En mi artículo anterior, «Combinación de conjuntos de datos en SAS – Simplificado», analizamos tres métodos para combinar conjuntos de datos: anexar, concatenar e intercalar. En este artículo, veremos el método más común y utilizado para combinar conjuntos de datos: FUSIÓN o UNIÓN.
La necesidad de unir / fusionar conjuntos de datos:
Antes de entrar en detalles, comprendamos por qué realmente necesitamos unirnos / fusionarnos. Siempre que tengamos información dividida y disponible en dos o más conjuntos de datos y queramos combinarlos en un solo conjunto de datos, necesitamos fusionar / unir estas tablas. Una de las principales cosas a tener en cuenta es que la fusión debe basarse en criterios o campos comunes. Por ejemplo, en una empresa minorista, tenemos una tabla de transacciones diarias (la tabla contiene detalles de productos, detalles de ventas y detalles de clientes) y una tabla de inventario (que tiene detalles de productos y cantidad disponible). Ahora bien, para tener la información sobre Inventario o la disponibilidad de un producto, ¿qué debemos hacer? Combine la tabla TransacciónLa "transacción" se refiere al proceso mediante el cual se lleva a cabo un intercambio de bienes, servicios o dinero entre dos o más partes. Este concepto es fundamental en el ámbito económico y legal, ya que implica el acuerdo mutuo y la consideración de términos específicos. Las transacciones pueden ser formales, como contratos, o informales, y son esenciales para el funcionamiento de mercados y negocios.... con la tabla Inventario basada en Product_Code y reste la cantidad vendida de la cantidad disponible.
La fusión / unión puede ser de varios tipos y depende de los requisitos comerciales y de la relación entre los conjuntos de datos. Primero, veamos varios tipos de relación que pueden tener los conjuntos de datos.
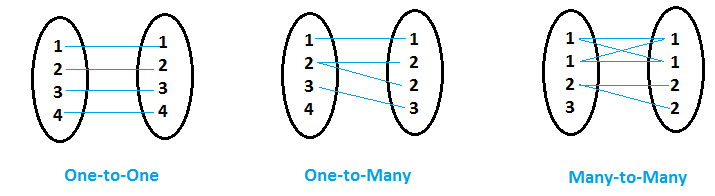
- Cuando para cada valor de variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... común (digamos Variable ‘x’) en el primer conjunto de datos, el segundo conjunto de datos tiene solo un valor coincidente para esa variable común ‘x’, entonces se llama Doce y cincuenta y nueve de la noche relación.
- Cuando para los valores de la variable común (digamos variable ‘y’) en el primer conjunto de datos, otros conjuntos de datos tienen más de un valor coincidente para esa variable común ‘y’, entonces se llama Uno a muchos relación.
- Cuando ambos conjuntos de datos tienen múltiples entradas para el mismo valor de variable común, entonces se llama Muchos a muchos relación.
En SAS, podemos realizar uniones / fusiones a través de varias formas, aquí discutiremos las formas más comunes: Data Step y PROC SQL. En el paso de Datos, usamos la instrucción Merge para realizar uniones, mientras que en PROC SQL, escribimos una consulta SQL. Analicemos el paso de datos primero:
PASOS DE DATOS
Syntax:- Data Dataset; Merge Dataset1 Dataset2 Dataset3 ...Datasetn; By CommonVariable1 CommonVariable2......CommonVariablen; Run;
Nota: – Los conjuntos de datos deben ordenarse por variable (s) común y el nombre, tipo y longitud de la variable común deben ser los mismos para todos los conjuntos de datos de entrada.
Veamos algunos escenarios para cada una de las relaciones entre conjuntos de datos de entrada.
