Nota: este post se publicó originalmente en 13 de septiembre de 2015 y actualizado el 11 de septiembre de 2017
Visión general
- Comprender uno de los algoritmos de clasificación de aprendizaje automático más populares y simples, el algoritmo Naive Bayes
- Se basa en el teorema de Bayes para calcular probabilidades y probabilidades condicionales.
- Aprenda a poner en práctica el clasificador Naive Bayes en R y Python
Introducción
Aquí hay una situación en la que te has metido en tu Ciencia de los datos proyecto:
Está trabajando en un obstáculo de clasificación y ha generado su conjunto de hipótesis, creado características y discutido la relevancia de las variables. En una hora, las partes interesadas quieren ver el primer corte del modelo.
¿Qué vas a hacer? Tienes cientos de cientos de puntos de datos y bastantes variables en tu conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... En tal situación, si estuviera en tu lugar, habría usado ‘Bayes ingenuo‘, que puede ser extremadamente rápido en vinculación con otros algoritmos de clasificación. Funciona con el teorema de probabilidad de Bayes para predecir la clase de conjuntos de datos desconocidos.
En este post, explicaré los conceptos básicos de este algoritmo, para que la próxima vez que se encuentre con grandes conjuntos de datos, pueda poner este algoritmo en acción. Al mismo tiempo, si eres un novato en Python o R, no debe sentirse abrumado por la presencia de códigos disponibles en este post.
Si prefiere aprender el teorema de Naive Bayes desde los conceptos básicos hasta la implementación de manera estructurada, puede inscribirse en este curso sin costes:
¿Eres un principiante en Machine Learning? ¿Pretendes dominar los algoritmos de aprendizaje automático como Naive Bayes? Aquí hay un curso completo que cubre el aprendizaje automático y los algoritmos de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... en detalle:
Proyecto para aplicar Naive BayesPlanteamiento del problemaEl análisis de recursos humanos está revolucionando la forma en que operan los departamentos de recursos humanos, lo que lleva a una mayor eficiencia y mejores resultados en general. Los recursos humanos han estado usando la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico.... durante años. A pesar de esto, la recopilación, el procesamiento y el análisis de datos ha sido en gran medida manual y, dada la naturaleza de la dinámica de los recursos humanos y los KPILos KPI, o indicadores clave de rendimiento, son métricas utilizadas por las organizaciones para evaluar su éxito en alcanzar objetivos específicos. Estos indicadores permiten monitorear el progreso y tomar decisiones informadas. Existen diferentes tipos de KPI, que pueden variar según el sector y los objetivos estratégicos de la empresa. Su correcta implementación es esencial para mejorar la eficiencia y efectividad de las operaciones.... de recursos humanos, el enfoque ha estado restringiendo a los recursos humanos. Por eso, es sorprendente que los departamentos de recursos humanos se hayan dado cuenta de la utilidad del aprendizaje automático tan tarde en el juego. Esta es una posibilidad para probar el análisis predictivo para identificar a los trabajadores con más probabilidades de ser promovidos. |
Tabla de contenido
- ¿Qué es el algoritmo Naive Bayes?
- ¿Cómo funcionan los algoritmos Naive Bayes?
- ¿Cuáles son los pros y los contras de utilizar Naive Bayes?
- 4 Aplicaciones del algoritmo Naive Bayes
- Pasos para construir un modelo Naive Bayes básico en Python
- Consejos para impulsar la potencia del modelo Naive Bayes
¿Qué es el algoritmo Naive Bayes?
Es un técnica de clasificación basado en el teorema de Bayes con un supuesto de independencia entre predictores. En términos simples, un clasificador Naive Bayes asume que la presencia de una característica particular en una clase no está relacionada con la presencia de ninguna otra característica.
A modo de ejemplo, una fruta puede considerarse una manzana si es roja, redonda y tiene aproximadamente 3 pulgadas de diámetro. Inclusive si estas características dependen unas de otras o de la existencia de otras características, todas estas propiedades contribuyen de forma independiente a la probabilidad de que esta fruta sea una manzana y es por esto que se la conoce como ‘Naive’.
El modelo Naive Bayes es fácil de construir y concretamente útil para conjuntos de datos muy grandes. Junto con la simplicidad, se sabe que Naive Bayes supera inclusive a los métodos de clasificación altamente sofisticados.
El teorema de Bayes proporciona una forma de calcular la probabilidad posterior P (c | x) a partir de P (c), P (x) y P (x | c). Mira la próxima ecuación:
 Encima,
Encima,
- PAG(c | x) es la probabilidad posterior de clase (C, objetivo) dado vaticinador (X, atributos).
- PAG(C) es la probabilidad previa de clase.
