Desbloqueo de un mundo nuevo con el algoritmo de regresión vectorial de soporte
Las máquinas de vectores de soporte (SVM) se utilizan popular y ampliamente para problemas de clasificación en el aprendizaje automático. A menudo me he basado en esto no solo en proyectos de aprendizaje automático, sino también cuando quiero un resultado rápido en un hackathon.
¿Pero SVM para análisis de regresión? ¡Ni siquiera había considerado la posibilidad por un tiempo! E incluso ahora, cuando menciono «Regresión vectorial de soporte» frente a los principiantes en aprendizaje automático, a menudo tengo una expresión de perplejidad. Entiendo: la mayoría de los cursos y expertos ni siquiera mencionan la regresión vectorial de soporte (SVR) como un algoritmo de aprendizaje automático.
Pero SVR tiene sus usos, como verá en este tutorial. Primero entenderemos rápidamente qué es SVM, antes de sumergirnos en el mundo de la regresión vectorial de soporte y cómo implementarlo en Python.
Nota: Puede obtener información sobre las máquinas de vectores de soporte y los problemas de regresión en formato de curso aquí (¡es gratis!):
Esto es lo que cubriremos en este tutorial de regresión de vectores de soporte:
- ¿Qué es una máquina de vectores de soporte (SVM)?
- Hiperparámetros del algoritmo de máquina de vectores de soporte
- Introducción a la regresión de vectores de soporte (SVR)
- Implementación de la regresión de vectores de soporte en Python
¿Qué es una máquina de vectores de soporte (SVM)?
Entonces, ¿qué es exactamente Support Vector Machine (SVM)? Comenzaremos entendiendo SVM en términos simples. Digamos que tenemos un diagrama de dos clases de etiquetas como se muestra en la siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas....:
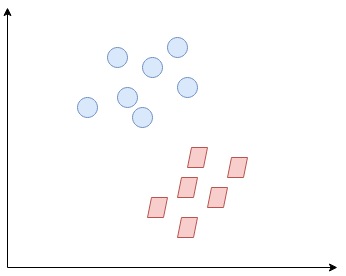
¿Puedes decidir cuál será la línea de separación? Es posible que se le haya ocurrido esto:
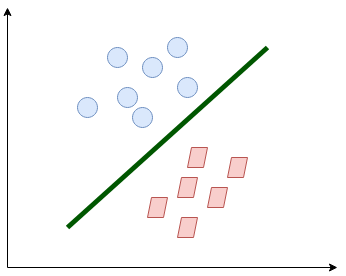
La línea separa bastante las clases. Esto es lo que esencialmente hace SVM: separación de clases simple. Ahora, ¿cuáles son los datos?
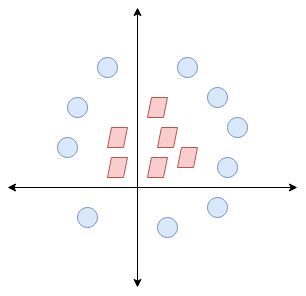
Aquí, no tenemos una línea simple que separe estas dos clases. Así que ampliaremos nuestra dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... e introduciremos una nueva dimensión a lo largo del eje z. Ahora podemos separar estas dos clases:
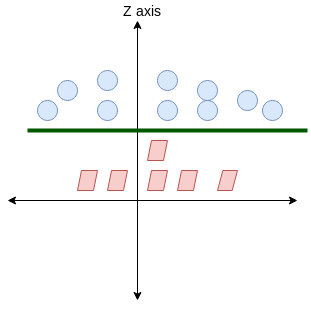
Cuando transformamos esta línea de nuevo al plano original, se asigna al límite circular como lo he mostrado aquí:
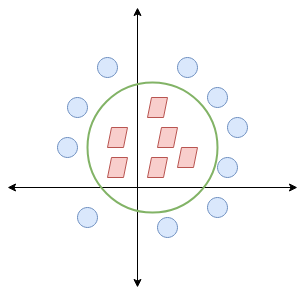
¡Esto es exactamente lo que hace SVM! Intenta encontrar una línea / hiperplano (en un espacio multidimensional) que separe estas dos clases. Luego clasifica el nuevo punto en función de si se encuentra en el lado positivo o negativo del hiperplano según las clases a predecir.