Relación UNO a UNO
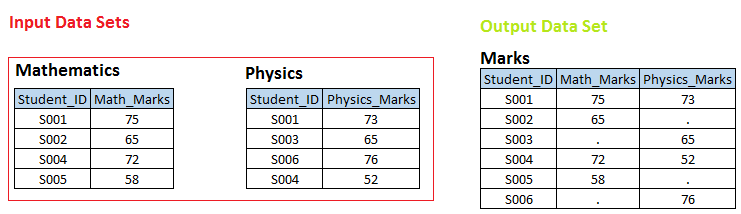
Escenario 1 En los siguientes conjuntos de datos de entrada, puede ver que hay una relación uno a uno entre estas dos tablas en Identificación del Estudiante. Ahora queremos crear un conjunto de datos. MARCAS, donde tenemos todos los student_ids únicos con las respectivas calificaciones de matemáticas y física. Si student_id no está disponible en la tabla de Matemáticas, entonces math_marks debería tener un valor faltante y viceversa.
Solución usando Pasos de datos: –
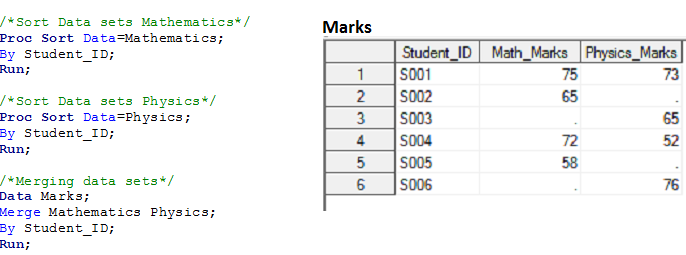
Cómo funciona:-
- SAS compara ambos conjuntos de datos y crea un PDV (Vector de datos de programa) para todas las variables únicas y las inicializa con valores faltantes (el Vector de datos de programa es un intermediario entre los conjuntos de datos de entrada y salida). En el ejemplo actual, crearía un PDV como este:

- Lee la primera observación de los conjuntos de datos de entrada y compara los valores de la variable BY en ambos conjuntos de datos:
- si los valores son iguales, se compara con el valor de la variable BY en PDV.
- si no es igual, las variables de PDV se reinicializan con los valores perdidos y el valor de la observación actual se copia en el PDV mientras que la otra observación permanece perdida
- Si es igual, las variables de PDV no se reinicializan. El valor disponible de la observación actual se actualiza en el PDV
- Después de eso, el puntero de registro se mueve a la siguiente observación en ambos conjuntos de datos y, mientras se ejecuta la instrucción RUN, los valores de PDV se transfieren al conjunto de datos de salida.
- Si el valor de Por variable no coincide, la observación del conjunto de datos que tiene el valor más bajo se copia en PDV. El puntero de registro del conjunto de datos que tiene un valor de variable BY más bajo se mueve a la siguiente observación y el paso 2 (a) se repite nuevamente.
- si los valores son iguales, se compara con el valor de la variable BY en PDV.
- Los pasos anteriores se repiten hasta que se alcanza el EOF de ambos conjuntos de datos.
Puede realizar un ensayo para evaluar el conjunto de datos de resultados.
Escenario 2: – Basándonos en los conjuntos de datos de entrada del escenario 1, queremos crear los siguientes conjuntos de datos de salida.
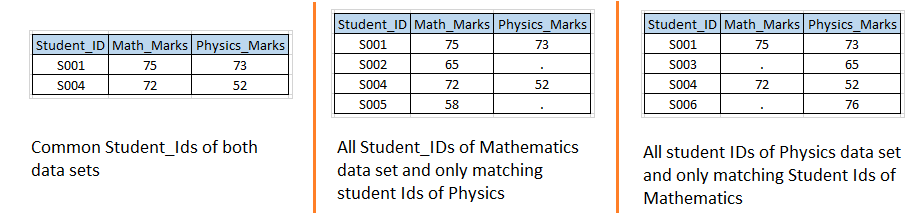
Solución usando pasos de datos: – Escribamos un código similar al escenario 1 con la opción IN. 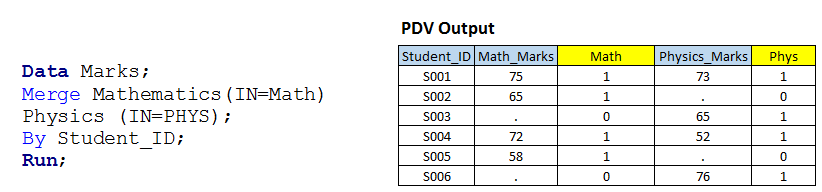 Arriba, puede ver que hemos usado la opción IN con ambos conjuntos de datos de entrada y valores asignados de estos a las variables temporales MATH y PHYS porque son variables temporales, por lo que no podemos verlas en el conjunto de datos de salida.
