Introducción
¡Una imagen vale mas que mil palabras!
En el entorno competitivo actual, las empresas quieren un proceso de toma de decisiones más rápido, lo que garantiza que se mantengan a la cabeza en la carrera.
La visualización de datos ayuda en dos etapas críticas en el proceso de decisión basado en datos (como se muestra en la siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas....):
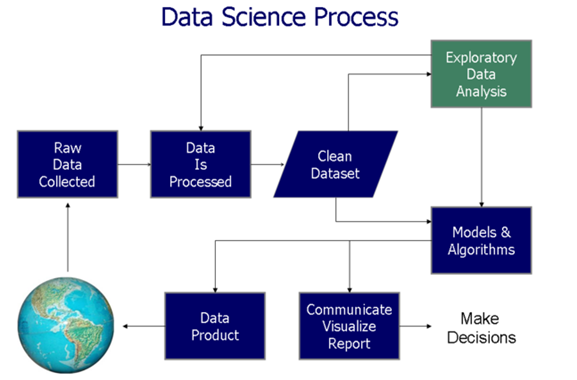
En este artículo, exploraremos las 4 aplicaciones de visualización de datos y su implementación en SAS. Para una mejor comprensión, hemos tomado conjuntos de datos de muestra para crear esta visualización. A continuación, se muestran los aspectos principales de la visualización de datos:
- Haciendo comparación: Incluye gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad...., gráfico de líneasEl gráfico de líneas es una herramienta visual utilizada para representar datos a lo largo del tiempo. Consiste en una serie de puntos conectados por líneas, lo que permite observar tendencias, fluctuaciones y patrones en los datos. Este tipo de gráfico es especialmente útil en áreas como la economía, la meteorología y la investigación científica, facilitando la comparación de diferentes conjuntos de datos y la identificación de comportamientos a lo..., gráfico de líneas de barras, gráfico de columnas, gráfico de columnas de barras agrupadas.
- Relación de estudio: Incluye gráfico de burbujas, gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....
- Estudiando Distribución: Incluye histograma, diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada....,
- Comprender la composición: Incluye gráfico de columnas apiladas

¡Empecemos!
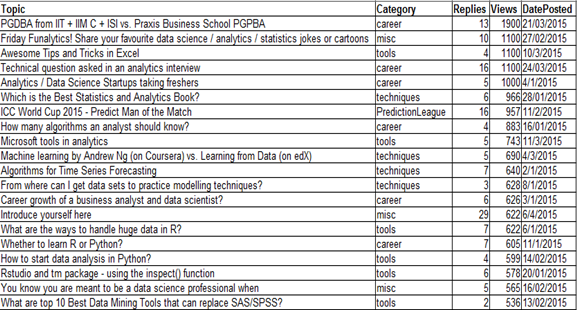
Para fines de la ilustración, usaremos un conjunto de datos ‘discutir’ tomado de la Analítica Vidhya Discutir. Los datos contienen el tema de discusión, la categoría, el número de respuestas a la publicación y el número total de Vistas. Los datos contienen los 20 temas principales:
1. Haciendo una comparación
a) Gráfico de barras
A gráfico de barras, también conocido como gráfico de barras representa datos agrupados utilizando barras rectangulares con longitudes proporcionales a los valores que representan. Las barras se pueden trazar vertical u horizontalmente. Un gráfico de barras verticales a veces se denomina gráfico de barras de columnas.
Ilustración
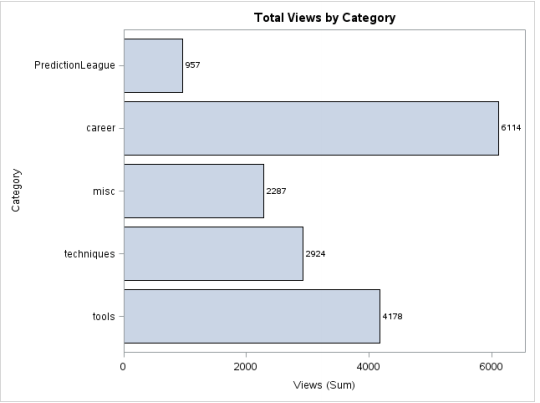
Objetivo: Queremos saber el número de vistas de cada categoría representadas gráficamente a través de un gráfico de barras.
Código:
proc sgplot data = discuss; hbar category/response = views stat = sum datalabel datalabelattrs=(weight=bold); title 'Total Views by Category'; run;
Producción:
B) Gráfico de columnas
Los gráficos de columnas a menudo se explican por sí mismos. Son simplemente la versión vertical de un gráfico de barras donde la longitud de las barras es igual a la magnitud del valor que representan. Aquí hay una maniobra: gire el gráfico que se muestra arriba en -90 grados, se convertirá en un gráfico de columnas.