Hiperparámetros del algoritmo de máquina de vectores de soporte (SVM)
Hay algunos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... importantes de SVM que debe conocer antes de continuar:
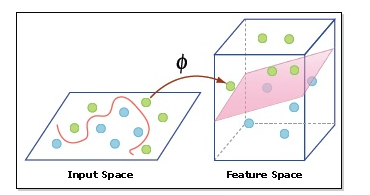
- Núcleo: Un kernel nos ayuda a encontrar un hiperplano en el espacio dimensional superior sin aumentar el costo computacional. Por lo general, el costo computacional aumentará si aumenta la dimensión de los datos. Este aumento de dimensión es necesario cuando no podemos encontrar un hiperplano de separación en una dimensión determinada y debemos movernos en una dimensión superior:
- Hiperplano: Esta es básicamente una línea de separación entre dos clases de datos en SVM. Pero en la regresión de vectores de soporte, esta es la línea que se utilizará para predecir la salida continua
- Límite de decisión: Un límite de decisión se puede considerar como una línea de demarcación (para simplificar) en un lado de la cual se encuentran los ejemplos positivos y en el otro lado se encuentran los ejemplos negativos. En esta misma línea, los ejemplos pueden clasificarse como positivos o negativos. Este mismo concepto de SVM se aplicará también en la regresión de vectores de soporte
Para comprender SVM desde cero, recomiendo este tutorial: Comprender el algoritmo de Support Vector Machine (SVM) a partir de ejemplos.
Introducción a la regresión de vectores de soporte (SVR)
La regresión vectorial de soporte (SVR) utiliza el mismo principio que SVM, pero para problemas de regresión. Dediquemos unos minutos a comprender la idea detrás de SVR.
La idea detrás de la regresión de vectores de soporte
El problema de la regresión es encontrar una función que se aproxime al mapeo de un dominio de entrada a números reales sobre la base de una muestra de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... Así que ahora profundicemos y entendamos cómo funciona realmente la RVS.
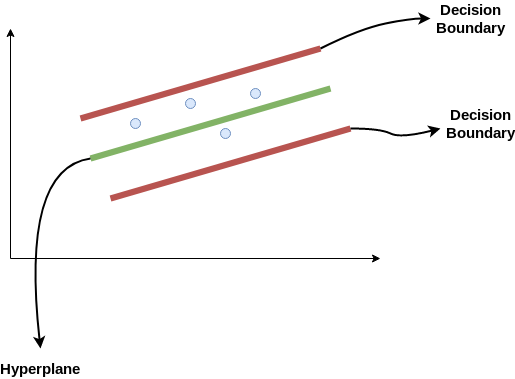
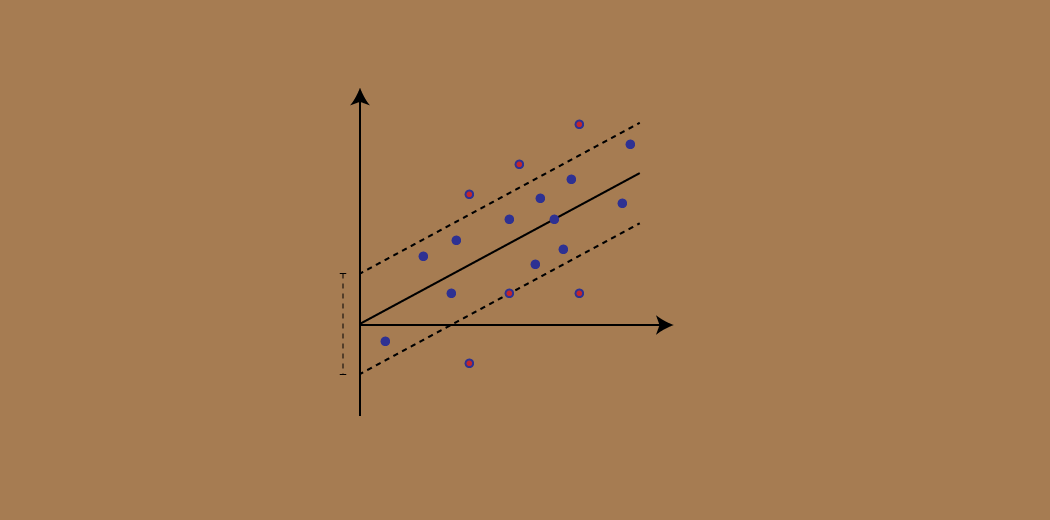
Considere estas dos líneas rojas como el límite de decisión y la línea verde como el hiperplano. Nuestro objetivo, cuando estamos avanzando con SVR, es básicamente considerar los puntos que están dentro de la línea límite de decisión. Nuestra mejor línea de ajuste es el hiperplano que tiene un número máximo de puntos.
