Visión general
- Enfoque paso a paso para realizar EDA
- Recursos como blogs, MOOCS para familiarizarse con EDA
- Familiarizarse con diversas técnicas de visualización de datos, gráficos y diagramas.
- Demostración de algunos pasos con el fragmento de código de Python
¿Qué es lo que diferencia a un profesional de la ciencia de datos del otro?
No es aprendizaje automático, no es aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud..., no es SQL, es análisis de datos exploratorio (EDA). Qué tan bueno es uno con la identificación de patrones / tendencias ocultos de los datos y qué tan valiosos son los conocimientos extraídos, es lo que diferencia a los profesionales de datos.
1. ¿Qué es el análisis de datos exploratorios?
El análisis exploratorio de datos es un enfoque para analizar conjuntos de datos para resumir sus características principales, a menudo utilizando gráficos estadísticos y otros métodos de visualización de datos.
EDA ayuda a los profesionales de la ciencia de datos de varias maneras: –
1 Obtener una mejor comprensión de los datos
2 Identificar varios patrones de datos
3 Comprender mejor el planteamiento del problema
[ Note: the datasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.... in this blog is being opted as iris dataset]
2. Comprobación de los detalles introductorios sobre los datos
El primer y más importante paso de cualquier análisis de datos, después de cargar el archivo de datos, debe consistir en verificar algunos detalles introductorios. como, no. De columnas, no. de filas, tipos de características (categóricas o numéricas), tipos de datos de entradas de columna.
Fragmento de código de Python
data.info ()
RangeIndex: 150 entradas, 0 a 149
Columnas de datos (5 columnas en total):
# Columna Tipo de recuento no nulo
– —— ————– —–
0 sepal_length 150 no nulo float64
1 sepal_width 150 float64 no nulo
2 petal_length 150 no nulo float64
3 petal_width 150 no nulo float64
4 especies 150 objeto no nulo
dtypes: float64 (4), objeto (1)
uso de memoria: 6.0+ KB
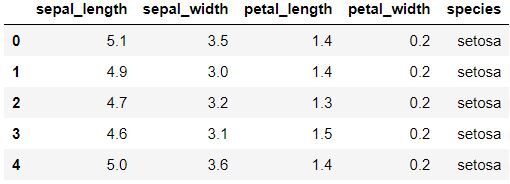
data.head () Para mostrar las primeras cinco filas
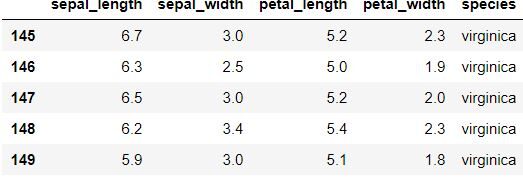
data.tail () para mostrar las últimas cinco filas
3. Perspectiva estadística
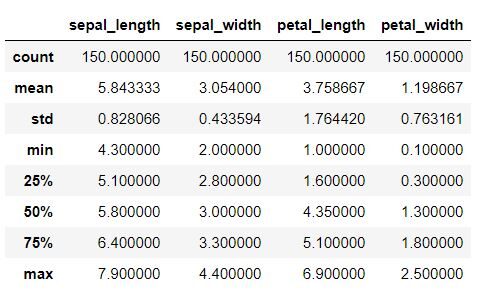
Este paso debe realizarse para obtener detalles sobre varios datos estadísticos como media, desviación estándar, medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos...., valor máximo, valor mínimo.
Fragmento de código de Python
data.describe ()
4. Limpieza de datos
Este es el paso más importante en EDA que implica eliminar filas / columnas duplicadas, llenar las entradas vacías con valores como la media / mediana de los datos, eliminar varios valores, eliminar entradas nulas
Comprobación de entradas nulas
Fragmento de código de Python
data.IsNull (). sum da el número de valores perdidos para cada variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos....
Eliminar entradas nulas
Fragmento de código de Python
data.dropna (axis = 0, inplace = True) Si hay entradas nulas
Rellenar valores en lugar de entradas nulas (si es una función numérica)
Los valores pueden ser la media, la mediana o cualquier número entero
Fragmento de código de Python
datos[“sepal_length”].fillna (valor = datos[“sepal_length”].mean (), inplace = True) si hay una entrada nula
Comprobación de duplicados
Fragmento de código de Python
data.duplicated (). sum () devuelve el número total de entradas duplicadas
Eliminar duplicados
Fragmento de código de Python
data.drop_duplicates (inplace = True)
5. Visualización de datos
La visualización de datos es el método de convertir datos sin procesar en una forma visual, como un mapa o gráfico, para que los datos sean más fáciles de entender y extraer información útil..
El objetivo principal de la visualización de datos es poner grandes conjuntos de datos en una representación visual. Es uno de los pasos importantes y sencillos cuando se trata de ciencia de datos.