- PAG(x | c) es la probabilidad que es la probabilidad de vaticinador dado clase.
- PAG(X) es la probabilidad previa de vaticinador.
¿Cómo funciona el algoritmo Naive Bayes?
Entendamos con un ejemplo. A continuación tengo un conjunto de datos de entrenamiento del clima y la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... objetivo respectivo ‘Jugar’ (que sugiere posibilidades de juego). Ahora, debemos categorizar si los jugadores jugarán o no según las condiciones climáticas. Sigamos los pasos a continuación para realizarlo.
Paso 1: convierta el conjunto de datos en una tabla de frecuencias
Paso 2: Cree una tabla de probabilidad encontrando las probabilidades como la probabilidad de Nublado = 0.29 y la probabilidad de jugar es 0.64.
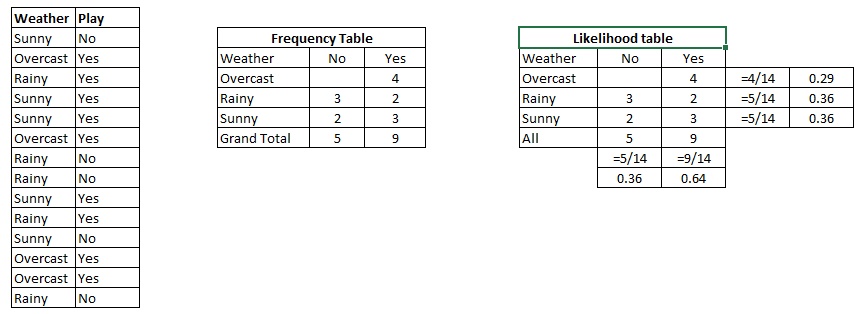
Paso 3: ahora, utiliza Ingenuo bayesiano ecuación para calcular la probabilidad posterior para cada clase. La clase con la probabilidad posterior más alta es el resultado de el pronóstico.
Problema: Los jugadores jugarán si el clima es soleado. ¿Esta afirmación es correcta?
Podemos resolverlo usando el método de probabilidad posterior discutido previamente.
P (Sí | Soleado) = P (Soleado | Sí) * P (Sí) / P (Soleado)
Aquí tenemos P (Soleado | Sí) = 3/9 = 0.33, P (Soleado) = 5/14 = 0.36, P (Sí) = 9/14 = 0.64
Ahora, P (Sí | Soleado) = 0.33 * 0.64 / 0.36 = 0.60, que tiene mayor probabilidad.
Naive Bayes utiliza un método equivalente para predecir la probabilidad de diferentes clases en función de varios atributos. Este algoritmo se utiliza principalmente en la clasificación de texto y con problemas que disponen múltiples clases.
¿Cuáles son los pros y los contras de Naive Bayes?
Pros:
- Es fácil y rápido predecir la clase de conjunto de datos de prueba. Además funciona bien en el pronóstico de clases múltiples.
- Cuando se cumple el supuesto de independencia, un clasificador Naive Bayes funciona mejor en comparación con otros modelos como la regresión logística y necesita menos datos de entrenamiento.
- Funciona bien en el caso de variables de entrada categóricas en comparación con variables numéricas. Para la variable numérica, se asume una distribución normal (curva de campana, que es una suposición sólida).
Contras:
- Si la variable categórica dispone de una categoría (en el conjunto de datos de prueba), que no se observó en el conjunto de datos de entrenamiento, entonces el modelo asignará una probabilidad 0 (cero) y no podrá hacer una predicción. Esto a menudo se conoce como «Frecuencia cero». Para arreglar esto, podemos usar la técnica de suavizado. Una de las técnicas de suavizado más simples se llama estimación de Laplace.
- Por otra parte, Bayes ingenuo además se conoce como un mal estimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos...., por lo que las salidas de probabilidad de predecir_proba no deben tomarse demasiado en serio.
- Otra limitación de Bayes ingenuo es el supuesto de predictores independientes. En la vida real, es casi imposible que obtengamos un conjunto de predictores que sean totalmente independientes.
4 Aplicaciones de los algoritmos ingenuos de Bayes
- Predicción en tiempo real: Naive Bayes es un clasificador de aprendizaje ávido y seguro que es rápido. Por tanto, podría utilizarse para realizar predicciones en tiempo real.
- Predicción de clases múltiples: Este algoritmo además es bien conocido por su función de predicción de clases múltiples. Aquí podemos predecir la probabilidad de múltiples clases de variable objetivo.
