Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
En el artículo de hoy, hablaré sobre el desarrollo de una red neuronal convolucional que emplea la API funcional de TensorFlow. Dispensará la capacidad de API funcional, lo que nos permite producir una arquitectura de modelo híbrido que supera la capacidad de un modelo secuencial primario.
Acerca de: TensorFlow
TensorFlow es una biblioteca popular, algo que probablemente escuchas perpetuamente en la sociedad de Deep Learning e Inteligencia Artificial. Existen numerosos paquetes y proyectos de código abierto para el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
- TensorFlow, una biblioteca de inteligencia artificial de código abierto que administra gráficos de flujo de datos, es la biblioteca de aprendizaje profundo más común. Se utiliza para generar redes neuronales a gran escala con innumerables capas.
- TensorFlow se practica para el aprendizaje profundo o las situaciones de aprendizaje automático como Clasificación, Percepción, Percepción, Descubrimiento, Previsión y Producción.
Entonces, cuando interpretamos un problema de clasificación, aplicamos un modelo de red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora.... Aún así, la mayoría de los desarrolladores estaban familiarizados con el modelado de modelos secuenciales. Las capas se acompañan una a una.
- La API secuencial le permite diseñar modelos capa por capa para los problemas más importantes.
- La dificultad está restringida porque no le permite producir modelos que comparten capas o tienen entradas o salidas agregadas.
- Debido a esto, podemos practicar la API funcional de Tensorflows como modelo de salida múltiple.
API funcional (tf.Keras)
La API funcional en tf.Keras es una forma alternativa de construir modelos más flexibles, incluida la formulación de un modelo más complejo.
- Por ejemplo, al implementar un ejemplo insignificantemente más complicado con el aprendizaje automático, es posible que rara vez se enfrente al estado en el que exija modelos adicionales para los mismos datos.
- Entonces necesitaríamos producir dos salidas. La opción más manejable sería construir dos modelos separados basados en los datos correspondientes para hacer predicciones.
- Esto sería suave, pero ¿y si, en el escenario actual, tuviéramos que tener 50 resultados? Podría ser una molestia mantener todos esos modelos separados.
- Alternativamente, es más fructífero construir un modelo único con mejores resultados.
En el método de API abierta, los modelos se determinan formando capas y correlacionándolas directamente entre sí en conjuntos, luego se establece un Modelo que define las capas para que funcionen como entrada y salida.
¿Qué es diferente en la API secuencial?
La API secuencial le permite generar modelos capa por capa para la mayoría de las consultas principales. Está regulado porque no le permite diseñar modelos que compartan capas o tengan entradas o salidas agregadas.
Entendamos cómo crear un objeto de modelo de API secuencial a continuación:
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation=’relu’), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=’softmax’) ])
- En API funcional, puede diseñar modelos que produzcan mucha más versatilidad. Sin duda, puede corregir modelos en los que las capas se relacionan con más que las capas anteriores y posteriores.
- Puede combinar capas con varias otras capas. Como consecuencia, la producción de redes heterogéneas como las redes siamesas y las redes residuales se vuelve factible.
Comencemos a desarrollar un modelo de CNN practicando una API funcional
En esta publicación, utilizamos el conjunto de datos MNIST para construir la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... convolucional para la clasificación de imágenes. La base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... del MNIST comprende 60,000 imágenes de capacitación y 10,000 imágenes de prueba obtenidas de trabajadores de la Oficina del Censo de Estados Unidos y estudiantes de tercer año de secundaria estadounidenses.
# import libraries
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# convert sparse label to categorical values
num_labels = len(np.unique(y_train))
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# preprocess the input images
image_size = x_train.shape[1]
x_train = np.reshape(x_train,[-1, image_size, image_size, 1])
x_test = np.reshape(x_test,[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
En el código de arriba,
- Distribuí estos dos grupos como entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y prueba y distribuí las etiquetas y las entradas.
- Las variables independientes (x_train y x_test) contienen códigos RGB en escala de grises de 0 a 255, mientras que las variables dependientes (y_train e y_test) llevan etiquetas de 0 a 9, que describen qué número son realmente.
- Es una buena práctica normalizar nuestros datos, ya que se requiere constantemente en los modelos de aprendizaje profundo. Podemos lograr esto dividiendo los códigos RGB por 255.
A continuación, inicializamos los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para las redes.
# parameters for the network input_shape = (image_size, image_size, 1) batch_size = 128 kernel_size = 3 filters = 64 dropout = 0.3
En el código de arriba,
- input_shape: La variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... representa la necesidad de planificar y diseñar una capa de entradaLa "capa de entrada" se refiere al nivel inicial en un proceso de análisis de datos o en arquitecturas de redes neuronales. Su función principal es recibir y procesar la información bruta antes de que esta sea transformada por capas posteriores. En el contexto de machine learning, una adecuada configuración de la capa de entrada es crucial para garantizar la efectividad del modelo y optimizar su rendimiento en tareas específicas.... independiente que designe los datos de entrada. La capa de entrada acepta un argumento de forma que es una tupla que describe las dimensiones de los datos de entrada.
