Este artículo fue publicado como parte del Blogatón de ciencia de datos
proyecto. EDA es el proceso de investigar el conjunto de datos para descubrir patrones y anomalías (valores atípicos) y formular hipótesis basadas en nuestra comprensión del conjunto de datos.
EDA implica generar estadísticas resumidas para datos numéricos en el conjunto de datos y crear varias representaciones gráficas para comprender mejor los datos. En este artículo, entenderemos EDA con la ayuda de un conjunto de datos de ejemplo. Usaremos Pitón idioma (Pandas biblioteca) para este propósito.

Importación de bibliotecas
Comenzaremos importando las bibliotecas que necesitaremos para realizar EDA. Estos incluyen NumPy, Pandas, Matplotlib y Seaborn.
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns
Leer datos
Ahora leeremos los datos de un archivo CSV en un Pandas DataFrame. Usted puede descargar el conjunto de datos para tu referencia.
df = pd.read_csv(r'C:UsersVipinData AnalyticsStudentsPerformance.csv')
Echemos un vistazo a cómo se ve nuestro conjunto de datos usando df.head (). La salida debería verse así:
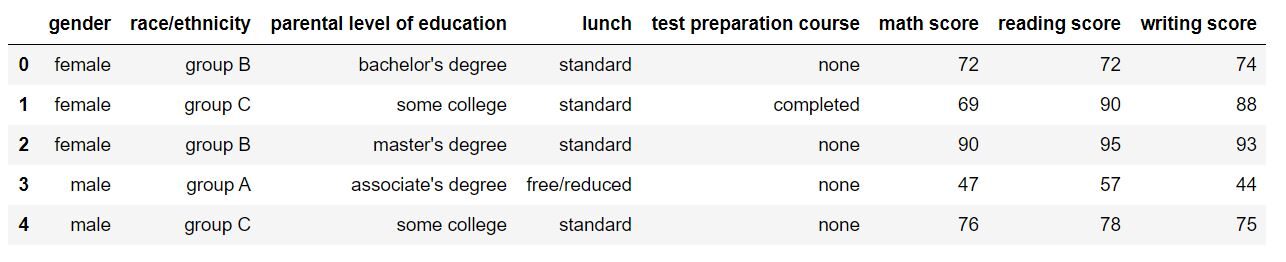
Estadísticas descriptivas
¡Perfecto! Los datos se ven exactamente como queríamos. Puede saber fácilmente con solo mirar el conjunto de datos que contiene datos sobre diferentes estudiantes en una escuela / universidad y sus puntajes en 3 materias. Comencemos mirando los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... estadísticos descriptivos para el conjunto de datos. Usaremos describe () para esto.
df.describe(include="all")
Al asignar al atributo de inclusión un valor de ‘todos’, nos aseguramos de que las características categóricas también se incluyan en el resultado. El DataFrame de salida debería verse así:
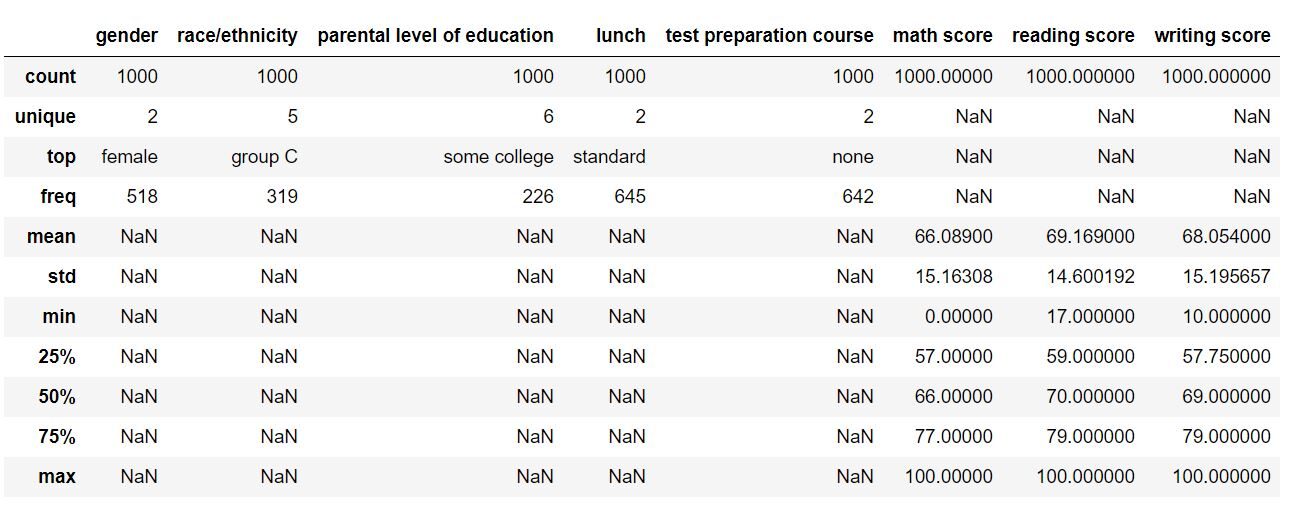
Para los parámetros numéricos, se completaron campos como la media, la desviación estándar, los percentiles y el máximo. Para las características categóricas, se han completado el recuento, el único, el superior (valor más frecuente) y la frecuencia correspondiente. Esto nos da una idea amplia de nuestro conjunto de datos.
