Este artículo fue publicado como parte del Blogatón de ciencia de datos.
«Para ganar en el mercado, debes ganar en el lugar de trabajo» –Steve Jobs, fundador de Apple Inc.
Introducción
¿Por qué utilizamos la regresión logística para analizar la deserción de empleados?
Si un empleado se va a quedar o dejar una empresa, su respuesta es simplemente binomial, es decir, puede ser «SÍ» o «NO». Entonces, podemos ver que nuestra variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente Desgaste de empleados es solo una variable categórica. En el caso de una variable categórica dependiente, no podemos usar regresión lineal, en ese caso, tenemos que usar “REGRESIÓN LOGÍSTICA“.
Metodología
Aquí, voy a usar 5 pasos simples para analizar el desgaste de los empleados usando el software R
- RECOPILACIÓN DE DATOS
- PREPROCESAMIENTO DE DATOS
- DIVIDIENDO LOS DATOS EN DOS PARTES «ENTRENAMIENTO» Y «PRUEBAS»
- CONSTRUYA EL MODELO CON EL «CONJUNTO DE DATOS DE ENTRENAMIENTO»
- HAGA LA PRUEBA DE PRECISIÓN USANDO EL «CONJUNTO DE DATOS DE PRUEBA»
Exploración de datos
Este conjunto de datos se recopila del departamento de Recursos Humanos de IBM. El conjunto de datos contiene 1470 observaciones y 35 variables. Dentro de 35 variables, “Desgaste” es la variable dependiente.
Un vistazo rápido al conjunto de datos:
Echar un vistazo:
Preparación de datos
-
Cambiar los tipos de datos:
En primer lugar, tenemos que cambiar el tipo de datos de la variable dependiente «Desgaste». Se da en forma de “Sí” y “No”, es decir, es una variable categórica. Para hacer un modelo adecuado tenemos que convertirlo en forma numérica. Para ello, asignaremos el valor 1 a “Sí” y el valor 0 a “No” y lo convertiremos en numérico.
JOB_Attrition$Attrition[JOB_Attrition$Attrition=="Yes"]=1 JOB_Attrition$Attrition[JOB_Attrition$Attrition=="No"]=0 JOB_Attrition$Attrition=as.numeric(JOB_Attrition$Attrition)
próximo, cambiaremos todas las variables de «carácter» a «Factor»
Hay 8 variables de carácter: viajes de negocios, departamento, educación, campo educativo, género, función laboral, estado civil, a lo largo del tiempo. Los números de columna son 2, 4, 6, 7, 11, 15, 17, 22 respectivamente.
JOB_Attrition[,c(2,4,6,7,11,15,17,22)]=lapply(JOB_Attrition[,c(2,4,6,7,11,15,17,22)],as.factor)
Finalmente, hay otra variable «Más de 18» que tiene todas las entradas como «Y». También es una variable de carácter. Nos transformaremos en numérico ya que solo tiene un nivel por lo que transformar en factor no dará un buen resultado. Para ello, asignaremos el valor 1 a “Y” y lo transformaremos en numérico.
JOB_Attrition$Over18[JOB_Attrition$Over18=="Y"]=1 JOB_Attrition$Over18=as.numeric(JOB_Attrition$Over18)
Dividir el conjunto de datos en «entrenamiento» y «prueba»
En cualquier análisis de regresión, tenemos que dividir el conjunto de datos en 2 partes:
- CONJUNTO DE DATOS DE ENTRENAMIENTOEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....
- JUEGO DE DATOS DE PRUEBA
Con la ayuda del conjunto de datos de entrenamiento, crearemos nuestro modelo y probaremos su precisión utilizando el conjunto de datos de prueba.
set.seed(1000)
ranuni=sample(x=c("Training","Testing"),size=nrow(JOB_Attrition),replace=T,prob=c(0.7,0.3))
TrainingData=JOB_Attrition[ranuni=="Training",]
TestingData=JOB_Attrition[ranuni=="Testing",]
nrow(TrainingData)
nrow(TestingData)
Hemos dividido con éxito todo el conjunto de datos en dos partes. Ahora tenemos 1025 Datos de entrenamiento y 445 Datos de prueba.
Construyendo el modelo
Ahora vamos a construir el modelo siguiendo unos sencillos pasos como sigue:
- Identificar las variables independientes
- Incorporar la variable dependiente «Desgaste» en el modelo.