Código:
proc sgplot data = discuss;
hbar category/response = views stat = sum
datalabel datalabelattrs=(weight=bold) barwidth = 0.5; /* Assign width to bars*/
title 'Total Views by Category';
run;
Producción:
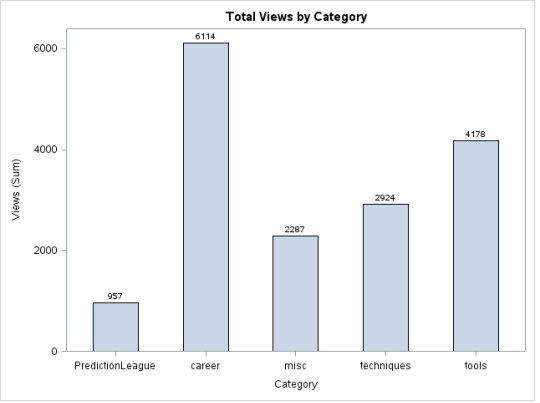
-> Explicación del código para el gráfico de barras y el gráfico de columnas:
- Categoría: la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... según la cual se deben agrupar los datos.
- Respuesta = vistas: las estadísticas especificadas por la opción stat = se calculan para las vistas variables agrupadas por variable de categoría.
- La opción Datalabel especifica que queremos que los valores calculados se muestren para cada barra.
- La opción Weight = bold especifica que las etiquetas de datos de cada barra se mostrarán en negrita.
- La opción de ancho de barra se utiliza para asignar ancho a las barras. El valor predeterminado es 0.8 y el rango es 0.1-1.
c) Gráfico de barras / gráfico de columnas agrupadas
Este tipo de representación es útil cuando queremos visualizar la distribución de datos en dos categorías.
Objetivo: Queremos analizar las visualizaciones totales de los temas en el foro de discusión por categoría y fecha de publicación.
Código:
data discuss_date; set discuss; month = month(DatePosted); month_name=PUT(DatePosted,monname.); put month_name= @; run; proc sgplot data=discuss_date; vbar category/ response=views group=month_name groupdisplay=cluster datalabel datalabelattrs = (weight = bold) dataskin=gloss; yaxis grid; run;
Producción:
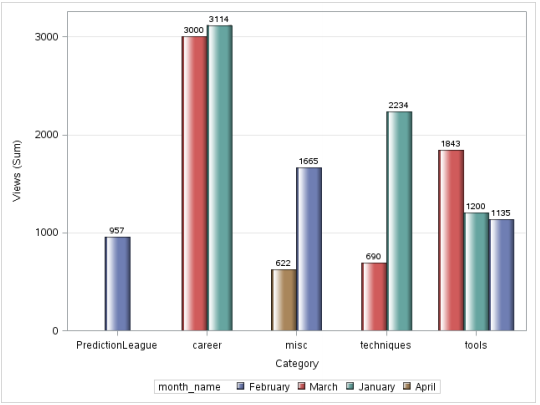
Sin embargo, hay un problema con esta imagen, los meses no están en orden cronológico. Para solucionar esto, utilizamos PROC FORMAT.
Código con FORMATO PROC:
data discuss_date; set discuss; month = month(DatePosted); month_num = input(month,5.); run;
PROC FORMAT; VALUE monthfmt 1 = 'January' 2 = 'February' 3 = 'March' 4 = 'April'; RUN;
proc sgplot data=discuss_date;
vbar category/ response=views group = month_num groupdisplay=cluster datalabel
datalabelattrs = (weight = bold) dataskin=gloss grouporder= ascending;
format month_num monthfmt.;
yaxis grid;
run;
Producción:
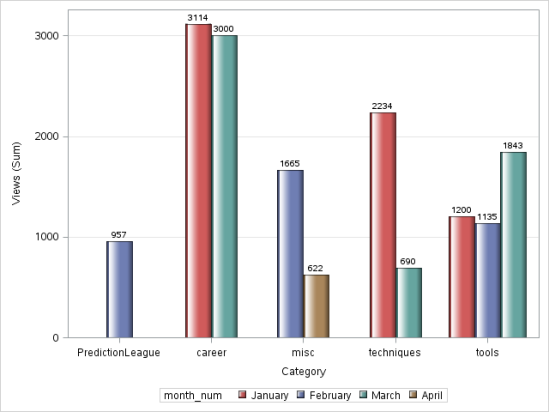
D) Gráfico de linea
A Gráfico de linea o gráfico de líneas es un tipo de gráfico que muestra información como una serie de puntos de datos llamados «marcadores» conectados por segmentos de línea recta. Un gráfico de líneas se usa a menudo para visualizar tendencias en los datos a lo largo de intervalos de tiempo, una serie de tiempo, por lo que la línea a menudo se dibuja cronológicamente. En estos casos se les conoce como ejecutar gráficos.
