Todos los aspirantes a científicos de datos deben conocer estas habilidades y características necesarias de SQL.
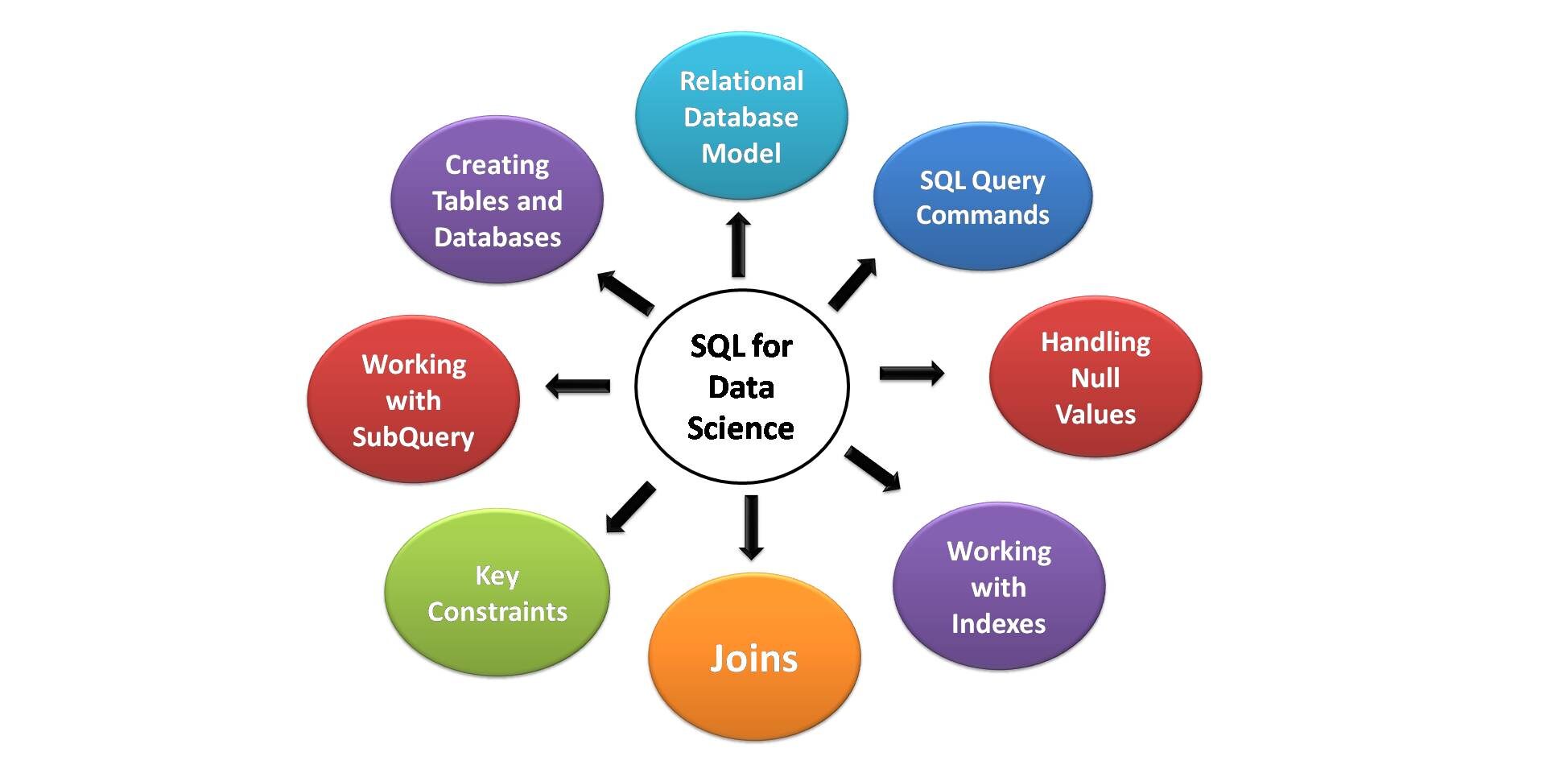
Fuente de imagen: Por mi
Introducción a SQL con Python
Como todos sabemos, SQL es la herramienta de administración de bases de datos más utilizada y Python es el lenguaje de ciencia de datos más popular por su flexibilidad y amplia gama de bibliotecas. Hay varias formas de usar SQL con Python. Python proporciona varias bibliotecas que se desarrollan y se pueden utilizar para este propósito. SQLite, PostgreSQL, y MySQL son ejemplos de estas bibliotecas.