Imputación de valor faltante
Ahora comprobaremos si faltan valores. en nuestro conjunto de datos. En caso de que falten entradas, las imputaremos con los valores apropiados (moda en caso de característica categórica y medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... o media en caso de característica numérica). Usaremos la función isnull () para este propósito.
df.isnull().sum()
Esto nos dirá cuántos valores faltantes tenemos en cada columna de nuestro conjunto de datos. La salida (Serie Pandas) debería verse así:

Afortunadamente para nosotros, no faltan valores en este conjunto de datos. Ahora procederemos a analizar este conjunto de datos, observar patrones e identificar valores atípicos con la ayuda de gráficos y figuras.
Representación grafica
Empezaremos con Análisis univariado. Usaremos un gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad.... para este propósito. Observaremos la distribución de los estudiantes por género, raza / etnia, su estado de almuerzo y si tienen un curso de preparación para el examen o no.
plt.subplot(221) df['gender'].value_counts().plot(kind='bar', title="Gender of students", figsize=(16,9)) plt.xticks(rotation=0) plt.subplot(222) df['race/ethnicity'].value_counts().plot(kind='bar', title="Race/ethnicity of students") plt.xticks(rotation=0) plt.subplot(223) df['lunch'].value_counts().plot(kind='bar', title="Lunch status of students") plt.xticks(rotation=0) plt.subplot(224) df['test preparation course'].value_counts().plot(kind='bar', title="Test preparation course") plt.xticks(rotation=0) plt.show()
La salida debería verse así:
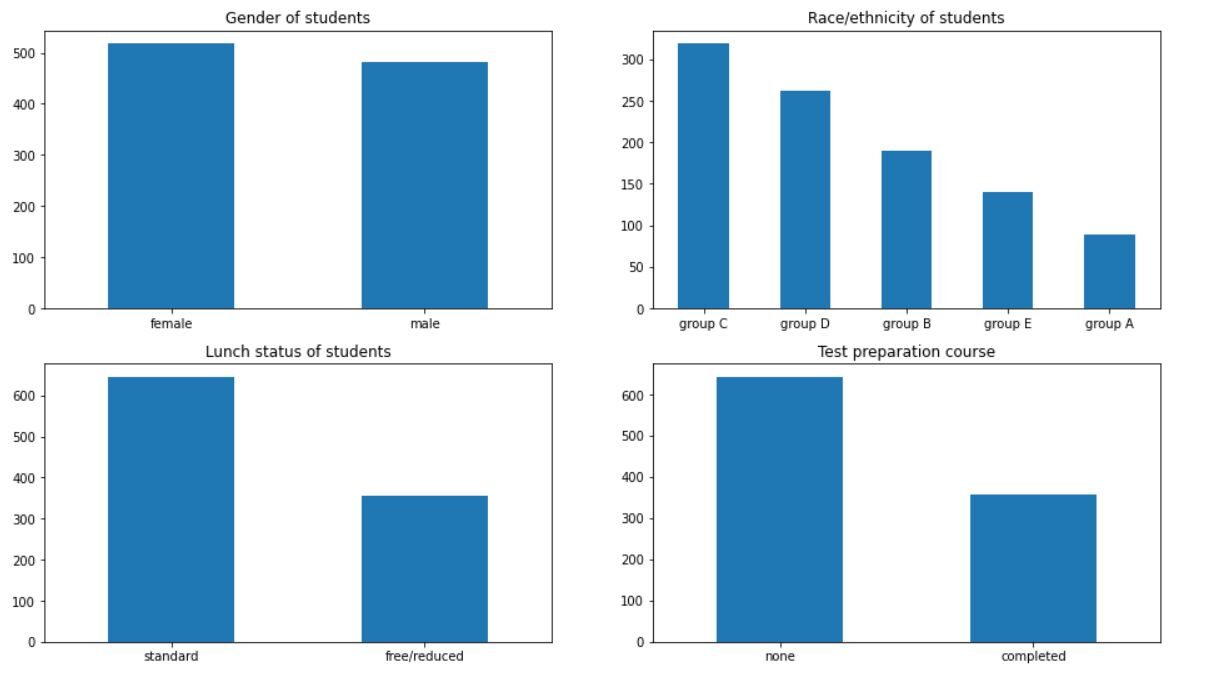
Podemos inferir muchas cosas del gráfico. Hay más niñas en la escuela que niños. La mayoría de los estudiantes pertenecen a los grupos C y D. Más del 60% de los estudiantes tienen un almuerzo estándar en la escuela. Además, más del 60% de los estudiantes no ha realizado ningún curso de preparación para exámenes.
