Una de las preguntas más comunes, que se hace en varios foros de ciencia de datos es:
¿Cuál es la diferencia entre el aprendizaje automático y el modelado estadístico?
He estado investigando durante los últimos 2 años. De forma general, no me lleva más de un día obtener una respuesta clara al tema que estoy investigando. A pesar de esto, este fue definitivamente uno de los frutos secos más difíciles de romper. Cuando me encontré con esta pregunta al principio, casi no encontré una respuesta clara que pueda determinar en qué se diferencia el aprendizaje automático del modelado estadístico. Dada la similitud en términos del objetivo que ambos intentan solucionar, la única diferencia radica en el volumen de datos involucrados y la participación humana para construir un modelo. Aquí hay un diagrama de Venn interesante sobre la cobertura del aprendizaje automático y el modelado estadístico en el universo de la ciencia de datos (Referencia: Instituto SAS)
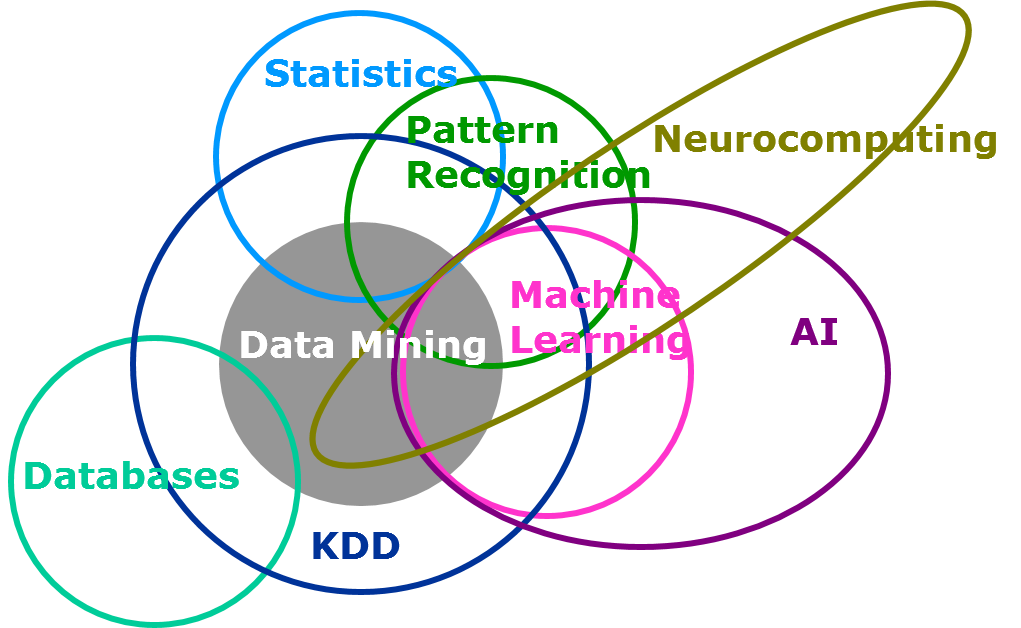
En este post, intentaré resaltar la diferencia entre los dos lo mejor que pueda. Animo a las personas más experimentadas de esta industria a que agreguen a este post para resaltar la diferencia.
Antes de comenzar, entendamos el objetivo detrás de lo que estamos tratando de solucionar para utilizar cualquiera de estas herramientas. El objetivo común detrás del uso de cualquiera de las herramientas es Aprendiendo de los datos. Ambos enfoques disponen como objetivo aprender sobre los fenómenos subyacentes a través de el uso de datos generados en el procedimiento.
Ahora que es claro que el objetivo detrás de cualquiera de los enfoques es el mismo, repasemos su definición y diferencias.
Antes de continuar: conceptos básicos del aprendizaje automático para principiantes
Definición:
Comencemos con definiciones simples:
El aprendizaje automático es …
un algoritmo que puede aprender de los datos sin depender de la programación basada en reglas.
El modelado estadístico es …
formalización de relaciones entre variables en forma de ecuaciones matemáticas.
Para personas como yo, que disfrutan entendiendo conceptos a partir de aplicaciones prácticas, estas definiciones no ayudan mucho. Entonces, veamos un caso de negocios aquí.
Un caso de negocio
Veamos ahora un interesante ejemplo hecho público por McKinsey diferenciando los dos algoritmos:
Caso : Comprender el nivel de riesgo de la rotación de clientes durante un período de tiempo para una compañía de telecomunicaciones.
Datos disponibles : Dos conductores: A y B
¡Lo que McKinsey muestra a continuación es una absoluta delicia! Simplemente observe el gráfico a continuación para comprender la diferencia entre un modelo estadístico y un algoritmo de aprendizaje automático.