Puede consultar el blog a continuación para obtener más detalles sobre la visualización de datos.
Varios tipos de análisis de visualización son:
una. Análisis univariado:
Esto muestra cada observación / distribución de datos en una sola variable de datos.. Se puede mostrar con la ayuda de varios diagramas como diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada...., diagrama de líneas, diagrama de histograma (resumen), diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos...., diagrama de violínEl diagrama de violín es una representación gráfica que combina características de un boxplot y un gráfico de densidad. Se utiliza para visualizar la distribución de un conjunto de datos, mostrando tanto la mediana como la variabilidad a través de su forma, que se asemeja a un violín. Este tipo de gráfico es muy útil en análisis estadísticos, ya que permite comparar múltiples distribuciones de forma clara y efectiva...., etc.
B. Análisis bi-variable:
Se realizan pantallas de análisis bivariante para revelar la relación entre dos variables de datos. También se puede mostrar con la ayuda de diagramas de dispersión, histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas...., mapas de calor, diagramas de caja, diagramas de violín, etc.
C. Analisis multivariable:
El análisis multivariado, como sugiere el nombre, se muestran para revelar la relación entre más de dos variables de datos.
Los diagramas de dispersión, histogramas, diagramas de caja, diagramas de violín se pueden utilizar para análisis multivariante
Varias parcelas
A continuación se muestran algunos de los gráficos que se pueden implementar para análisis univariante, bivariado y multivariado
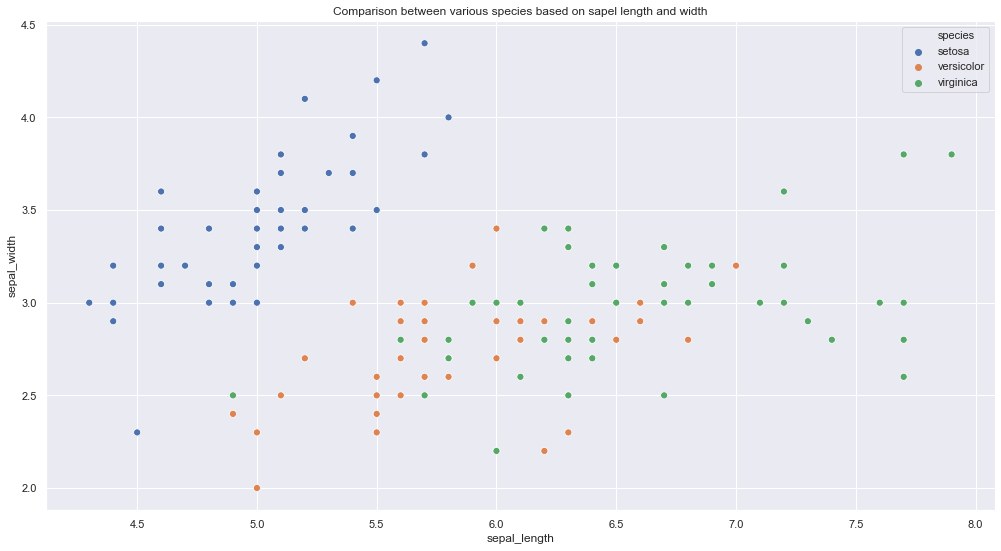
una. Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....