Continuando con el análisis univariante, a continuación, haremos un diagrama de caja de las columnas numéricas (puntuación de matemáticas, puntuación de lectura y puntuación de escritura) en el conjunto de datos. Un diagrama de caja nos ayuda a visualizar los datos en términos de cuartiles. También identifica valores atípicos en el conjunto de datos, si los hubiera. Usaremos la función boxplot () para esto.
df.boxplot()
La salida debería verse así:
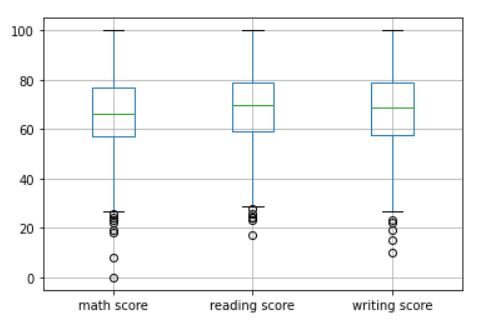
La porción del medio representa el rango intercuartil (IQR). La línea verde horizontal en el medio representa la mediana de los datos. Los círculos huecos cerca de las colas representan valores atípicos en el conjunto de datos. Sin embargo, dado que es muy posible que un estudiante obtenga calificaciones extremadamente bajas en una prueba, no eliminaremos estos valores atípicos.
Ahora haremos un parcela de distribución de la puntuación de matemáticas de los estudiantes. Una gráfica de distribución nos dice cómo se distribuyen los datos. Usaremos la función distplot.
sns.distplot(df['math score'])
La trama en la salida debería verse así:
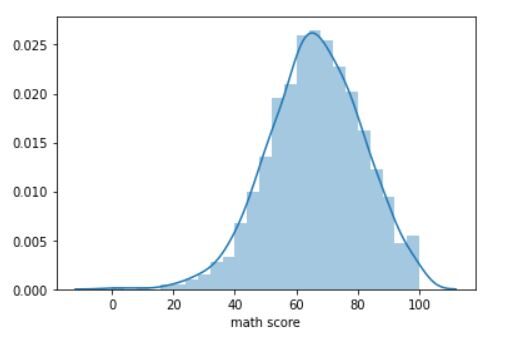
El gráfico representa una curva de campana perfecta de cerca. El pico es de alrededor de 65 puntos, la media de la puntuación de matemáticas de los estudiantes en el conjunto de datos. También se puede hacer una gráfica de distribución similar para las puntuaciones de lectura y escritura.
Ahora veremos la correlación entre las 3 puntuaciones con la ayuda de un mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas..... Para esto, usaremos la función corr () y heatmap () para este ejercicio.
corr = df.corr() sns.heatmap(corr, annot=True, square=True) plt.yticks(rotation=0) plt.show()
La trama en la salida debería verse así:
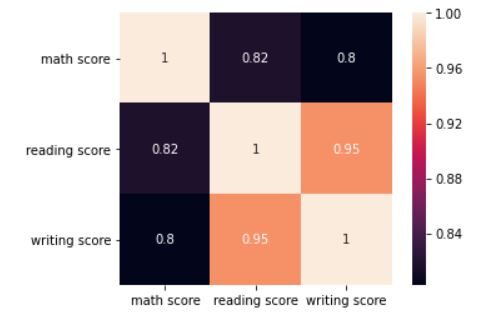
El mapa de calor muestra que las 3 puntuaciones están muy correlacionadas. La puntuación de lectura tiene un coeficiente de correlación de 0,95 con la puntuación de escritura. La puntuación de matemáticas tiene un coeficiente de correlación de 0,82 con la puntuación de lectura y 0,80 con la puntuación de escritura.
