Los datos se generan en grandes cantidades en todas partes. Twitter genera más de 12 TB de datos todos los días, Facebook genera más de 25 TB de datos todos los días y Google genera mucho más que estas cantidades todos los días. Dado que estos datos se producen todos los días, necesitamos crear herramientas para manejar datos con un alto
1. Volumen : En la actualidad se almacenan grandes volúmenes de datos para cualquier industria. Los modelos convencionales con datos tan grandes no son factibles.
2. Velocidad : Los datos llegan a alta velocidad y exigen algoritmos de aprendizaje más rápidos.
3. Variedad : Las diferentes fuentes de datos disponen diferentes estructuras. Todos estos datos contribuyen a el pronóstico. Un buen algoritmo puede absorber tal variedad de datos.
Un algoritmo predictivo simple como Random Forest en aproximadamente 50 mil puntos de datos y 100 dimensiones tarda 10 minutos en ejecutarse en una máquina de 12 GB de RAM. Los problemas con cientos de millones de observaciones son simplemente imposibles de solucionar con este tipo de máquinas. Por eso, nos quedan solo dos opciones: utilizar una máquina más fuerte o cambiar la forma en que funciona un algoritmo predictivo. La primera opción no siempre es viable. En este post, aprenderemos sobre los algoritmos de aprendizaje en línea que están destinados a manejar datos con un volumen y velocidad tan altos con máquinas de rendimiento limitado.
¿En qué se diferencia el aprendizaje en línea de los algoritmos de aprendizaje por lotes?
Si es un principiante en la industria de la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico...., todo lo de lo que probablemente haya oído hablar se incluirá en la categoría de aprendizaje por lotes. Tratemos de visualizar en qué se diferencia el funcionamiento de los dos.
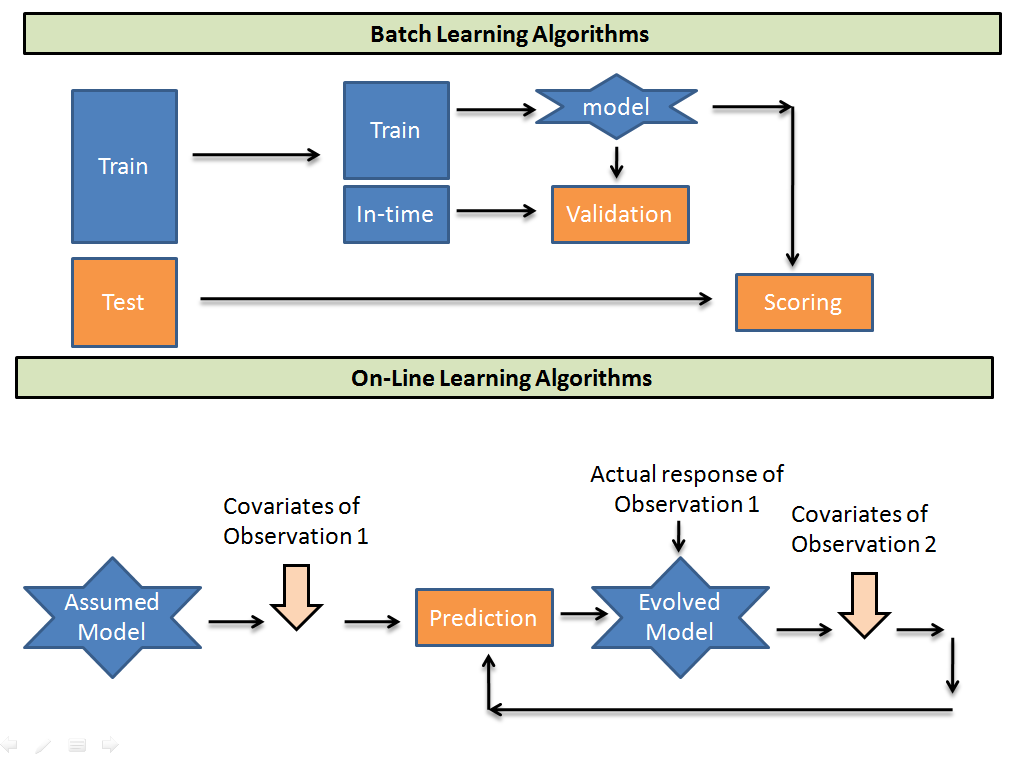
Los algoritmos de aprendizaje por lotes toman lotes de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... para entrenar un modelo. Después predice la muestra de prueba usando la vinculación encontrada. Considerando que, los algoritmos de aprendizaje en línea toman un modelo de conjetura inicial y después toman la observación uno a uno de la población de entrenamiento y recalibran los pesos en cada parámetro de entrada. Aquí hay algunas compensaciones al utilizar los dos algoritmos.
- Computacionalmente mucho más rápido y más eficiente en el espacio. En el modelo en línea, se le posibilita realizar exactamente una pasada de sus datos, por lo que estos algoritmos generalmente son mucho más rápidos que sus equivalentes de aprendizaje por lotes, puesto que la mayoría de los algoritmos de aprendizaje por lotes son de múltiples pasadas. Al mismo tiempo, dado que no puede reconsiderar sus ejemplos anteriores, regularmente no los almacena para ingresar más adelante en el procedimiento de aprendizaje, lo que significa que tiende a usar una huella de memoria más pequeña.