Fragmento de código de Python
plt.figure (figsize = (17,9))
plt.title (‘Comparación entre varias especies según la longitud y el ancho del sapel’)
sns.scatterplot (datos[‘sepal_length’],datos[‘sepal_width’], tono = datos[‘species’], s = 50)
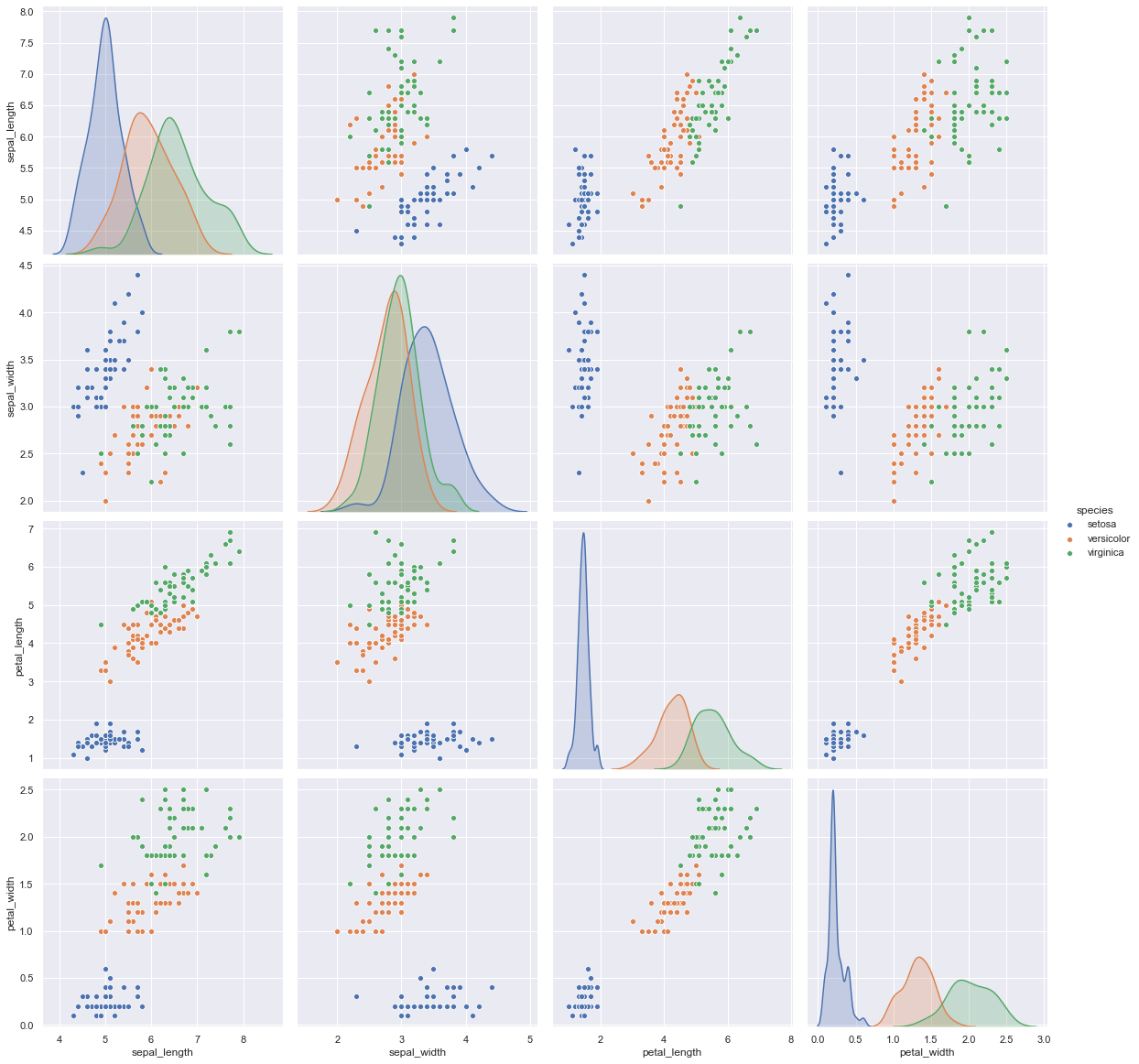
Para análisis multivariado
Fragmento de código de Python
sns.pairplot (data, hue = ”especie”, altura = 4)
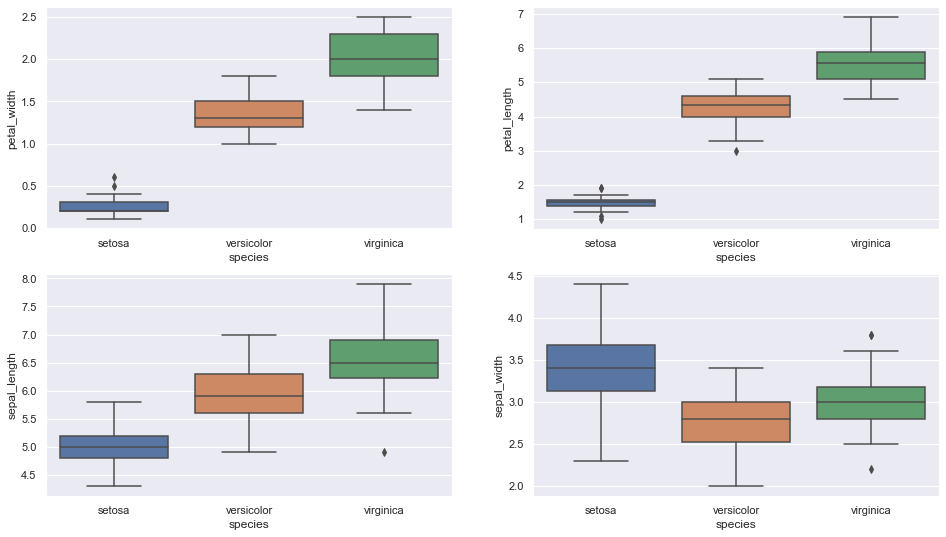
B. Diagrama de caja
Diagrama de caja para ver cómo se distribuye la característica categórica «Especie» con las otras cuatro variables de entrada
Fragmento de código de Python
fig, axes = plt.subplots (2, 2, figsize = (16,9))
sns.boxplot (y = «petal_width», x = «especie», data = iris_data, orient = ‘v’, ax = axes[0, 0])
sns.boxplot (y = «petal_length», x = «especie», data = iris_data, orient = ‘v’, ax = axes[0, 1])
sns.boxplot (y = ”sepal_length”, x = “especie”, data = iris_data, orient = ‘v’, ax = axes[1, 0])
sns.boxplot (y = «sepal_width», x = «especie», data = iris_data, orient = ‘v’, ax = ejes[1, 1])
plt.show ()
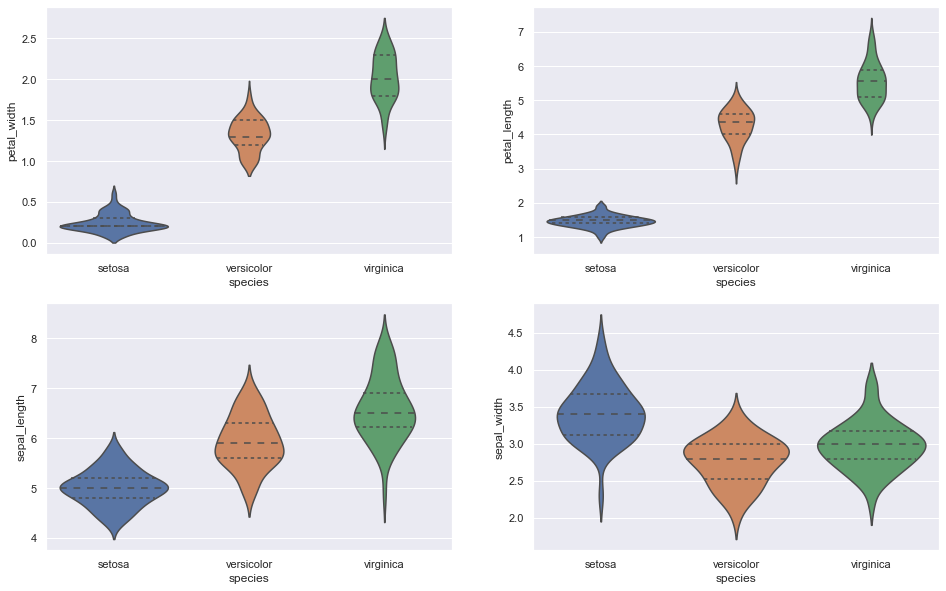
C. Trama de violín
Más informativo que el diagrama de caja y muestra la distribución completa de los datos.
Fragmento de código de Python
fig, axes = plt.subplots (2, 2, figsize = (16,10))