Ahora pasaremos a Análisis bivariado. Miraremos un trama relacional en Seaborn. Nos ayuda a comprender la relación entre 2 variables en diferentes subconjuntos del conjunto de datos. Intentaremos comprender la relación entre la puntuación de matemáticas y la puntuación de escritura de estudiantes de diferentes géneros.
sns.relplot(x='math score', y='writing score', hue="gender", data=df)
La trama relacional debería verse así:
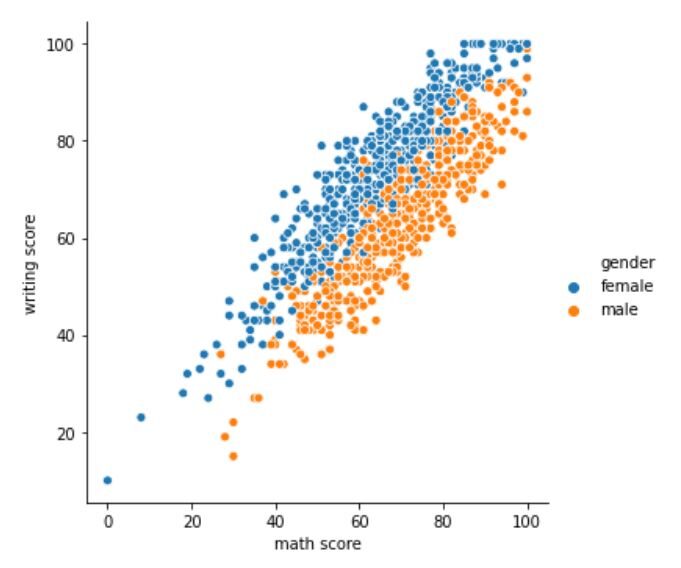
El gráfico muestra una clara diferencia en las puntuaciones entre los alumnos y las alumnas. Para el mismo puntaje en matemáticas, las estudiantes mujeres tienen más probabilidades de tener un puntaje de escritura más alto que los estudiantes varones. Sin embargo, para el mismo puntaje de escritura, se espera que los estudiantes varones obtengan un puntaje en matemáticas más alto que las estudiantes.
Las gráficas relacionales nos ayudan a realizar análisis bivariados. Puede consultar la documentación de la función relplot () en Seaborn aquí.
Finalmente, analizaremos el desempeño de los estudiantes en matemáticas, lectura y escritura según el nivel de educación de sus padres y el curso de preparación para el examen. Primero, echemos un vistazo al impacto del nivel de educación de los padres en el desempeño de sus hijos en la escuela usando un gráfico de línea.
df.groupby('parental level of education')[['math score', 'reading score', 'writing score']].mean().T.plot(figsize=(12,8))
La salida se verá así:
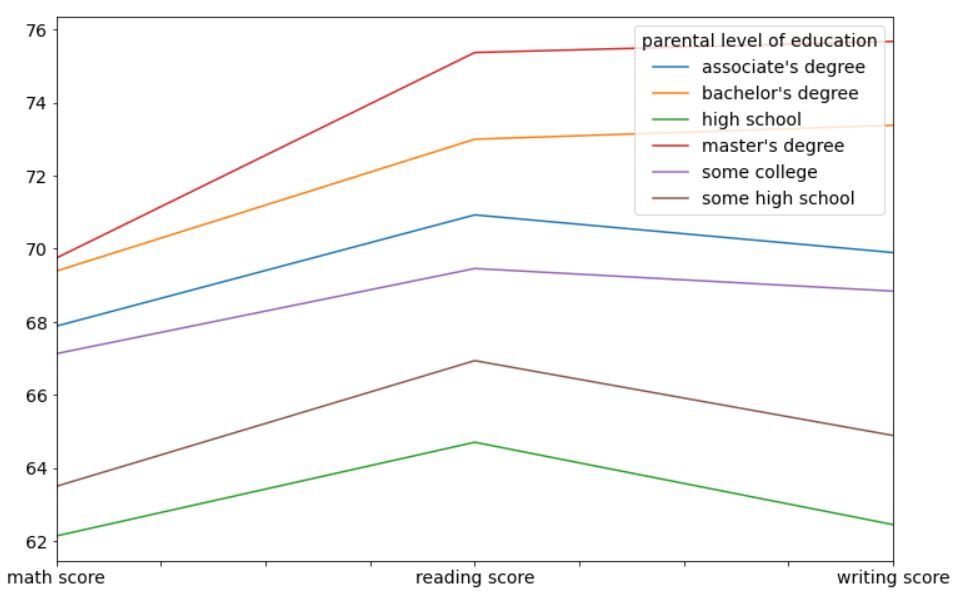
Es muy claro en este gráfico que los estudiantes cuyos padres tienen más educación que otros (maestría, licenciatura y título de asociado) tienen un mejor desempeño en promedio que los estudiantes cuyos padres tienen menos educación (escuela secundaria). Esto puede ser una diferencia genética o simplemente una diferencia en el entorno de los estudiantes en el hogar. Los padres más educados tienen más probabilidades de impulsar a sus estudiantes hacia los estudios.