Arriba, puede ver que hemos usado la opción IN con ambos conjuntos de datos de entrada y valores asignados de estos a las variables temporales MATH y PHYS porque son variables temporales, por lo que no podemos verlas en el conjunto de datos de salida.
Le he mostrado la tabla (datos PDV) que tiene un valor variable para todas las observaciones junto con las variables temporales. Ahora, con base en el valor de estas variables, podemos escribir un código para las operaciones de subconfiguración y JOIN"JOIN" es una operación fundamental en bases de datos que permite combinar registros de dos o más tablas basándose en una relación lógica entre ellas. Existen diferentes tipos de JOIN, como INNER JOIN, LEFT JOIN y RIGHT JOIN, cada uno con sus propias características y usos. Esta técnica es esencial para realizar consultas complejas y obtener información más relevante y detallada a partir de múltiples fuentes de datos.... según lo necesitemos:
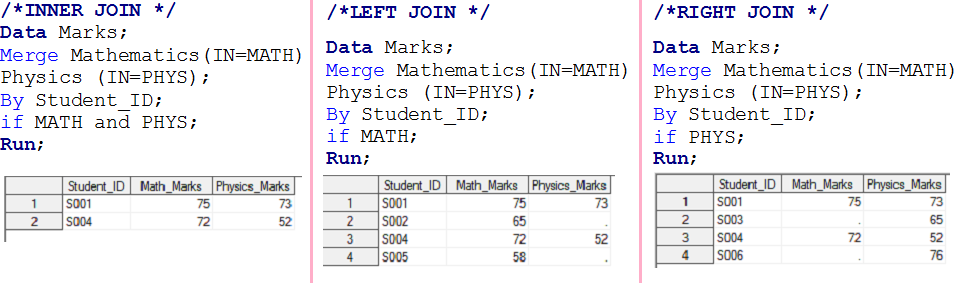
- Si MATH y PHYS tienen valor 1, creará el primer conjunto de datos de salida y se llamará INNER JOINUn "Inner Join" es una operación en bases de datos que permite combinar filas de dos o más tablas, basándose en una condición de coincidencia específica. Este tipo de unión solo devuelve las filas que tienen correspondencias en ambas tablas, lo que resulta en un conjunto de resultados que refleja únicamente los datos relacionados. Es fundamental en consultas SQL para obtener información cohesiva y precisa de múltiples fuentes de datos.....
- Si MATH tiene 1, creará un segundo conjunto de datos de salida y se llamará LEFT JOINEl "LEFT JOIN" es una operación en SQL que permite combinar filas de dos tablas, mostrando todas las filas de la tabla izquierda y las coincidencias de la tabla derecha. Si no hay coincidencias, se rellenan con valores nulos. Esta herramienta es útil para obtener información completa, incluso cuando algunas relaciones son opcionales, facilitando así el análisis de datos de manera eficiente y coherente.....
- Si PHYS tiene 1, creará un tercer conjunto de datos de salida y se llamará como RIGHT JOINEl "RIGHT JOIN" es una operación en bases de datos que permite combinar filas de dos tablas, asegurando que todas las filas de la tabla de la derecha se incluyan en el resultado, incluso si no hay coincidencias en la tabla de la izquierda. Este tipo de unión es útil para preservar información de la tabla secundaria, facilitando el análisis y la obtención de datos completos en consultas SQL....
- Si MATH y PHYS tienen 1, funcionará como FULL JOINEl "FULL JOIN" es una operación en bases de datos que combina los resultados de dos tablas, mostrando todos los registros de ambas. Cuando hay coincidencias, se combinan los datos, pero también se incluyen los registros que no tienen correspondencia en la otra tabla, completando con valores nulos. Esta técnica es útil para obtener una visión completa de la información, permitiendo un análisis más exhaustivo de los datos en relación...., también se ha resuelto en el escenario-1.
