Visión general
- Las bases de datos relacionales son ubicuas, pero ¿qué sucede cuando necesita escalar su infraestructura?
- Discutiremos el papel que desempeña Spark SQL en esta situación y entenderemos por qué es una herramienta tan útil para aprender
- Este tutorial también muestra cómo funciona Spark SQL usando un caso de estudio en Python
Introducción
Casi todas las organizaciones utilizan bases de datos relacionales para diversas tareas, desde administrar y rastrear una gran cantidad de información hasta organizar y procesar transacciones. Es uno de los primeros conceptos que nos enseñan en la escuela de programación.
¡Y estemos agradecidos por eso porque este es un engranaje crucial en el conjunto de habilidades de un científico de datos! Simplemente no puede arreglárselas sin saber cómo funcionan las bases de datos. Es un aspecto clave de cualquier aprendizaje automático proyecto.
Lenguaje de consulta estructurado (SQL) es fácilmente el idioma más popular cuando se trata de bases de datos. A diferencia de otros lenguajes de programación, es fácil de aprender y nos ayuda a comenzar con nuestro proceso de extracción de datos. Para la mayoría de los trabajos de ciencia de datos, el dominio de SQL ocupa un lugar más alto que la mayoría de los otros lenguajes de programación.

Pero hay un desafío importante con SQL: tendrá dificultades para que funcione cuando se trata de conjuntos de datos enormes. Aquí es donde Spark SQL toma un asiento delantero y cierra la brecha. Hablaré más sobre esto en la siguiente sección.
Este tutorial práctico le presentará el mundo de Spark SQL, cómo funciona, cuáles son las diferentes características que ofrece y cómo puede implementarlo usando Python. También hablaremos sobre un concepto importante que encontrará a menudo en las entrevistas: el optimizador de catalizador.
¡Empecemos!
Nota: Si es completamente nuevo en el mundo de SQL, le recomiendo encarecidamente el siguiente curso:
Tabla de contenido
- Desafíos con el escalado de bases de datos relacionales
- Descripción general de Spark SQL
- Características de Spark SQL
- ¿Cómo ejecuta Spark SQL una consulta?
- ¿Qué es un Catalyst Optimizer?
- Ejecutando comandos SQL con Spark
- Uso de Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y... a escala
Desafíos con el escalado de bases de datos relacionales
La pregunta es ¿por qué debería aprender Spark SQL? Mencioné esto brevemente antes, pero veámoslo con un poco más de detalle ahora.
Las bases de datos relacionales para un proyecto grande (aprendizaje automático) contienen cientos o quizás miles de tablas y la mayoría de las características de una tabla se asignan a otras características de otras tablas. Estas bases de datos están diseñadas para ejecutarse solo en una sola máquina con el fin de mantener las reglas de las asignaciones de tablas y evitar los problemas de la computación distribuida.
Esto a menudo se convierte en un problema para las organizaciones cuando desean escalar con este diseño. Requeriría hardware más complejo y costoso con una capacidad de procesamiento y almacenamiento significativamente mayor. Como puedes imaginar, La actualización de un hardware más simple a uno más complejo puede ser un gran desafío.
Es posible que una organización tenga que desconectar su sitio web durante algún tiempo para realizar los cambios necesarios. Durante este período, perderían negocios con los nuevos clientes que podrían haber adquirido potencialmente.
Además, a medida que aumenta el volumen de datos, las organizaciones luchan por manejar esta enorme cantidad de datos utilizando bases de datos relacionales tradicionales. Aquí es donde Spark SQL entra en escena.
Descripción general de Spark SQL
««
~
Hadoop y los marcos MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data.... han existido durante mucho tiempo en el análisis de big data. Pero estos marcos requieren muchas operaciones de lectura y escritura en un disco duro, lo que los hace muy costosos en términos de tiempo y velocidad.