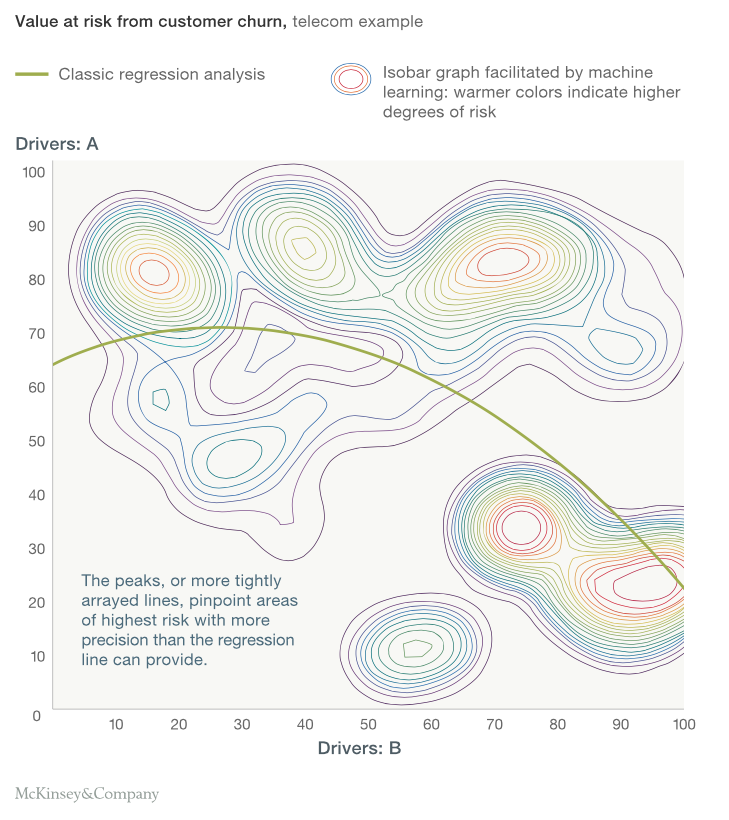
¿Qué observaste en el gráfico anterior? El modelo estadístico se trata de obtener una formulación simple de una frontera en un obstáculo de modelo de clasificación. Aquí vemos un límite no lineal que, en cierta medida, separa a las personas con riesgo de las personas sin riesgo. Pero cuando vemos los contornos generados por el algoritmo de Machine Learning, somos testigos de que el modelado estadístico no es comparable para el problema en cuestión con el algoritmo de Machine Learning. Los contornos del aprendizaje automático parecen capturar todos los patrones más allá de los límites de linealidad o inclusive la continuidad de los límites. Esto es lo que el aprendizaje automático puede hacer por usted.
Si esto no es suficiente inspiración, el algoritmo de aprendizaje automático se utiliza en los motores de recomendación de YouTube / Google, etc., que pueden generar billones de observaciones en un segundo para llegar a una recomendación casi perfecta. Inclusive con una computadora portátil de 16 GB de RAM, trabajo a diario en conjuntos de datos de millones de filas con cientos de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... y construyo un modelo completo en no más de 30 minutos. Un modelo estadístico, por otra parte, necesita una supercomputadora para ejecutar un millón de observaciones con mil parámetros.

Diferencias entre el aprendizaje automático y el modelado estadístico:
Dado el sabor de la diferencia en la producción de estos dos enfoques, comprendamos la diferencia en los dos paradigmas, aún cuando ambos hacen un trabajo casi equivalente:
- Escuelas de las que provienen
- ¿Cuándo surgieron?
- Supuestos en los que trabajan
- Tipo de datos que tratan
- Nomenclaturas de operaciones y objetos
- Técnicas utilizadas
- Poder predictivo y esfuerzos humanos involucrados para poner en práctica
Todas las diferencias mencionadas previamente separan a los dos hasta cierto punto, pero no existe un límite estricto entre el aprendizaje automático y el modelado estadístico.
Pertenecen a diferentes escuelas
El aprendizaje automático es …
un subcampo de la informática y la inteligencia artificial que se encarga de la construcción de sistemas que pueden aprender de los datos, en lugar de instrucciones programadas explícitamente.
El modelado estadístico es …
un subcampo de las matemáticas que se encarga de hallar relaciones entre variables para predecir un resultado
Surgieron en diferentes épocas
El modelado estadístico ha existido durante siglos. A pesar de esto, el aprendizaje automático es un desarrollo muy reciente. Surgió en la década de 1990 cuando los constantes avances en la digitalización y la potencia informática barata permitieron a los científicos de datos dejar de construir modelos terminados y, en cambio, entrenar a las computadoras para que lo hicieran. El volumen inmanejable y la complejidad de los macrodatos en los que está nadando el mundo han aumentado el potencial del aprendizaje automático y su necesidad.