Relación de UNO a MUCHOS
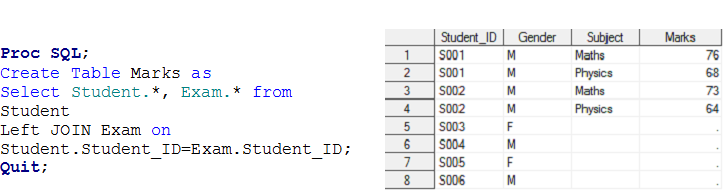
Escenario – 3 Aquí tenemos dos conjuntos de datos, Estudiante y Examen y queremos crear un conjunto de datos de salida Marcas.
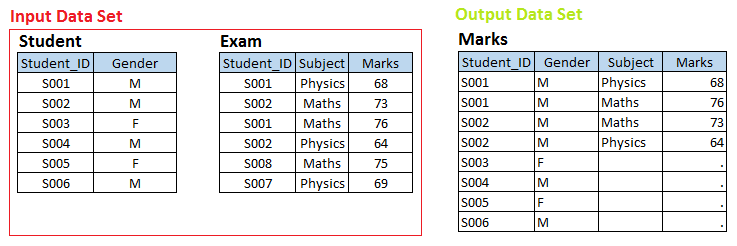
En la parte superior de los conjuntos de datos de entrada, hay una relación de uno a varios entre el alumno y el examen. Ahora, si desea crear marcas de conjunto de datos de salida con observación individual para cada examen de los estudiantes, estas pertenecen al conjunto de datos de ESTUDIANTE, es decir, Unión a la izquierda.
Solución usando Pasos de datos: –
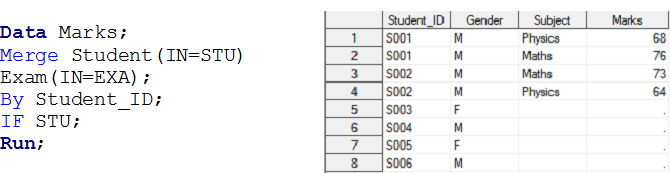
De manera similar, podemos realizar operaciones para combinación interna, derecha y completa para una relación de uno a muchos utilizando el operador IN.
Relación de MUCHOS a MUCHOS
Escenario 4: Cree conjuntos de datos de salida que tengan todas las combinaciones basadas en un campo común. También puede ver que ambos conjuntos de datos de entrada tienen una relación de varios a varios.
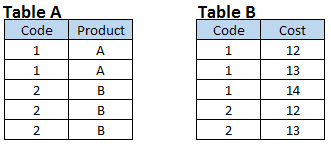
Los pasos de datos no realizan una relación de MUCHOS a MUCHOS, porque no proporcionan salida como producto cartesiano. Cuando fusionamos la tabla A y la tabla B usando pasos de datos, la salida es similar a la siguiente instantánea.
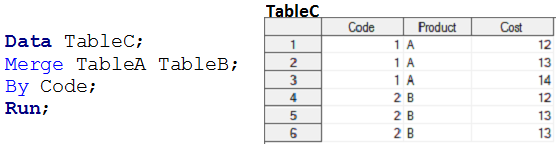 Anteriormente hemos visto, ¿cómo podemos usar los pasos de datos para fusionar dos o más conjuntos de datos que tengan alguna de las relaciones, excepto MUCHOS a MUCHOS? Ahora veremos los métodos PROC SQL para tener una solución para requisitos similares.
Anteriormente hemos visto, ¿cómo podemos usar los pasos de datos para fusionar dos o más conjuntos de datos que tengan alguna de las relaciones, excepto MUCHOS a MUCHOS? Ahora veremos los métodos PROC SQL para tener una solución para requisitos similares.
PROC SQL
Para comprender la metodología de unión en SQL, primero debemos comprender el producto cartesiano. El producto cartesiano es una consulta que tiene varias tablas en la cláusula from y produce todas las combinaciones posibles de filas de las tablas de entrada. Si tenemos dos tablas con 2 y 4 registros respectivamente, usando el producto cartesiano, tenemos una tabla con 2 X 4 = 8 registros.