sns.violinplot (y = ”petal_width”, x = “especie”, data = iris_data, orient = ‘v’, ax = axes[0, 0], inner = ‘cuartil’)
sns.violinplot (y = «petal_length», x = «especie», data = iris_data, orient = ‘v’, ax = ejes[0, 1], inner = ‘cuartil’)
sns.violinplot (y = ”sepal_length”, x = “especie”, data = iris_data, orient = ‘v’, ax = axes[1, 0], inner = ‘cuartil’)
sns.violinplot (y = ”sepal_width”, x = “especie”, data = iris_data, orient = ‘v’, ax = axes[1, 1], inner = ‘cuartil’)
plt.show ()
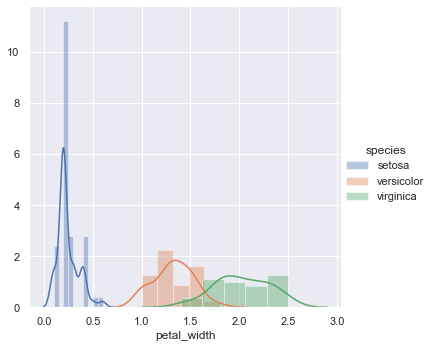
D. Histogramas
Se puede utilizar para visualizar la función de densidad de probabilidad (PDF)
Fragmento de código de Python
sns.FacetGrid (iris_data, hue = ”especie”, altura = 5)
.map (sns.distplot, «petal_width»)
.add_legend ();
Con esto termino este blog.
Hola a todos, Namaste
Me llamo Pranshu Sharma y soy un entusiasta de la ciencia de datos
Muchas gracias por tomarse su valioso tiempo para leer este blog. No dude en señalar cualquier error (después de todo, soy un aprendiz) y proporcionar los comentarios correspondientes o dejar un comentario.
Dhanyvaad !!
Realimentación:
Correo electrónico: [email protected]
Puede consultar el blog que se menciona a continuación para familiarizarse con el análisis de datos exploratorios.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