Para esta ilustración, usaremos datos de PGDBA de IIT + IIM C + ISI frente a Praxis Business School PGPBA.
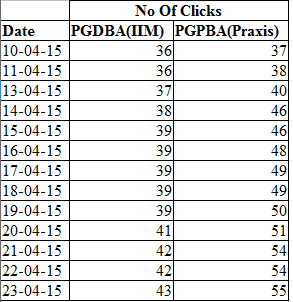
Código:
proc sgplot data = clicks;
vline date/response = PGDBA_IIM_ ;
vline date/response = PGPBA_Praxis_;
yaxis label = "Clicks";
run;
Producción:
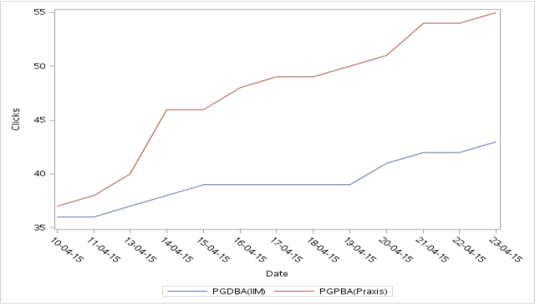
e) Gráfico de líneas de barras
Este gráfico de combinación combina las características del gráfico de barras y el gráfico de líneas. Muestra los datos mediante una serie de barras y / o líneas, cada una de las cuales representa una categoría en particular. Una combinación de barras y líneas en la misma visualización puede resultar útil al comparar valores en diferentes categorías.
Objetivo: Queremos comparar las ventas proyectadas con las ventas reales para diferentes períodos de tiempo.
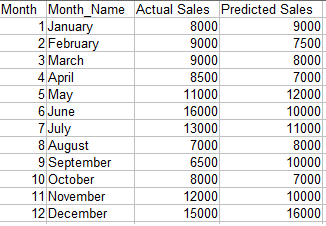
Código:
proc sgplot data=barline;
vbar month/ response=actual_sales datalabel datalabelattrs = (weight = bold)
fillattrs= (color = tan);
vline month/ response=predicted_sales
lineattrs =(thickness = 3) markers;
xaxis label= "Month";
yaxis label = "Sales";
keylegend / location=inside position=topleft across=1;
run;
Nota: Los datos deben ordenarse por la variable del eje x.
Producción:
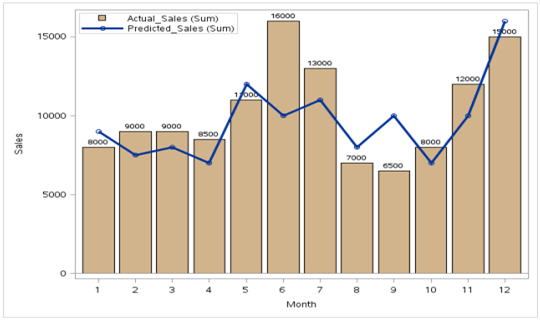
2) Estudiar la relación
a) Gráfico de burbujas
Un gráfico de burbujas es un tipo de gráfico que muestra tres dimensiones de datos. Cada entidad con su triplete (v1, v2, v3) de datos asociados se traza como un disco que expresa dos de los vI valores a través del disco xy ubicación y la tercera por su tamaño. – Fuente: Wikipedia.