- Transformar el tipo de datos del modelo de «carácter» a «fórmula»
- Incorporar datos de ENTRENAMIENTO en la fórmula y construir el modelo
independentvariables=colnames(JOB_Attrition[,2:35])
independentvariables
Model=paste(independentvariables,collapse="+")
Model
Model_1=paste("Attrition~",Model)
Model_1
class(Model_1)
formula=as.formula(Model_1)
formula
Producción:

Próximo, Incorporaremos “Datos de entrenamiento” en la fórmula usando la función “glm” y construiremos un modelo de regresión logística.
Trainingmodel1=glm(formula=formula,data=TrainingData,family="binomial")
Ahora, vamos a diseñar el modelo por el «Selección paso a paso”Método para obtener variables significativas del modelo. La ejecución del código nos dará una lista de salida donde se agregan y eliminan las variables en función de nuestra importancia del modelo. El valor de AIC en cada nivel refleja la bondad del modelo respectivo. A medida que el valor sigue cayendo, se obtiene un modelo de regresión logística que se ajusta mejor.
La aplicación del resumen sobre el modelo final nos dará la lista de variables significativas finales y su respectiva información importante.
Trainingmodel1=step(object = Trainingmodel1,direction = "both") summary(Trainingmodel1)
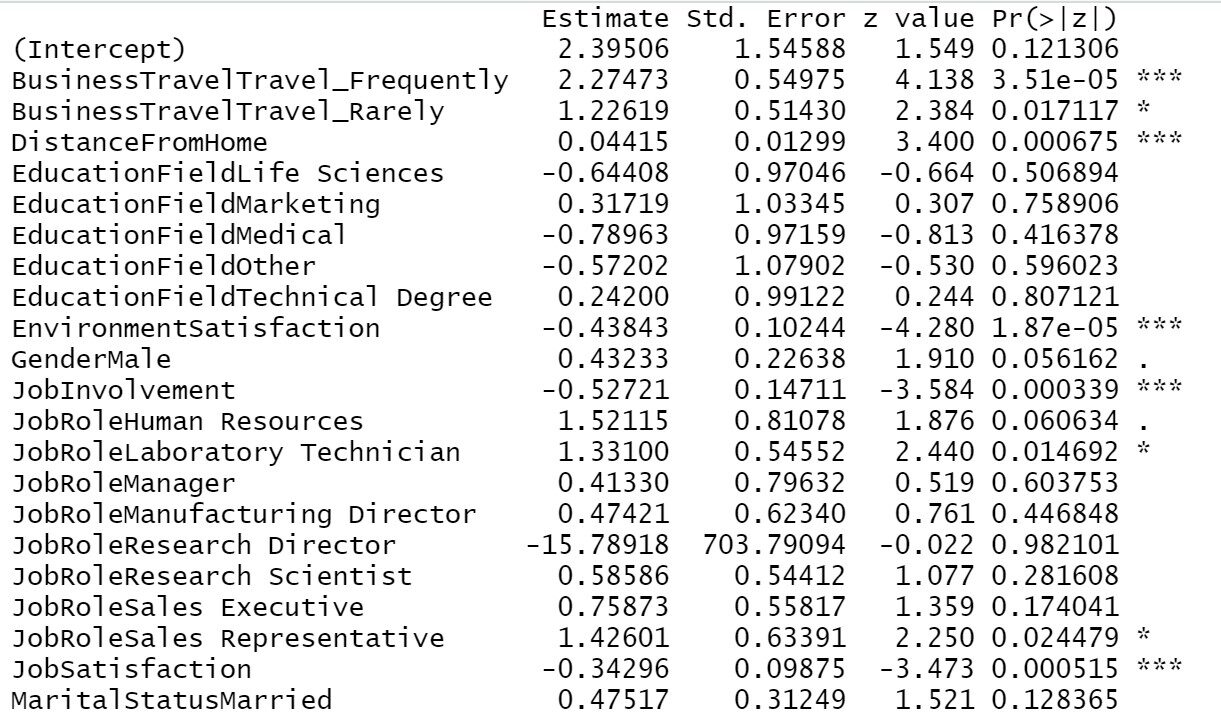
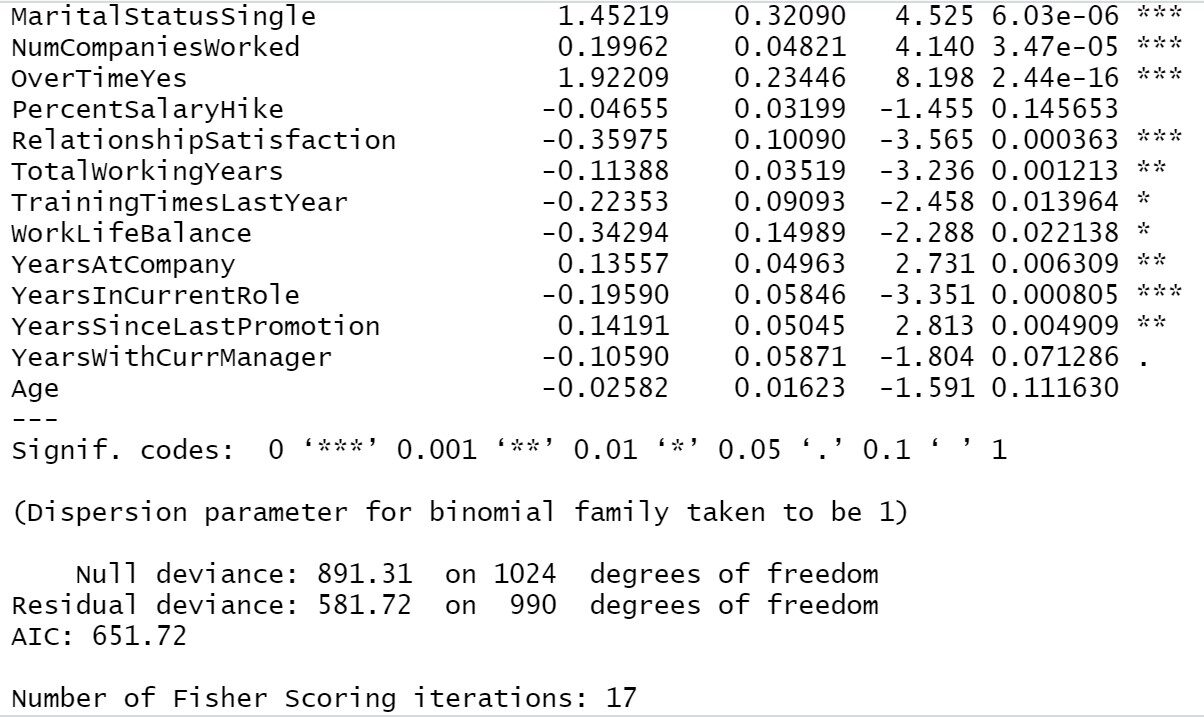
De nuestro resultado anterior podemos ver, Viajes de negocios, Distancia desde casa, Satisfacción con el medio ambiente, Implicación laboral, Satisfacción laboral, Estado civil, Número de empresas trabajadas, A lo largo del tiempo, Satisfacción en las relaciones, Años laborales totales, Años en la empresa, años desde la última promoción, años en el puesto actual todas estas son las variables más importantes para determinar la deserción de los empleados. Si la empresa se ocupa principalmente de estas áreas, habrá menos posibilidades de perder un empleado.