Por que usar SQL con Python
Hay muchos casos de uso en los que los científicos de datos desean conectar Python a SQL. Los científicos de datos necesitan conectar una base de datos SQL para poder almacenar los datos provenientes de la aplicación web. También ayuda a comunicarse entre diferentes fuentes de datos.
No es necesario cambiar entre diferentes lenguajes de programación para la gestión de datos. Hace que el trabajo de los científicos de datos sea más conveniente. Podrán usar sus habilidades en Python para manipular datos almacenados en una base de datos SQL. No necesitan un archivo CSV.
MySQL con Python
MySQL es un sistema de administración de bases de datos basado en servidor. Un servidor MySQL puede tener varias bases de datos. Una base de datos MySQL consiste en un proceso de dos pasos para crear una base de datos:
1. Establezca una conexión a un servidor MySQL.
2. Ejecute consultas independientes para crear la base de datos y procesar los datos.
Comencemos con MySQL con Python
Primero, crearemos una conexión entre el servidor MySQL y MySQL DB. Para ello, definiremos una función que establecerá una conexión con el servidor de la base de datos MySQL y devolverá el objeto de conexión:
!pip install mysql-connector-python
import mysql.connector from mysql.connector import Error
def create_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("Connection to MySQL DB successful")
except Error as e:
print(f"The error '{e}' occurred")
return connection
connection = create_connection("localhost", "root", "")
En el código anterior, hemos definido una función create_connection () que acepta los siguientes tres parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto....:
1. nombre_host
2. nombre de usuario
3. contraseña de usuario
Mysql.connector es un módulo SQL de Python que contiene un método .connect () que se utiliza para conectarse a un servidor de base de datos MySQL. Cuando se establece la conexión, el objeto de conexión creado se devolverá a la función de llamada.
Hasta ahora, la conexión se estableció correctamente, ahora creemos una base de datos.
#we have created a function to create database that contions two parameters #connection and query defcreate_database(connection,query): #now we are creating an object cursor to execute SQL queries cursor=connection.cursor() try: #query to be executed will be passed in cursor.execute() in string form cursor.execute(query) print("Database created successfully") exceptErrorase: print(f"The error '{e}' occurred")
#now we are creating a database named example_app create_database_query="CREATE DATABASE example_app" create_database(connection,create_database_query)
#now will create database example_app on database server #and also cretae connection between database and server defcreate_connection(host_name,user_name,user_password,db_name): connection=None try: connection=mysql.connector.connect( host=host_name, user=user_name, passwd=user_password, database=db_name ) print("Connection to MySQL DB successful") exceptErrorase: print(f"The error '{e}' occurred") returnconnection
#calling thecreate_connection()and connects to theexample_appdatabase. connection=create_connection("localhost","root","","example_app")
SQLite
SQLite es probablemente la base de datos más sencilla que podemos conectar a una aplicación de Python, ya que es un módulo integrado, no necesitamos instalar ningún módulo externo de Python SQL. De forma predeterminada, la instalación de Python contiene una biblioteca SQL de Python llamada sqlite3 que se puede usar para interactuar con una base de datos SQLite.
SQLite es una base de datos sin servidor. Lee y escribe datos en un archivo. ¡Eso significa que ni siquiera necesitamos instalar y ejecutar un servidor SQLite para realizar operaciones de base de datos como MySQL y PostgreSQL!
Usemos sqlite3 para conectarse a una base de datos SQLite en Python:
importsqlite3 fromsqlite3importError
defcreate_connection(path): connection=None try: connection=sqlite3.connect(path) print("Connection to SQLite DB successful")
exceptErrorase: print(f"The error '{e}' occurred") returnconnection
En el código anterior, hemos importado sqlite3 y la clase Error del módulo. Luego defina una función llamada .create_connection () que aceptará la ruta a la base de datos SQLite. Luego .connect () del módulo sqlite3 tomará la ruta de la base de datos SQLite como parámetro. Si la base de datos existe en la ruta especificada en .connect, se establecerá una conexión a la base de datos. De lo contrario, se crea una nueva base de datos en la ruta especificada y luego se establece una conexión.
sqlite3.connect (ruta) devolverá un objeto de conexión, que también fue devuelto por create_connection (). Este objeto de conexión se utilizará para ejecutar consultas SQL en una base de datos SQLite. La siguiente línea de código creará una conexión a la base de datos SQLite:
connection=create_connection("E:example_app.sqlite")
Una vez establecida la conexión podemos ver que el archivo de la base de datos se crea en el directorio raíz y si queremos, también podemos cambiar la ubicación del archivo.
En este artículo, discutimos cómo SQL es esencial para la ciencia de datos y también cómo podemos trabajar con SQL usando Python. Gracias por leer. Hágame saber sus comentarios y sugerencias en la sección de comentarios.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