Datos para SO:
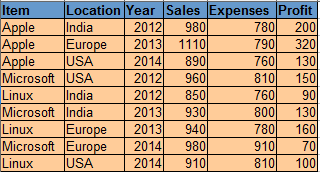
Código:
proc sgplot data = os;
bubble X=expenses Y=sales size= profit
/fillattrs=(color = teal) datalabel = Location;
run;
Producción:
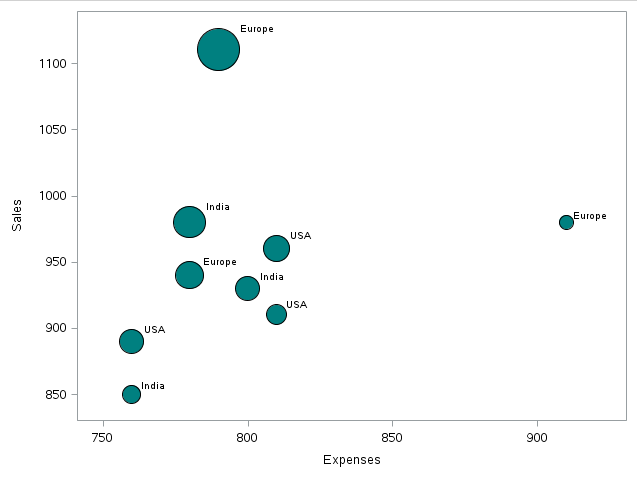
Como podemos ver, hay un registro para el cual las Ventas y las Ganancias son máximas mientras que los gastos comparativos son menores que algunos otros puntos de datos.
b) Diagrama de dispersión para la relación
Un diagrama de dispersión simple entre dos variables puede darnos una idea sobre la relación entre ellas: lineal, exponencial, etc. Esta información puede ser útil durante un análisis posterior.
Código:
proc sgplot data = os;
title 'Relationship of Profit with Sales';
scatter X= sales Y = profit/
markerattrs=(symbol=circlefilled size=15);
run;
Producción:
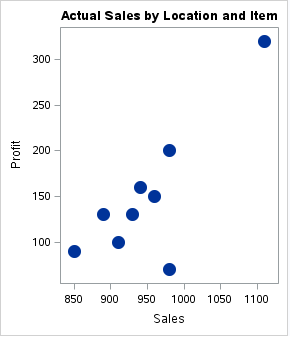
3. Estudiar la distribución
a) Histograma
A histograma es una representación gráfica de la distribución de datos numéricos. Es una estimación de la distribución de probabilidad de una variable continua. Para construir un histograma, el primer paso es «agrupar» el rango de valores, es decir, dividir el rango completo de valores en una serie de intervalos pequeños y luego contar cómo muchos valores caen en cada intervalo. Los bins generalmente se especifican como intervalos consecutivos, no superpuestos de una variable. Los contenedores (intervalos) deben ser adyacentes y, por lo general, del mismo tamaño. Los rectángulos de un histograma se dibujan de modo que se toquen entre sí para indicar que la variable original es continua.
Código:
proc sgplot data = sashelp.cars;
histogram msrp/fillattrs=(color = steel)scale = proportion;
density msrp;
run;
Producción:
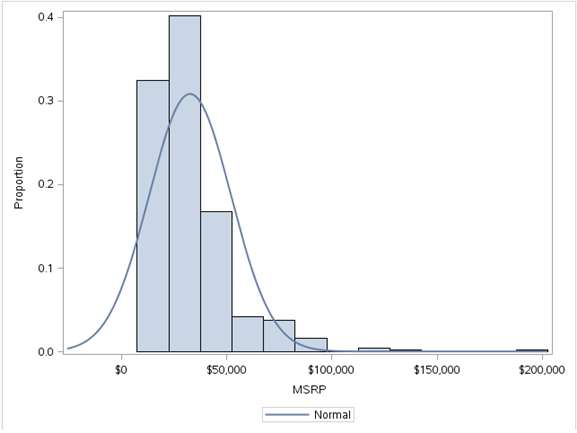
Hemos utilizado el conjunto de datos sashelp.mtcars aquí. Un histograma de la variable MSRP nos da la figura anterior. Esto nos dice que la variable MSRP está sesgada hacia la derecha, lo que indica que la mayoría de los puntos de datos están por debajo de $ 50,000. Se pueden encontrar ideas significativas a partir de histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.....
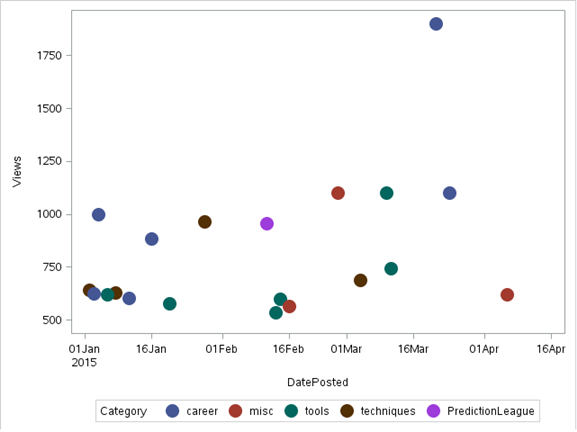
b) Diagrama de dispersión
en un gráfico de dispersión los datos se muestran como una colección de puntos, cada uno con el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable que determina la posición en el eje vertical. Se puede usar tanto para ver la distribución de datos. y acceder a la relación entre variables.