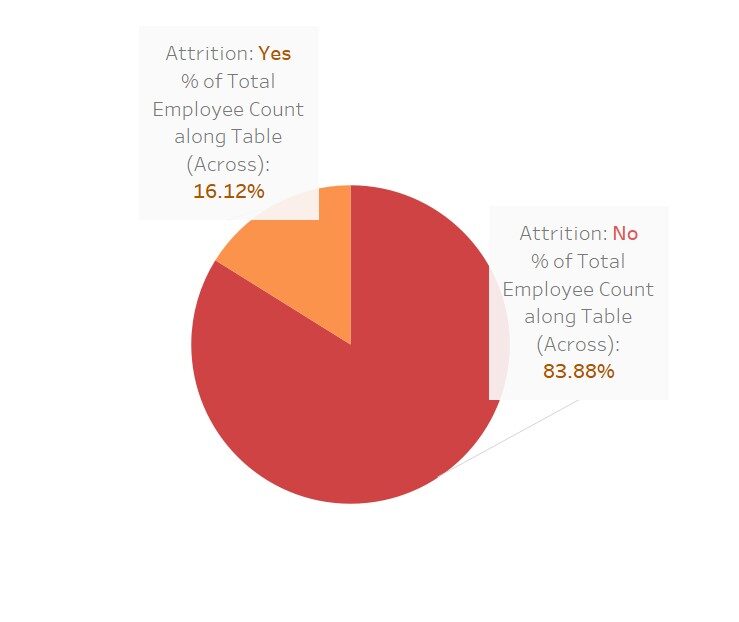
Una visualización rápida para ver cuánto afectan estas variables al «desgaste»
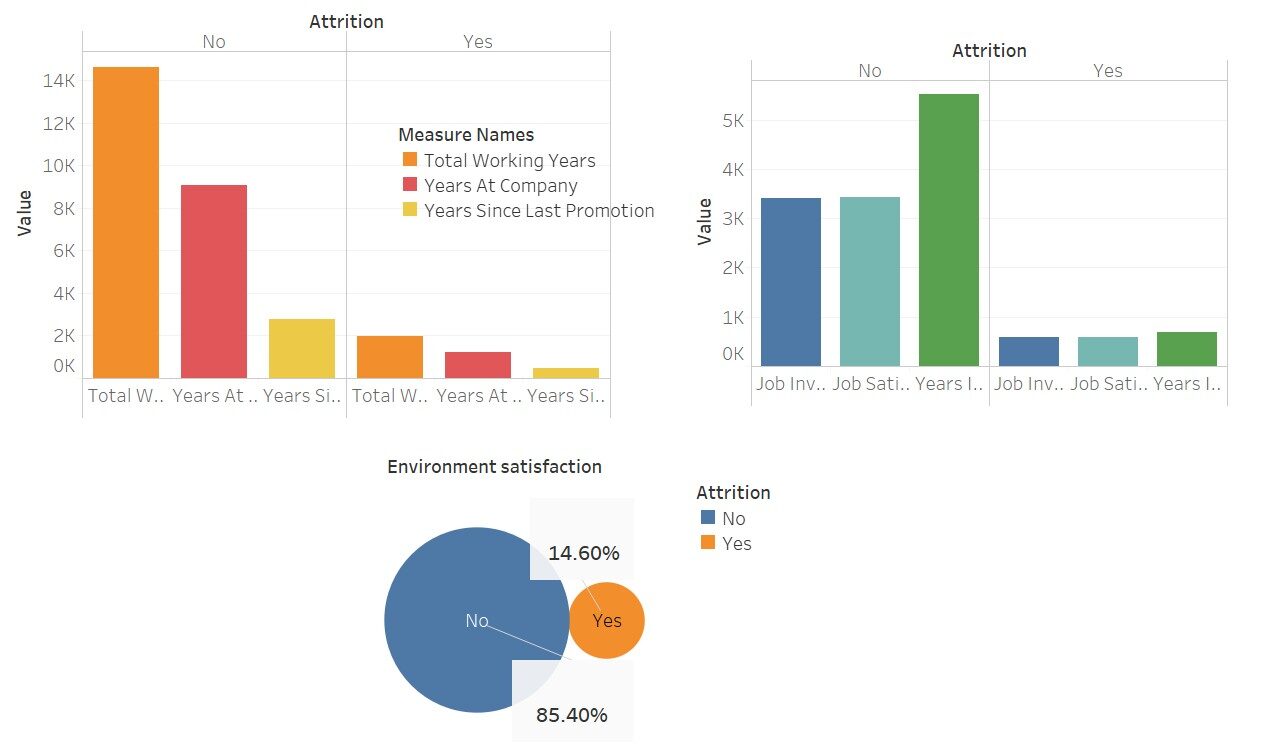
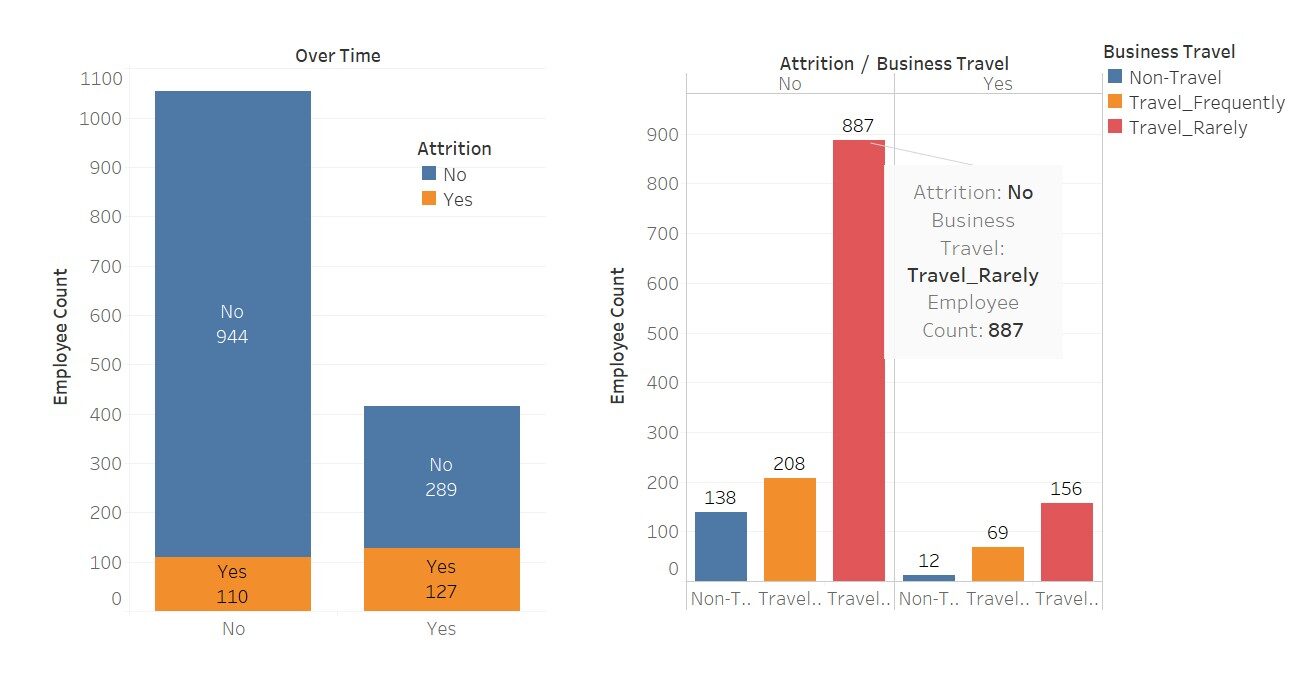
Aquí he usado Tableau para estas visualizaciones; no es hermoso Este software simplemente facilita nuestro trabajo.
Ahora, podemos realizar el espectáculo de Hoshmer-Lemes prueba de bondad de ajuste en el conjunto de datos, para juzgar la precisión de la probabilidad predicha del modelo.
La hipótesis es:
H0: El modelo encaja bien.
H1: El modelo no encaja bien.
Si, valor p> 0,05 aceptaremos H0 y rechazaremos H1.
Para realizar la prueba en R necesitamos instalar el mkMisc paquete.
HLgof.test(fit=Trainingmodel1$fitted.values,obs=Trainingmodel1$y)

Aquí, podemos ver que el valor p es mayor que 0.05, por lo tanto aceptaremos H0. Ahora, está probado que nuestro modelo está bien ajustado.
Generando una curva ROC para datos de entrenamiento
Otra técnica para analizar la bondad del ajuste de la regresión logística es la Medidas ROC (características operativas del receptor). Las medidas de ROC son sensibilidad, especificidad 1, falso positivo y falso negativo. Las dos medidas que usamos ampliamente son la sensibilidad y la especificidad. La sensibilidad mide la bondad de la precisión del modelo, mientras que la especificidad mide la debilidad del modelo.
Para hacer esto en R necesitamos instalar un paquete pROC.
