Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
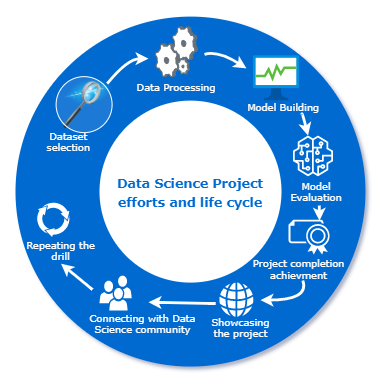
Pasos para su primer proyecto de ciencia de datos
En este artículo, veamos algunos consejos que puede utilizar para comenzar con sus proyectos de ciencia de datos personales.
1. Elija un conjunto de datos
Si está asumiendo el proyecto de ciencia de datos por primera vez, elija un conjunto de datos de su interés. Puede estar relacionado con deportes, películas o música, cualquier cosa que le interese. Los sitios web más comunes para obtener los datos son:
Para aquellos que ya han realizado uno o dos proyectos, de un extremo a otro por su cuenta, siguiendo las pautas anteriores, pueden apuntar al análisis de un conjunto de datos complejo de un dominio en particular como comercio minorista, finanzas o atención médica para tener una idea de los proyectos en tiempo real.
Para empezar, había seleccionado un conjunto de datos de seguros médicos para practicar el análisis predictivo. Saqué el conjunto de datos del sitio web de Kaggle
! pip install -q kaggle #from google.colab import files #files.upload()
! mkdir ~/.kaggle ! cp kaggle.json ~/.kaggle/ ! chmod 600 ~/.kaggle/kaggle.json #! kaggle datasets download -d mirichoi0218/insurance #! unzip insurance.zip -d health-insurance
! kaggle datasets download -d mirichoi0218/insurance ! unzip insurance.zip -d health-insurance
2. Elija un IDE
Seleccione un IDE con el que se sienta más cómodo. Si está utilizando Python como lenguaje, aquí hay algunos ejemplos
- – Es un IDE diseñado para escribir códigos Python. Proporciona varias funciones productivas como el cuidado de la rutina, la finalización inteligente del código, la verificación de errores y la corrección de códigos. Facilita el mantenimiento del proyecto al proporcionar integración con funciones de control de versiones, admite el desarrollo web y la ciencia de datos.
- Cuaderno Jupyter – Es una aplicación web de código abierto que le permite crear y compartir documentos que contienen código en vivo, ecuaciones y visualización. Ayuda a agilizar el trabajo y facilitar las colaboraciones
- Google Colab – Permite a los usuarios escribir y ejecutar códigos Python. Es muy adecuado para proyectos de ciencia de datos y aprendizaje automático, ya que ofrece recursos computacionales de forma gratuita. Puede ejecutar algoritmos de aprendizaje automático pesados aquí con facilidad sin tener que preocuparse por la infraestructura o los costos.
- Archivo de texto simple con extensión .py: aunque las opciones anteriores están disponibles y son fáciles de usar, si se siente más cómodo con el bloc de notas para escribir su código, puede usarlo y guardar su archivo con la extensión .py. Luego puede ejecutar el mismo usando una línea de comando con sintaxis como “python <> .py. Esto ejecutará su programa, pero para los trabajos de ciencia de datos, esta podría no ser la mejor opción, ya que no puede ver el resultado del código o las visualizaciones sobre la marcha.
Seleccioné Google Colab como entorno de trabajo.
3. Enumere claramente las actividades
Haga una lista de las actividades que desea realizar en el conjunto de datos para tener una ruta clara antes de comenzar. Las actividades comunes que realizamos en proyectos de ciencia de datos son la ingesta de datos, la limpieza de datos, la transformación de datos, el análisis de datos exploratorios, la construcción de modelos, la evaluación de modelos y la implementación de modelos. Aquí hay un breve acerca de todos estos pasos.
- Ingestión de datos – Es un proceso de leer los datos en un marco de datos.