Nota: para la ilustración, usaremos un conjunto de datos ‘discutir’ tomado de la Analítica Vidhya Discutir
Código:
proc sgplot data = discuss;
scatter X= dateposted Y = views/group=category
markerattrs=(symbol=circlefilled size=15);
run;
Producción:
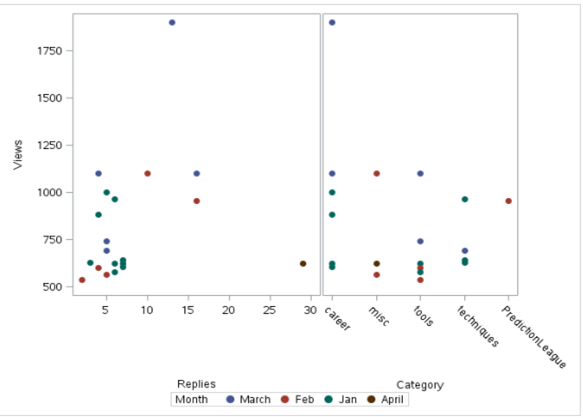
los SGSCATTER El procedimiento también se puede utilizar para diagramas de dispersión. Tiene la ventaja de poder producir múltiples diagramas de dispersión. A continuación se muestra la salida usando sgcscatter:
Código:
proc sgscatter data = discuss;
compare y = views x = (replies category)
/group = month markerattrs=(symbol = circlefilled size = 10);
run;
Producción:
Un uso importante del diagrama de dispersión es la interpretación de los residuos de la regresión lineal. Un diagrama de dispersión de los residuos frente a los valores pronosticados de la variable pronosticada nos ayuda a determinar si los datos son heterocedásticos u homocedásticos.
HETEROSQUEDÁSTICO HOMOSQUEDÁSTICO
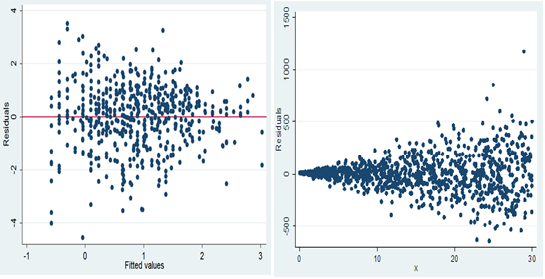
4) Composición
a) Gráfico de columnas apiladas:
En un gráfico de barras apiladas, las barras apiladas representan diferentes grupos uno encima del otro. La altura de la barra resultante muestra el resultado combinado de los grupos.
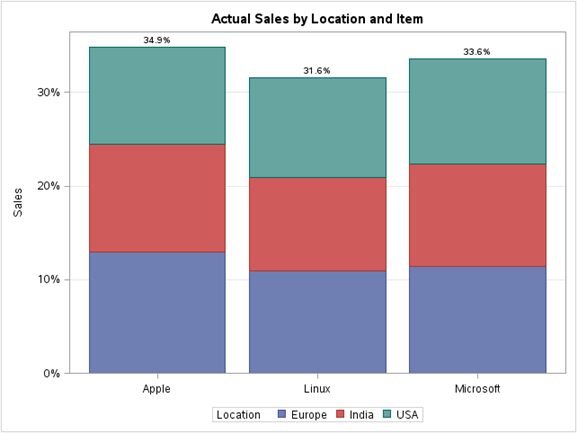
Por ejemplo, si queremos ver las ventas totales por artículo agrupadas por ubicación en los datos totales del conjunto de datos del sistema operativo, podemos usar el gráfico de columnas apiladas. A continuación se muestra la ilustración:
Código:
proc sgplot data=os; title 'Actual Sales by Location and Item'; vbar Item / response=Sales group=Location stat=percent datalabel; xaxis display=(nolabel); yaxis grid label="Sales"; run;
Producción:
Notas finales:
Las visualizaciones se convierten en una forma natural de comprender los datos en grandes cantidades. Transmiten información de manera sencilla y facilitan el intercambio de ideas con otros. En este artículo, analizamos algunas visualizaciones básicas que se pueden realizar a través de SAS base. Estos pueden ser una excelente manera de resumir nuestros datos, obtener información, encontrar relaciones, etc.
¿Le resultó útil este artículo? ¿Hay alguna otra visualización que haya utilizado que pueda compartir con nuestra audiencia? No dude en compartirlos a través de los comentarios a continuación.