- Suele ser más fácil de poner en práctica. Dado que el modelo en línea hace que uno pase por encima de los datos, terminamos procesando un ejemplo al mismo tiempo, secuencialmente, a medida que ingresan desde el flujo. Esto de forma general simplifica el algoritmo, si lo hace desde cero.
- Más difícil de mantener en producción. La implementación de algoritmos en línea en producción de forma general necesita que tenga algo que pase constantemente puntos de datos a su algoritmo. Si sus datos cambian y sus selectores de funciones ya no producen resultados útiles, o si hay una latencia de red importante entre los servidores de sus selectores de funciones, o uno de esos servidores deja de funcionar, o en realidad, cualquier cantidad de otras cosas, su aprendiz se acumula y tu salida es basura. Asegurarse de que todo esto funcione correctamente puede ser una prueba.
- Más difícil de examinar en línea. En el aprendizaje en línea, no podemos ofrecer un conjunto de «pruebas» para la evaluación debido a que no hacemos suposiciones de distribución; si elegimos un conjunto para examinar, estaríamos asumiendo que el conjunto de pruebas es representativo de los datos que estamos operando, y eso es un supuesto distributivo. Dado que, en el caso más general, no hay forma de obtener un conjunto representativo que caracterice sus datos, su única opción (nuevamente, en el caso más general) es simplemente observar qué tan bien ha estado funcionando el algoritmo recientemente.
- Por lo general, es más difícil hacerlo «bien». Como vimos en el último punto, la evaluación en línea del alumno es difícil. Por razones similares, puede resultar muy difícil obtener que el algoritmo se comporte «correctamente» automáticamente. Puede ser difícil diagnosticar si su algoritmo o su infraestructura se están comportando mal.
En los casos en los que trabajamos con grandes cantidades de datos, no nos queda más remedio que usar algoritmos de aprendizaje en línea. La única otra alternativa es realizar un aprendizaje por lotes en una muestra más pequeña.
Caso de ejemplo para saber el concepto
Queremos predecir la probabilidad de que llueva hoy. Contamos con un panelUn panel es un grupo de expertos que se reúne para discutir y analizar un tema específico. Estos foros son comunes en conferencias, seminarios y debates públicos, donde los participantes comparten sus conocimientos y perspectivas. Los paneles pueden abordar diversas áreas, desde la ciencia hasta la política, y su objetivo es fomentar el intercambio de ideas y la reflexión crítica entre los asistentes.... de 11 personas que predicen la clase: Lluvia y no lluvia en diferentes parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto..... Necesitamos diseñar un algoritmo para predecir la probabilidad. Primero inicialicemos algunas denotaciones.
soy predictores individuales
w (i) es el peso dado al i-ésimo predictor
Inicial w (i) para i en [1,11] son todos 1
Predeciremos que lloverá hoy si,
Suma (w (i) para todas las predicciones de lluvia)> Suma (w (i) para todas las predicciones sin lluvia)
Una vez que tenemos la solución real de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... objetivo, ahora enviamos una retroalimentación sobre los pesos de todos los parámetros. En esta circunstancia tomaremos un mecanismo de retroalimentación muy simple. Para cada predicción correcta, mantendremos el mismo peso del predictor. Mientras que para cada predicción incorrecta, dividimos el peso del predictor por 1,2 (tasa de aprendizaje). Con el tiempo, esperamos que el modelo converja con un conjunto correcto de parámetros. Creamos una simulación con 1000 predicciones hechas por cada uno de los 11 predictores. Así es como salió nuestra curva de precisión,
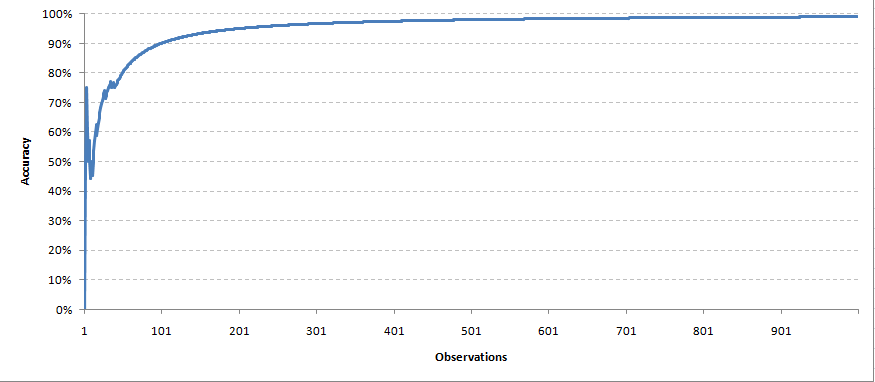
Cada observación se tomó al mismo tiempo para reajustar los pesos. De la misma manera, haremos predicciones para los puntos de datos futuros.
Notas finales
Los algoritmos de aprendizaje en línea son ampliamente utilizados por la industria del comercio electrónico y las redes sociales. No solo es rápido, sino que además tiene la capacidad de capturar cualquier nueva tendencia visible con el tiempo. En este momento se encuentran disponibles una gama de sistemas de retroalimentación y algoritmos convergentes que deben seleccionarse según los requerimientos. En algunos de los siguientes posts, además tomaremos algunos ejemplos prácticos de aplicaciones de algoritmos de aprendizaje en línea.
¿Le fue útil el post? ¿Ha utilizado antes algoritmos de aprendizaje en línea? Comparta con nosotros esas experiencias. Háganos saber su opinión sobre este post en el cuadro a continuación.