###Panda package makes it easy to read a file into a dataframe
#Importing the libraries
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.cbook import boxplot_stats
import statsmodels.api as sm
from sklearn.model_selection import train_test_split,GridSearchCV, cross_val_score, cross_val_predict
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.tree import DecisionTreeRegressor
from sklearn import ensemble
import numpy as np
import pickle
#Reading and summarizing the data
health_ins_df = pd.read_csv("health-insurance/insurance.csv")
health_ins_df.columns
health_ins_df.shape
health_ins_df.describe()
- Limpieza de datos – Es el proceso de identificar y eliminar las anomalías en el conjunto de datos.
- Transformación de datos – Implica cambiar el tipo de datos de las columnas, crear columnas derivadas o eliminar datos duplicados, por nombrar algunos.
- Análisis exploratorio de datos – Realice análisis univariados y multivariados en los conjuntos de datos para encontrar información y patrones ocultos en ellos.
Me dediqué a la limpieza de datos y al análisis de datos exploratorios de variables numéricas y categóricas en días separados para centrarme en los detalles.
#Visualizing age column with a histogram
fig,axes=plt.subplots(1,2,figsize=(10,5)) sns.histplot( health_ins_df['age'] , color="skyblue",ax=axes[0]) sns.histplot( health_ins_df['bmi'] , color="olive",ax=axes[1]) plt.show()
#Visualizing age column with a boxplot fig,axes=plt.subplots(1,2,figsize=(10,5)) sns.boxplot(x = 'age', data = health_ins_df, ax=axes[0]) sns.boxplot(x = 'bmi', data = health_ins_df, ax=axes[1]) plt.show()
#Finding the outlier values in the bmi column outlier_list = boxplot_stats(health_ins_df.bmi).pop(0)['fliers'].tolist() print(outlier_list)
#Finding the number of rows containing outliers
outlier_bmi_rows = health_ins_df[health_ins_df.bmi.isin(outlier_list)].shape[0]
print("Number of rows contaning outliers in bmi : ", outlier_bmi_rows)
#Percentage of rows which are outliers
percent_bmi_outlier = (outlier_bmi_rows/health_ins_df.shape[0])*100
print("Percentage of outliers in bmi columns : ", percent_bmi_outlier)
#Converting age into age brackets
print("Minimum value for age : ", health_ins_df['age'].min(),"nMaximum value for age : ", health_ins_df['age'].max())
#Age between 18 to 40 years will fall under young
#Age between 41 to 58 years will fall under mid-age
#Age above 58 years will fall under old age
health_ins_df.loc[(health_ins_df['age'] >=18) & (health_ins_df['age'] <= 40), 'age_group'] = 'young'
health_ins_df.loc[(health_ins_df['age'] >= 41) & (health_ins_df['age'] <= 58), 'age_group'] = 'mid-age'
health_ins_df.loc[health_ins_df['age'] > 58, 'age_group'] = 'old'
fig,axes=plt.subplots(1,5,figsize=(20,8))
sns.countplot(x = 'sex', data = health_ins_df_clean, palette="magma",ax=axes[0])
sns.countplot(x = 'children', data = health_ins_df_clean, palette="magma",ax=axes[1])
sns.countplot(x = 'smoker', data = health_ins_df_clean, palette="magma",ax=axes[2])
sns.countplot(x = 'region', data = health_ins_df_clean, palette="magma",ax=axes[3])
sns.countplot(x = 'age_group', data = health_ins_df_clean, palette="magma",ax=axes[4])
heatmap = sns.heatmap(health_ins_df_clean.corr(), vmin=-1, vmax=1, annot=True) sns.relplot(x="bmi", y="charges",hue="sex", style = "sex", data=health_ins_df_clean); sns.boxplot(x="smoker", y="charges", data=health_ins_df_clean)
- Construcción del modelo – Pruebe y pruebe todos los modelos posibles en el conjunto de datos antes de elegir el correcto según las limitaciones comerciales / técnicas. Durante esta fase, también puede probar algunas técnicas de embolsado o refuerzo.