Apache Spark es el marco de procesamiento de datos más eficaz en las empresas en la actualidad. Es cierto que el costo de Spark es alto ya que requiere mucha RAM para el cálculo en memoria, pero sigue siendo uno de los favoritos entre los científicos de datos y los ingenieros de Big Data.
En el ecosistema Spark, tenemos los siguientes componentes:
- MLlib: Esta es la biblioteca de aprendizaje automático escalable de Spark que proporciona algoritmos de alta calidad para regresión, agrupación en clústeres, clasificación, etc. Puede comenzar a construir pipelines de aprendizaje automático usando MLlib de Spark usando este artículo: ¿Cómo construir pipelines de aprendizaje automático usando PySpark?
- Spark Streaming: Estamos generando datos a un ritmo y escala sin precedentes en este momento. ¿Cómo nos aseguramos de que nuestra canalización de aprendizaje automático continúe produciendo resultados tan pronto como se generen y recopilen los datos? ¿Aprenda a usar un modelo de aprendizaje automático para hacer predicciones sobre la transmisión de datos con PySpark?
- GraphX: Es una API de Spark para gráficos, un motor de gráficos de red que admite el cálculo de gráficos paralelos.
- Spark SQL: Este es un marco distribuido para el procesamiento de datos estructurados proporcionado por Spark
Sabemos que en las bases de datos relacionales también se almacenan las relaciones entre las diferentes variables así como las diferentes tablas y están diseñadas de tal manera que puedan manejar consultas complejas.
Spark SQL es una combinación asombrosa de procesamiento relacional y programación funcional de Spark. Brinda soporte para varias fuentes de datos y hace posible realizar consultas SQL, lo que resulta en una herramienta muy poderosa para analizar datos estructurados a escala.
Características de Spark SQL
Spark SQL tiene un montón de características increíbles, pero quería resaltar algunas clave que usará mucho en su función:
- Datos de estructura de consulta dentro de programas Spark: Es posible que la mayoría de ustedes ya estén familiarizados con SQL. Por lo tanto, no es necesario que aprenda a definir una función compleja en Python o Scala para usar Spark. ¡Puede usar exactamente la misma consulta para obtener los resultados de sus conjuntos de datos más grandes!
- Compatible con HiveHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información....: No solo SQL, sino que también puede ejecutar las mismas consultas de Hive con Spark SQL Engine. Permite una compatibilidad total con las consultas actuales de Hive.
- Una forma de acceder a los datos: En proyectos típicos de nivel empresarial, no tiene una fuente común de datos. En su lugar, debe manejar varios tipos de archivos y bases de datos. Spark SQL admite casi todos los tipos de archivos y le brinda una forma común de acceder a una variedad de fuentes de datos, como Hive, Avro, Parquet, JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software... y JDBC
- Rendimiento y escalabilidad: Al trabajar con grandes conjuntos de datos, existen posibilidades de que se produzcan errores entre el momento en que se ejecuta la consulta. Spark SQL es compatible con la tolerancia a fallas completa a mitad de la consulta, por lo que podemos trabajar incluso con mil nodos simultáneamente
- Funciones definidas por el usuario: UDF es una característica de Spark SQL que define nuevas funciones basadas en columnas que amplían el vocabulario de Spark SQL para transformar conjuntos de datos
¿Cómo ejecuta Spark SQL una consulta?
¿Cómo funciona Spark SQL, esencialmente? Entendamos el proceso en esta sección.
- Análisis: Primero, cuando consulta algo, Spark SQL encuentra la relación que debe calcularse. Se calcula utilizando un árbol de sintaxis abstracta (AST) donde verifica el uso correcto de los elementos utilizados para definir la consulta y luego crea un plan lógico para ejecutar la consulta.