Alcance de los supuestos involucrados
El modelado estadístico funciona con una serie de supuestos. A modo de ejemplo, una regresión lineal asume:
- Vinculación lineal entre variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... independiente y dependiente
- Homocedasticidad
- Media de error en cero para cada valor dependiente
- Independencia de observaciones
- El error debe distribuirse regularmente para cada valor de la variable dependiente.
De manera equivalente, las regresiones logísticas vienen con su propio conjunto de supuestos. Inclusive un modelo no lineal tiene que cumplir con un límite de segregación continuo. Los algoritmos de aprendizaje automático asumen algunas de estas cosas, pero en general se salvan de la mayoría de estas suposiciones. La mayor ventaja de usar un algoritmo de aprendizaje automático es que es factible que no haya continuidad de límite como se muestra en el estudio de caso anterior. Al mismo tiempo, no necesitamos especificar la distribución de la variable dependiente o independiente en un algoritmo de aprendizaje automático.
Tipos de datos con los que tratan
Los algoritmos de aprendizaje automático son herramientas de amplio rango. Las herramientas de aprendizaje en línea predicen datos sobre la marcha. Estas herramientas son capaces de aprender de billones de observaciones una por una. Hacen predicciones y aprenden simultáneamente. Otros algoritmos como Random Forest y Gradient Boosting además son excepcionalmente rápidos con big data. El aprendizaje automático funciona muy bien con amplia (gran cantidad de atributos) y profunda (gran cantidad de observaciones). A pesar de esto, los modelos estadísticos se aplican de forma general para datos más pequeños con menos atributos o terminan sobre ajustados.
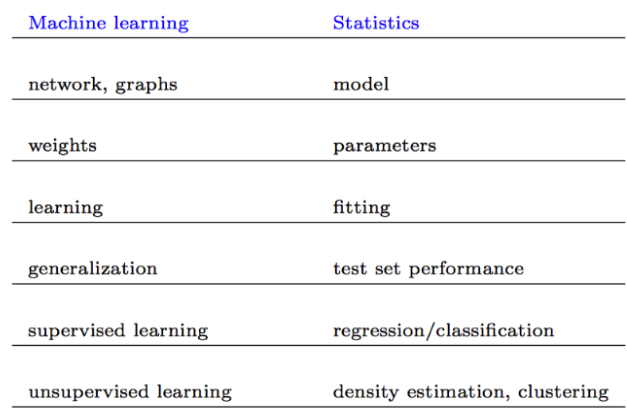
Convenio de denominación
Aquí hay nombres que se refieren a casi las mismas cosas:
Formulación
Inclusive cuando el objetivo final tanto para el aprendizaje automático como para el modelado estadístico es el mismo, la formulación de dos es significativamente distinto.
En un modelo estadístico, simplemente tratamos de estimar la función f en
Dependent Variable ( Y ) = f(Independent Variable) + error function
El aprendizaje automático elimina la función determinista «f» de la ecuación. Simplemente se convierte en
Output(Y) ----- > Input (X)
Intentará hallar bolsas de X en n dimensiones (donde n es el número de atributos), donde la ocurrencia de Y es significativamente distinto.
Poder predictivo y esfuerzo humano
La naturaleza no asume nada antes de obligar a que ocurra un evento.
Entonces, las suposiciones menores en un modelo predictivo, mayor será el poder predictivo. El aprendizaje automático, como su nombre indica, necesita un esfuerzo humano mínimo. El aprendizaje automático funciona en iteraciones en las que la computadora intenta descubrir patrones ocultos en los datos. Debido a que la máquina hace este trabajo con datos completos y es independiente de todos los supuestos, el poder predictivo es de forma general muy fuerte para estos modelos. El modelo estadístico es intensivo en matemáticas y se basa en la estimación de coeficientes. Necesita que el modelador comprenda la vinculación entre las variables antes de introducirlas.
Notas finales
A pesar de esto, puede parecer que el aprendizaje automático y el modelado estadístico son dos ramas diferentes del modelado predictivo, son casi lo mismo. La diferencia entre estos dos se ha reducido significativamente durante la última década. Ambas ramas han aprendido mucho la una de la otra y se acercarán más en el futuro. Espero haberlos motivado lo suficiente para obtener habilidades en cada uno de estos dos dominios y posteriormente comparar cómo se complementan entre sí.
Si está interesado en obtener algoritmos de aprendizaje automático, tenemos lo que necesita. Estamos en procedimiento de construir una ruta de aprendizaje para el aprendizaje automático que se publicará próximamente..
Háganos saber cuál cree que es la diferencia entre el aprendizaje automático y el modelado estadístico. ¿Tiene algún estudio de caso para señalar las diferencias entre los dos?