Lo primero que entenderemos es cuál es el límite de decisión (¡la línea roja de peligro arriba!). Considere que estas líneas están a cualquier distancia, digamos «a», del hiperplano. Entonces, estas son las líneas que dibujamos a la distancia ‘+ a’ y ‘-a’ del hiperplano. Esta ‘a’ en el texto se conoce básicamente como épsilon.
Suponiendo que la ecuación del hiperplano es la siguiente:
Y = wx+b (equation of hyperplane)
Entonces las ecuaciones de límite de decisión se convierten en:
wx+b= +a wx+b= -a
Por lo tanto, cualquier hiperplano que satisfaga nuestra RVS debería satisfacer:
-a < Y- wx+b < +a
Nuestro principal objetivo aquí es decidir un límite de decisión a una distancia ‘a’ del hiperplano original, de modo que los puntos de datos más cercanos al hiperplano o los vectores de soporte estén dentro de esa línea límite.
Por lo tanto, vamos a tomar solo aquellos puntos que están dentro del límite de decisión y tienen la menor tasa de error, o están dentro del MargenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial... de Tolerancia. Esto nos da un modelo de mejor ajuste.
Implementación de regresión vectorial de soporte (SVR) en Python
¡Es hora de ponernos nuestros sombreros de codificación! En esta sección, entenderemos el uso de la regresión de vectores de soporte con la ayuda de un conjunto de datos. Aquí, tenemos que predecir el salario de un empleado dadas algunas variables independientes. ¡Un proyecto clásico de análisis de recursos humanos!
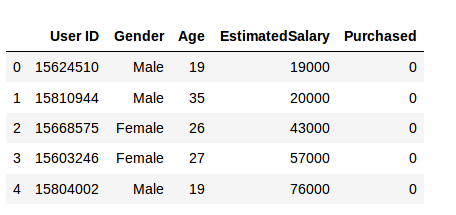
Paso 1: importar las bibliotecas
Paso 2: leer el conjunto de datos
Paso 3: Escalado de funciones
Un conjunto de datos del mundo real contiene características que varían en magnitudes, unidades y rango. Sugeriría realizar la normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... cuando la escala de una característica es irrelevante o engañosa.
Feature Scaling básicamente ayuda a normalizar los datos dentro de un rango particular. Normalmente, varios tipos de clases comunes contienen la función de escalado de características para que realicen la escala de características automáticamente. Sin embargo, la clase SVR no es un tipo de clase de uso común, por lo que deberíamos realizar el escalado de características con Python.
Paso 4: ajuste de SVR al conjunto de datos
El kernel es la característica más importante. Hay muchos tipos de núcleos: lineales, gaussianos, etc. Cada uno se utiliza según el conjunto de datos. Para obtener más información sobre esto, lea esto: Soporte Vector Machine (SVM) en Python y R
Paso 5. Predecir un nuevo resultado
Entonces, la predicción para y_pred (6, 5) será 170,370.
Paso 6. Visualización de los resultados de SVR (para una resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... más alta y una curva más suave)
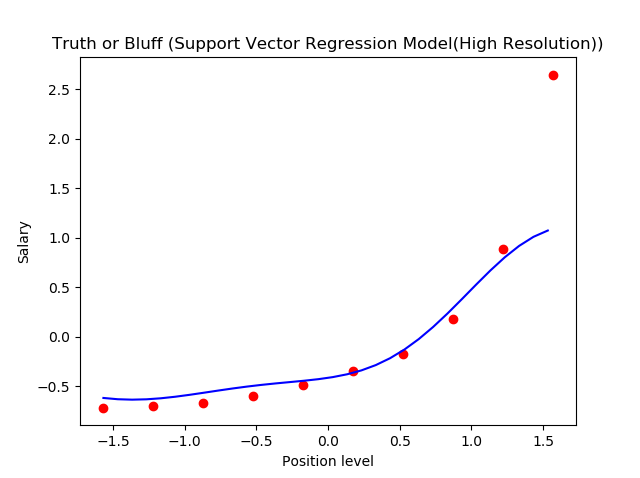
Esto es lo que obtenemos como salida: la línea de mejor ajuste que tiene un número máximo de puntos. ¡Bastante preciso!
Notas finales
Podemos pensar en la regresión de vectores de soporte como la contraparte de SVM para los problemas de regresión. SVR reconoce la presencia de no linealidad en los datos y proporciona un modelo de predicción competente.
Me encantaría escuchar sus pensamientos e ideas sobre el uso de SVR para el análisis de regresión. ¡Conéctese conmigo en la sección de comentarios a continuación e ideemos!