- Optimización lógica: En este siguiente paso, la optimización basada en reglas se aplica al plan lógico. Utiliza técnicas como:
- Filtrar datos de forma anticipada si la consulta contiene un dónde cláusula
- Utilizar el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... disponible en las tablas, ya que puede mejorar el rendimiento, y
- Incluso asegurándose de que las diferentes fuentes de datos se unan en el orden más eficiente.
- Planificación física: En este paso, se forman uno o más planes físicos utilizando el plan lógico. Spark SQL luego selecciona el plan que podrá ejecutar la consulta de la manera más eficiente, es decir, utilizando menos recursos computacionales.
- Codigo de GENERACION: En el paso final, Spark SQL genera código. Implica generar un código de bytes de Java para ejecutar en cada máquina. Catalyst utiliza una característica especial del lenguaje Scala llamada «Quasiquotes» para facilitar la generación de código.

¿Qué es un Catalyst Optimizer?
La optimización significa actualizar el sistema o el flujo de trabajo existente de tal manera que funcione de una manera más eficiente, al mismo tiempo que usa menos recursos. Un optimizador conocido como Optimizador de catalizador se implementa en Spark SQL que admite técnicas de optimización basadas en reglas y basadas en costos.
En la optimización basada en reglas, hemos definido un conjunto de reglas que determinarán cómo se ejecutará la consulta. Reescribirá la consulta existente de una mejor manera para mejorar el rendimiento.
Por ejemplo, digamos que hay un índice disponible en la mesa. Luego, el índice se utilizará para la ejecución de la consulta de acuerdo con las reglas y los filtros DONDE se aplicarán primero en los datos iniciales si es posible (en lugar de aplicarlos al final).
Además, hay algunos casos en los que el uso de un índice ralentiza una consulta. Sabemos que no siempre es posible que un conjunto de reglas definidas siempre tome grandes decisiones, ¿verdad?
Aquí está el problema: la optimización basada en reglas no tiene en cuenta la distribución de datos. Aquí es donde recurrimos a un Optimizador basado en costos. Utiliza estadísticas sobre la tabla, sus índices y la distribución de los datos para tomar mejores decisiones.
Ejecutando comandos SQL con Spark
¡Es hora de codificar!
He creado un conjunto de datos aleatorio de 25 millones de filas. Tú puedes descargar el conjunto de datos completo aquí. Tenemos un archivo de texto con valores separados por comas. Entonces, primero, importaremos las bibliotecas requeridas, leeremos el conjunto de datos y veremos cómo Spark dividirá los datos en particiones:
![]()
Aquí,
- El primer valor de cada fila es la edad de la persona (que debe ser un número entero)
- El segundo valor es el grupo sanguíneo de la persona (que debe ser una cadena)
- Los valores tercero y cuarto son ciudad y género (ambos son cadenas), y
- El valor final es una identificación (que es de tipo entero)
Asignaremos los datos de cada fila a un tipo y nombre de datos específicos usando las filas de Spark:
![]()

A continuación, crearemos un marco de datos utilizando las filas analizadas. Nuestro objetivo es encontrar los recuentos de valores de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de género mediante el uso de un simple agrupar por función en el marco de datos:

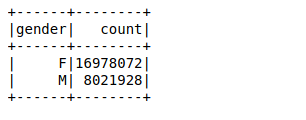

Se necesitaron alrededor de 26 ms para calcular el recuento de valores de 25 millones de filas utilizando una función groupby en el marco de datos. Puedes calcular el tiempo usando %%tiempo en la celda particular de su cuaderno Jupyter.
Ahora, realizaremos la misma consulta usando Spark SQL y veremos si mejora el rendimiento o no.
Primero, necesita registrar el marco de datos como una tabla temporal usando la función registerTempTable. Esto crea una tabla en memoria que solo tiene como ámbito el clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... en el que se creó. La vida útil de esta tabla temporal está limitada a solo una sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el.... Se almacena usando Formato de columnas en memoria de Hive que está altamente optimizado para datos relacionales.
Además, ¡ni siquiera necesita escribir funciones complejas para obtener resultados si se siente cómodo con SQL! Aquí, solo necesita pasar la misma consulta SQL para obtener los resultados deseados en datos más grandes:
![]()
Solo tomó alrededor de 18 ms calcular los recuentos de valores. Esto es mucho más rápido que incluso un marco de datos Spark.
A continuación, realizaremos otra consulta SQL para calcular la edad promedio en una ciudad:
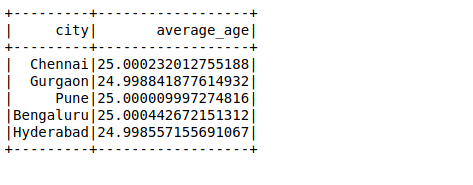
Caso de uso de Apache Spark a escala
Sabemos que Facebook tiene más de 2000 millones de usuarios activos mensuales y con más datos, enfrentan desafíos igualmente complejos. Para una sola consulta, necesitan analizar decenas de terabytes de datos en una sola consulta. Facebook cree que Spark había madurado hasta el punto en que podíamos compararlo con Hive para una serie de casos de uso de procesamiento por lotes.
Permítanme ilustrar esto usando un caso de estudio del propio Facebook. Una de sus tareas fue preparar las características para el ranking de entidades que Facebook utiliza en sus diversos servicios en línea. Anteriormente, usaban la infraestructura basada en Hive, que requería muchos recursos y era difícil de mantener, ya que la canalización se dividió en cientos de trabajos de Hive. Luego construyeron una canalización más rápida y manejable con Spark. Puedes leer su recorrido completo aquí.
Han comparado los resultados de Spark vs Hive PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, por ejemplo, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los.... Aquí hay un gráfico de comparación en términos de latencia (tiempo transcurrido de un extremo a otro del trabajo) que muestra claramente que Spark es mucho más rápido que Hive.

Notas finales
Cubrimos la idea central detrás de Spark SQL en este artículo y también aprendimos cómo usarla para nuestro beneficio. También tomamos un gran conjunto de datos y aplicamos nuestro aprendizaje en Python.
Spark SQL es relativamente desconocido para muchos aspirantes a la ciencia de datos, pero será útil en su rol en la industria o incluso en entrevistas. Es una adición bastante importante a los ojos del gerente de contratación.
Comparta sus pensamientos y sugerencias en la sección de comentarios a continuación.