Primero desarrollé un modelo base, antes de probar cualquier modelo avanzado en el conjunto de datos
#Data Pre-processing #Converting categorical values into dummies using one-hot encoding technique health_ins_df_processed = pd.get_dummies(health_ins_df_clean, columns=['sex','children','smoker','region','age_group'], prefix=['sex','children','smoker','region','age_group']) health_ins_df_processed.drop(['age'],axis = 1,inplace=True)
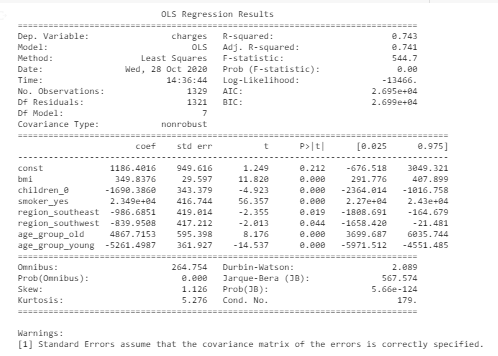
#Building linear regression model X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges'] y = health_ins_df_processed['charges'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) X = sm.add_constant(X) # adding a constant model = sm.OLS(y, X).fit() predictions = model.predict(X) print_model = model.summary() print(print_model)
#Final model after eliminating variable with least significance and high vif X = health_ins_df_processed[['bmi','children_0', 'smoker_yes', 'region_southeast', 'region_southwest', 'age_group_old', 'age_group_young']] y = health_ins_df_processed['charges'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) X = sm.add_constant(X) # adding a constant model = sm.OLS(y, X).fit() predictions = model.predict(X) print_model = model.summary() print(print_model)
- Evaluación del modelo – En esta fase, probamos si nuestro modelo es lo suficientemente bueno para obtener un resultado previsto. Medimos precisión, especificidad, sensibilidad o R-cuadrado ajustado según el modelo que hayamos utilizado
Esta es la métrica de evaluación final del modelo base que muestra un 74% de precisión y 7 variables significativas (valor de p <valor de significancia)
4. Realice las tareas una por una
A estas alturas, debe tener una idea de qué actividades realizar en su proyecto. Puede tomarlos uno por uno. No necesariamente, tienes que completar todo en un día. Puede tomar hasta 1 día de tiempo para decidir en qué conjunto de datos desea trabajar y con qué entorno se siente cómodo.
Puede dedicar el día 2 a comprender los datos y realizar las actividades de limpieza de datos. Del mismo modo, puede apuntar a completar su proyecto en un lapso de 7-8 días.
He realizado este proyecto en un lapso de 4 días. He planeado probar algunos modelos más avanzados para aumentar el rendimiento predictivo
5. Prepara un resumen
Estaré preparando un breve resumen después de que se complete este proyecto.
6. Compártelo en plataformas de código abierto
Elija una plataforma de código abierto en la que desee publicar el resumen o los códigos del proyecto para que pueda obtener visibilidad en la comunidad de ciencia de datos y conectarse con otros entusiastas. GitHub se usa más comúnmente en estos días. Hay pocos sitios web como Kaggle, Google Colab que ofrecen núcleos en línea para que pueda escribir código y ejecutarlos sin tener que preocuparse por la infraestructura. También puede aprovechar estas plataformas.
El código fuente está disponible en mi GitHub cuenta
Las ventajas de asumir los proyectos por etapas
1. No hay presión para completar el proyecto todo en un día.
2. Puede concentrarse únicamente en una tarea específica en un día y puede completar la misma con eficiencia.
3. Te mantendrá pegado a las tareas hasta que termine
4. El resumen del proyecto puede ser referenciado en el futuro mientras se prepara para las entrevistas o se hace un tipo similar de proyectos.
5. Puede aprovechar este proyecto para conectarse con otros entusiastas de la ciencia de datos y compartir ideas creativas.
Aprendí que debemos seguir un enfoque disciplinado para aprender e invertir nuestro tiempo en hacer los proyectos. Todos aprendemos más, haciendo las cosas de manera práctica. En última instancia, es el trabajo duro y la perseverancia lo que te llevará por el camino que siempre has soñado pavimentar.