En segundo lugar, veamos el impacto del curso de preparación para exámenes en el desempeño de los estudiantes utilizando un gráfico de barras horizontales.
df.groupby('test preparation course')[['math score', 'reading score', 'writing score']].mean().T.plot(kind='barh', figsize=(10,10))
La salida debería verse así:
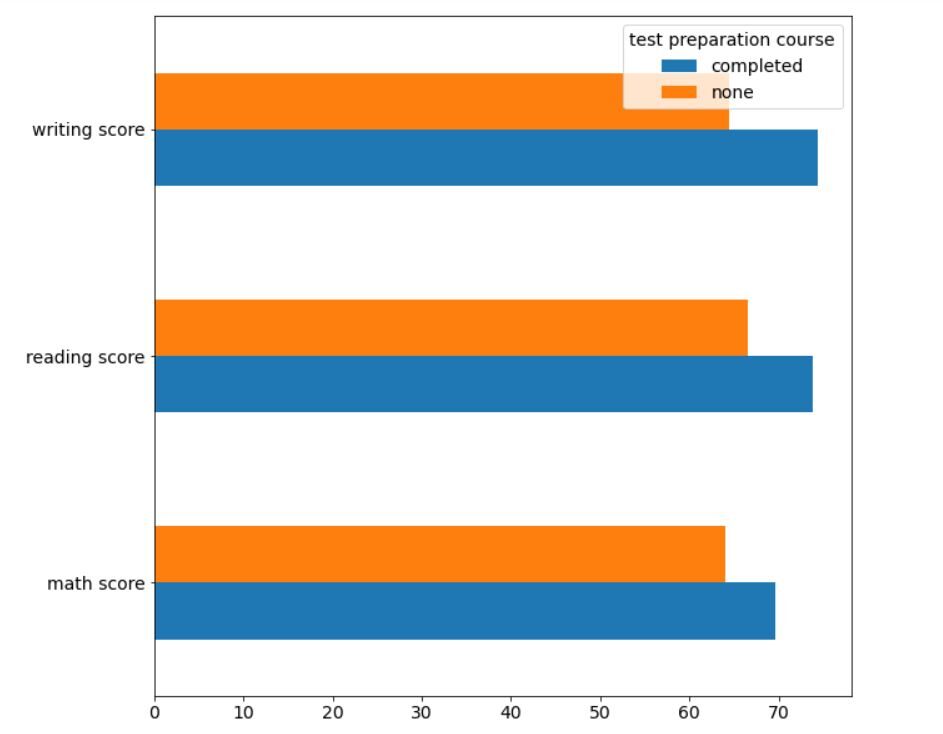
Una vez más, está muy claro que los estudiantes que han completado el curso de preparación para el examen se han desempeñado mejor, en promedio, en comparación con los estudiantes que no han optado por el curso.
Notas finales
En este artículo, entendimos el significado de Análisis de datos exploratorios (EDA) con la ayuda de un conjunto de datos de ejemplo. Observamos cómo podemos analizar el conjunto de datos, sacar conclusiones del mismo y formar una hipótesis basada en eso.
El autor de este artículo es Vishesh Arora. Puedes conectarte conmigo en LinkedIn.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