troc=roc(response=Trainingmodel1$y,predictor = Trainingmodel1$fitted.values,plot=T) troc$auc
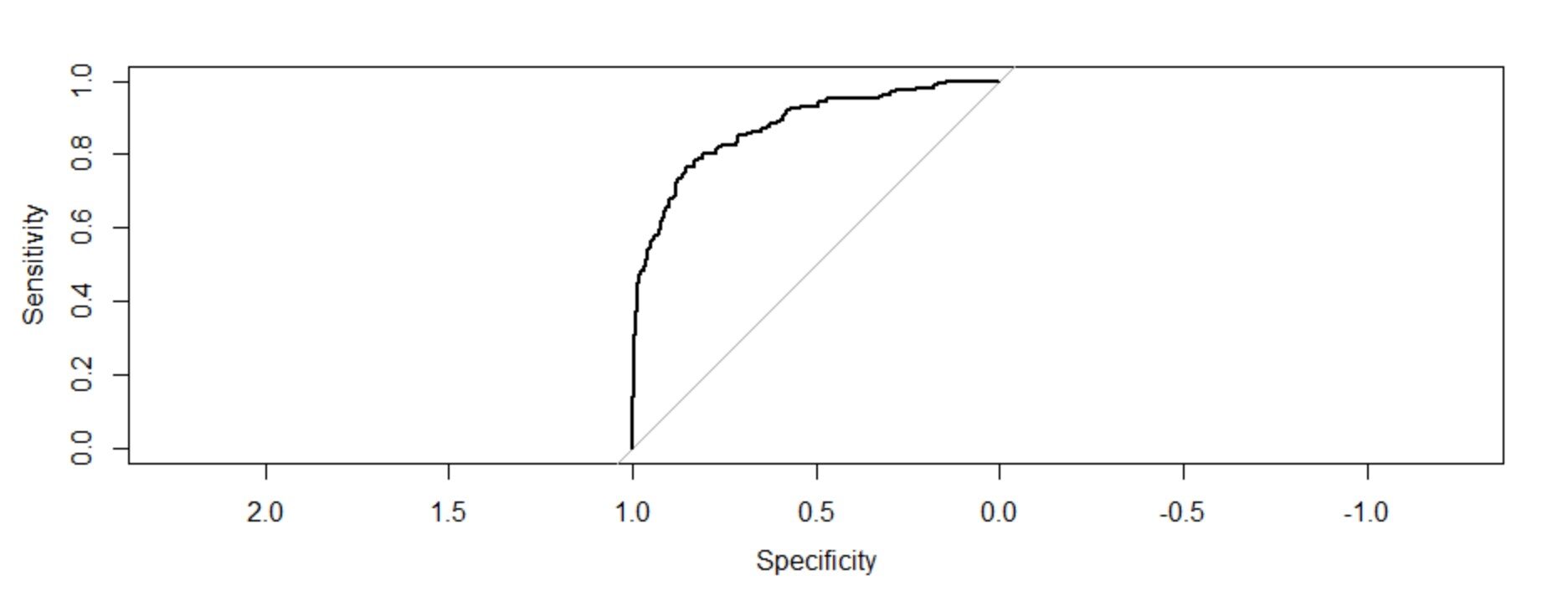
El área debajo de la curva: 0.8759
Interpretación de la figura:
La gráfica de estas dos medidas nos da una gráfica cóncava que muestra como la sensibilidad está aumentando 1-la especificidad está aumentando pero a un ritmo decreciente. El valor C (AUC) o el valor del índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de concordancia da la medida del área bajo la curva ROC. Si c = 0,5, habría significado que el modelo no puede discriminar perfectamente entre 0 y 1 respuestas. Entonces implica que el modelo inicial no puede decir perfectamente qué empleados se van a ir y quiénes se van a quedar.
Pero aquí podemos ver que nuestro valor c es mucho mayor que 0.5. Es 0,8759. Nuestro modelo puede discriminar perfectamente entre 0 y 1. Por lo tanto, podemos concluir con éxito que es un modelo bien ajustado.
Creando la tabla de clasificación para el conjunto de datos de entrenamiento:
trpred=ifelse(test=Trainingmodel1$fitted.values>0.5,yes = 1,no=0) table(Trainingmodel1$y,trpred)
El código anterior establece, el valor predicho de la probabilidad mayor que 0, .5, entonces el valor del estado es 1, de lo contrario es 0. basado en este criterio, este código vuelve a etiquetar las respuestas «Sí» y «No» de «Desgaste». Ahora, es importante comprender el porcentaje de predicciones que coinciden con la creencia inicial obtenida del conjunto de datos. Aquí compararemos el par (1-1) y (0-0).
Tenemos 1025 datos de entrenamiento. Hemos predicho {(839 + 78) / 1025} * 100 =89% correctamente.
Comparando el resultado con los datos de prueba:
Ahora compararemos el modelo con los datos de prueba. Es muy parecido a una prueba de precisión.
testpred=predict.glm(object=Trainingmodel1,newdata=TestingData,type = "response") testpred tsroc=roc(response=TestingData$Attrition,predictor = testpred,plot=T) tsroc$auc
Ahora, hemos incorporado datos de prueba en el modelo de entrenamiento y veremos la República de China.