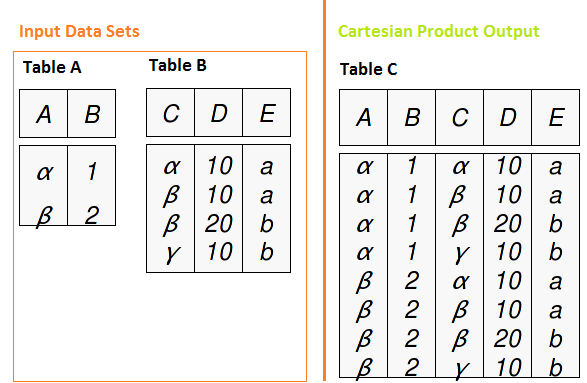
Las uniones SQL funcionan para cada una de las relaciones entre conjuntos de datos (uno a uno, uno a muchos y muchos a muchos). Veamos cómo funciona con tipos de combinaciones.
Sintaxis:-
Seleccione Columna-1, Columna-2,… Columna-n de la tabla1 UNIÓN INTERIOR / IZQUIERDA / DERECHA / COMPLETA tcapaz2 SOBRE Join-condition ;
Nota:-
- Las tablas pueden o no estar ordenadas por variables comunes.
- El nombre de las variables comunes puede no ser similar, pero debe tener una longitud y un tipo similares.
- Funciona con un máximo de dos mesas.
Resolvamos los requisitos anteriores usando PROC SQL.
Escenario 1 :- Este fue un ejemplo de FULL Join, donde se requerían todos los Student_ID en el conjunto de datos de salida con las respectivas marcas MATH y PHYSICS.

Arriba en el conjunto de datos de salida, puede ver que Student_ID falta para aquellos estudiantes que aparecieron solo para el examen de Física. Para solucionarlo usaremos una función COALESCE. Devuelve el valor del primer argumento que no falta de las variables dadas.
Sintaxis:-
COALESCE (argumento-1, argumento-2,… ..argumento-n)
Modifiquemos el código anterior: –
Escenario 2: – Este fue un ejemplo de INNER, Left y Right Join. Aquí estamos resolviendo para Inner Join. Del mismo modo, podemos hacer para la unión izquierda y derecha.
Del mismo modo, podemos hacer para la unión izquierda y derecha.
Escenario -3 Este fue un problema de unión a la izquierda para una relación de UNO a MUCHOS.
Escenario -4 Este fue un problema de la relación de Muchos a MUCHOS. Ya hemos comentado que SQL puede producir un producto cartesiano que contiene todas las combinaciones de registros entre dos tablas.

Arriba hemos visto Proc SQL para unir / fusionar conjuntos de datos.
Nota final: –
En esta serie de artículos sobre la combinación de conjuntos de datos en SAS, analizamos varios métodos para combinar conjuntos de datos como agregar, concatenar, intercalar, fusionar. Particularmente en este artículo, discutimos que dependiendo de la relación entre conjuntos de datos, varios tipos de uniones y cómo podemos resolverlo en función de diferentes escenarios. Hemos utilizado dos métodos (Data Steps y PROC SQL) para lograr resultados. Veremos la eficiencia de estos métodos en uno de los artículos futuros.
¿Te ha resultado útil esta serie? Hemos simplificado un tema complejo como la combinación de conjuntos de datos y hemos intentado presentarlo de manera comprensible. Si necesita más ayuda con la combinación de conjuntos de datos, no dude en hacer sus preguntas a través de los comentarios a continuación.
PD ¿Te has unido? Analítica Vidhya Discutir ¿todavía? Si no es así, se está perdiendo una gran cantidad de debates sobre ciencia de datos. Estas son algunas de las discusiones que tienen lugar en SAS:
1. Seleccionar variables y transferirlas a un nuevo conjunto de datos en SAS
2. Importar los primeros 20 registros de Excel a SAS
3. Donde la declaración no funciona en SAS