- tamaño del lote: es un hiperparámetro que determina la cantidad de muestras que se deben ejecutar antes de actualizar los parámetros internos del modelo.
- kernel_size: se relaciona con las dimensiones (altura x ancho) de la máscara de filtro. Las redes neuronales convolucionales (CNN) son esencialmente una pila de capas marcadas por las operaciones de varios filtros en la entrada. Estos filtros se denominan normalmente núcleos.
- filtrar: se expresa mediante un vector de pesos entre los que convolvemos la entrada.
- Abandonar: es un proceso en el que se descuidan las neuronas seleccionadas al azar durante el entrenamiento. Esto implica que su participación en la activación de las neuronas aguas abajo se descarta temporalmente en el pase frontal.
Definamos un perceptrón multicapa simplista, una red neuronal convolucional:
# utiliaing functional API to build cnn layers inputs = Input(shape=input_shape) y = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu')(inputs) y = MaxPooling2D()(y) y = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu')(y) y = MaxPooling2D()(y) y = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu')(y) # convert image to vector y = Flatten()(y) # dropout regularization y = Dropout(dropout)(y) outputs = Dense(num_labels, activation='softmax')(y) # model building by supplying inputs/outputs model = Model(inputs=inputs, outputs=outputs)
En el código de arriba,
- Especificamos un modelo de perceptrón multicapa hacia la clasificación binaria.
- El modelo contiene una capa de entrada, 3 capas ocultas junto a 64 neuronas y una capa de producto con 1 salida.
- Las funciones de activación lineal rectificadas se aplican en todas las capas ocultas, y se adopta una función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.... softmax en la capa de producto para la clasificación binaria.
- Y puede observar que las capas en el modelo están correlacionadas por pares. Esto se logra estipulando de dónde proviene la entrada mientras se determina cada nueva capa.
- Al igual que con todas las API secuenciales, el modelo es la información que podemos resumir, ajustar, evaluar y aplicar para ejecutar predicciones.
TensorFlow presenta una clase de modelo que puede practicar para generar un modelo a partir de sus capas desarrolladas. Exige que solo defina las capas de entrada y salida, mapeando la estructura y el gráfico del modelo de la arquitectura de red.
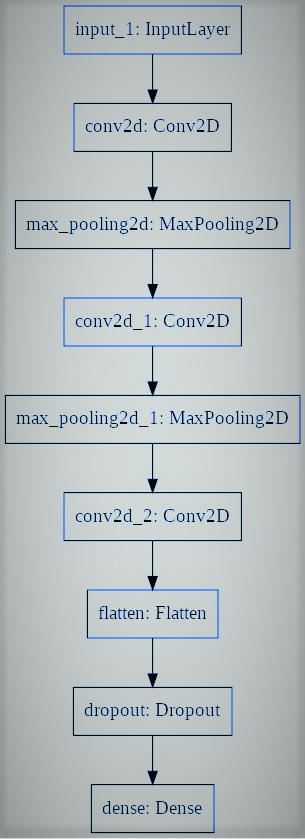
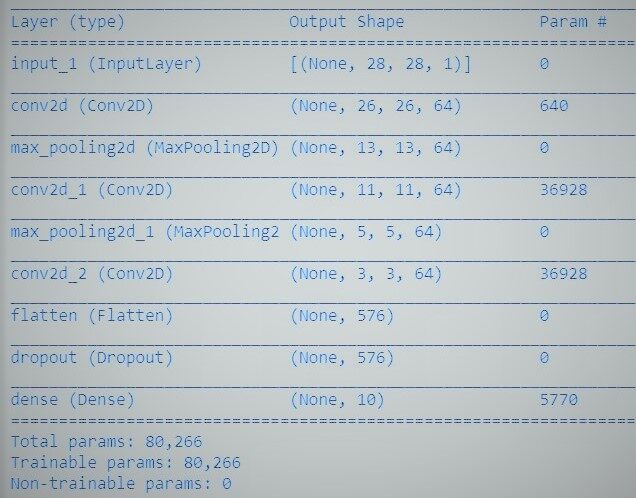
Por último, entrenamos al modelo.
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=['accuracy'])
model.fit(x_train,
y_train,
validation_data=(x_test, y_test),
epochs=20,
batch_size=batch_size)
# accuracy evaluation
score = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("nTest accuracy: %.1f%%" % (100.0 * score[1]))
Ahora hemos desarrollado con éxito una red neuronal convolucional para distinguir dígitos escritos a mano con la API funcional de Tensorflow. Hemos obtenido una precisión superior al 99% y podemos guardar el modelo y diseñar una aplicación web de clasificación de dígitos.
Referencias:
- https://www.tensorflow.org/guide/keras/functional
- https://machinelearningmastery.com/keras-functional-api-deep-learning/
Los medios que se muestran en este artículo sobre el reconocimiento del lenguaje de señas no son propiedad de DataPeaker y se utilizan a discreción del autor.