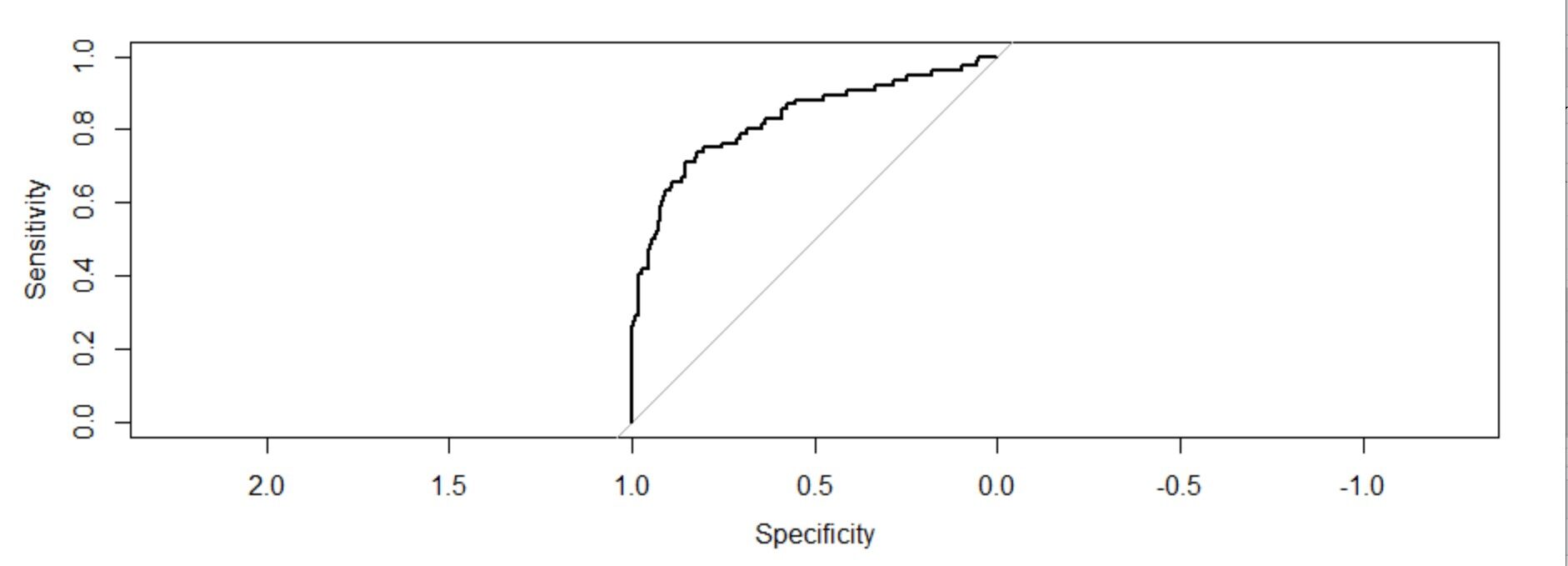
El área bajo la curva: 0,8286 (valor c). También es muy superior a 0,5. También es un modelo bien ajustado.
Crear la tabla de clasificación para el conjunto de datos de prueba
testpred=ifelse(test=testpred>0.5,yes=1,no=0) table(TestingData$Attrition,testpred)

Tenemos 445 datos de prueba. hemos predicho correctamente {(362 + 28) / 445} * 100 =87,64%.
Como consecuencia, podemos decir que nuestro modelo de regresión logística es un modelo muy bien ajustado. Cualquier conjunto de datos de deserción de empleados se puede analizar utilizando este modelo.
¿Qué crees que es un buen modelo? Comenta abajo
CONCLUSIÓN:
Hemos aprendido con éxito cómo analizar el desgaste de los empleados utilizando la “REGRESIÓN LOGÍSTICA” con la ayuda del software R. Solo con un par de códigos y un conjunto de datos adecuado, una empresa puede comprender fácilmente qué áreas deben cuidar para hacer que el lugar de trabajo sea más cómodo para sus empleados y restaurar la energía de sus recursos humanos durante un período más largo.
La imagen destacada está tomada de trainingjournal.com
Enlace a mi perfil de LinkedIn:
https://www.linkedin.com/in/tiasa-patra-37287b1b4/