- Clasificación de texto / filtrado de spam / análisis de opiniones: Los clasificadores Naive Bayes que se usan principalmente en la clasificación de texto (debido a un mejor resultado en problemas de clases múltiples y la regla de independencia) disponen una mayor tasa de éxito en comparación con otros algoritmos. Como consecuencia, se utiliza ampliamente en el filtrado de correo no deseado (identifica el email no deseado) y el análisis de sentimientos (en el análisis de redes sociales, para identificar los sentimientos positivos y negativos de los clientes).
- Sistema de recomendación: Clasificador Naive Bayes y Filtración colaborativa juntos construyen un sistema de recomendación que utiliza técnicas de aprendizaje automático y minería de datos para filtrar información invisible y predecir si un usuario desea un recurso determinado o no
¿Cómo construir un modelo básico usando Naive Bayes en Python y R?
Nuevamente, scikit learn (biblioteca de Python) ayudará aquí a construir un modelo Naive Bayes en Python. Hay tres tipos de modelo Naive Bayes en la biblioteca scikit-learn:
-
Gaussiano: Se utiliza en la clasificación y asume que las características siguen una distribución normal.
-
Multinomial: Se utiliza para recuentos discretos. A modo de ejemplo, digamos que tenemos un obstáculo de clasificación de texto. Aquí podemos considerar los ensayos de Bernoulli, que es un paso más allá y en lugar de «palabra que aparece en el documento», tenemos «contar con qué frecuencia aparece la palabra en el documento», puede pensar en ello como «número de veces que se observa el resultado número x_i durante los n ensayos ”.
-
Bernoulli: El modelo binomial es útil si sus vectores de características son binarios (dicho de otra forma, ceros y unos). Una aplicación sería la clasificación de texto con el modelo de ‘bolsa de palabras’ donde los 1 y 0 son «la palabra aparece en el documento» y «la palabra no aparece en el documento», respectivamente.
Código Python:
¡Pruebe el siguiente código en la ventana de codificación y verifique sus resultados sobre la marcha!
Código R:
require(e1071) #Holds the Naive Bayes Classifier Train <- read.csv(file.choose()) Test <- read.csv(file.choose()) #Make sure the target variable is of a two-class classification problem only levels(Train$Item_Fat_Content) model <- naiveBayes(Item_Fat_Content~., data = Train) class(model) pred <- predict(model,Test) table(pred)
Previamente, analizamos el modelo básico de Naive Bayes, puede mejorar la potencia de este modelo básico ajustando los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... y manejando las suposiciones de manera inteligente. Veamos los métodos para impulsar el rendimiento del modelo Naive Bayes. Te sugiero que pases por este documento para obtener más detalles sobre la clasificación de texto usando Naive Bayes.
Consejos para impulsar la potencia del modelo Naive Bayes
A continuación, se ofrecen algunos consejos para impulsar la potencia de Bayes ingenuo Modelo:
- Si las entidades continuas no disponen distribución normal, deberíamos utilizar transformación o diferentes métodos para convertirlas en distribución normal.
- Si el conjunto de datos de prueba tiene un obstáculo de frecuencia cero, aplique técnicas de suavizado “Corrección de Laplace” para predecir la clase de conjunto de datos de prueba.
- Elimine las características correlacionadas, puesto que las características altamente correlacionadas se votan dos veces en el modelo y pueden dar lugar a una relevancia exagerada.
- Los clasificadores Naive Bayes disponen opciones limitadas para el ajuste de parámetros como alpha = 1 para suavizar, fit_prior =[True|False] para aprender las probabilidades previas de la clase o no y algunas otras opciones (ver detalles aquí). Recomendaría centrarse en el procesamiento previo de datos y la selección de funciones.
- Podrías pensar en aplicar algunos técnica de combinación de clasificador como conjunto, ensacado y refuerzo, pero estos métodos no ayudarían. En realidad, «ensamblar, impulsar, embolsar» no ayudará, puesto que su objetivo es reducir la variación. Naive Bayes no tiene ninguna variación que minimizar.
Notas finales
En este post, analizamos uno de los algoritmos de aprendizaje automático supervisados »Naive Bayes» que se utiliza principalmente para la clasificación. Felicidades, si ha entendido bien este post, ya ha dado el primer paso para dominar este algoritmo. A partir de aquí, todo lo que necesitas es practicar.
Al mismo tiempo, le sugiero que se centre más en el preprocesamiento de datos y la selección de características antes de aplicar el algoritmo Naive Bayes.0 En una publicación futura, hablaré sobre la clasificación de textos y documentos usando bayes ingenuos con más detalle.
¿Le ha resultado útil este post? Comparta sus opiniones / pensamientos en la sección de comentarios a continuación.
Puede usar el siguiente recurso sin costes para aprender- Naive Bayes-





