Introducción
«¿Cuál es la diferencia entre el aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... y el aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la...?»
Esta es una pregunta demasiado común entre los principiantes y los recién llegados al aprendizaje automático. La respuesta a esto se encuentra en el núcleo de la comprensión de la esencia de los algoritmos de aprendizaje automático. Sin una distinción clara entre este aprendizaje supervisado y el aprendizaje no supervisado, su viaje simplemente no puede progresar.
En realidad, esta es una de las primeras cosas que debe aprender cuando se embarca en su viaje de aprendizaje automático. No podemos simplemente saltar a la fase de construcción del modelo si no entendemos dónde se encuentran los algoritmos como la regresión lineal, la regresión logística, la agrupación, las redes neuronales, etc.
Si no sabemos cuál es el objetivo del algoritmo de aprendizaje automático, fracasaremos en nuestro esfuerzo por construir un modelo preciso. Aquí es donde entra la idea de aprendizaje supervisado y aprendizaje no supervisado.
En este artículo, discutiré estos dos conceptos utilizando ejemplos y también responderé a la gran pregunta: ¿cómo decidir cuándo usar el aprendizaje supervisado o el aprendizaje no supervisado?
Si prefiere aprender en forma de video, el siguiente video explica 10 algoritmos de aprendizaje automático de una manera muy fácil de entender:
He mencionado algunos recursos excelentes a continuación que son ideales para consultar como principiante en el aprendizaje automático:
Comencemos por echar un vistazo al aprendizaje supervisado.
¿Qué es el aprendizaje supervisado?
En el aprendizaje supervisado, la computadora se enseña con el ejemplo. Aprende de los datos pasados y aplica el aprendizaje a los datos actuales para predecir eventos futuros. En este caso, tanto los datos de entrada como los de salida deseados ayudan a predecir eventos futuros.
Para obtener predicciones precisas, los datos de entrada se etiquetan o etiquetan como la respuesta correcta.

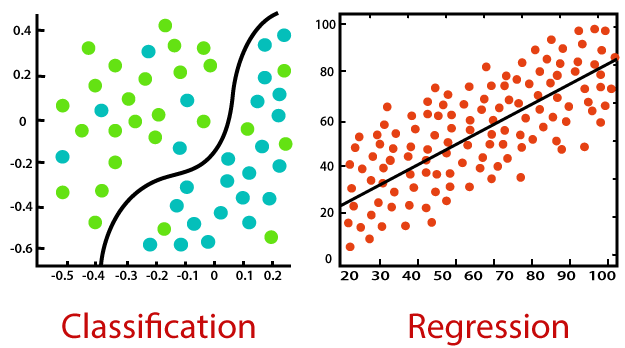
Categorización supervisada del aprendizaje automático
Es importante recordar que todos los algoritmos de aprendizaje supervisado son esencialmente algoritmos complejos, categorizados como modelos de clasificación o regresión.
1) Modelos de clasificación – Los modelos de clasificación se utilizan para problemas en los que la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de salida se puede categorizar, como «Sí» o «No», o «Pasa» o «No pasa». Los modelos de clasificación se utilizan para predecir la categoría de los datos. Los ejemplos de la vida real incluyen la detección de spam, el análisis de opiniones, la predicción de exámenes con tarjetas de puntuación, etc.
2) Modelos de regresión – Los modelos de regresión se utilizan para problemas donde la variable de salida es un valor real, como un número único, dólares, salario, peso o presión, por ejemplo. Se utiliza con mayor frecuencia para predecir valores numéricos basados en observaciones de datos anteriores. Algunos de los algoritmos de regresión más familiares incluyen regresión lineal, regresión logística, regresión polinomial y regresión de crestas.
Existen algunas aplicaciones muy prácticas de los algoritmos de aprendizaje supervisado en la vida real, que incluyen:
- Categorización de texto
- Detección de rostro
- Reconocimiento de firmas
- Descubrimiento de clientes
- Detección de spam
- Predicción del tiempo
- Predecir los precios de la vivienda en función del precio de mercado vigente
- Predicciones de precios de acciones, entre otros
¿Qué es el aprendizaje no supervisado?
El aprendizaje no supervisado, por otro lado, es el método que entrena a las máquinas para usar datos que no están clasificados ni etiquetados. Significa que no se pueden proporcionar datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y la máquina está hecha para aprender por sí misma. La máquina debe poder clasificar los datos sin ninguna información previa sobre los datos.
La idea es exponer las máquinas a grandes volúmenes de datos variables y permitirles aprender de esos datos para proporcionar información que antes se desconocía e identificar patrones ocultos. Como tal, no hay resultados necesariamente definidos de algoritmos de aprendizaje no supervisados. Más bien, determina qué es diferente o interesante del conjunto de datos dado.
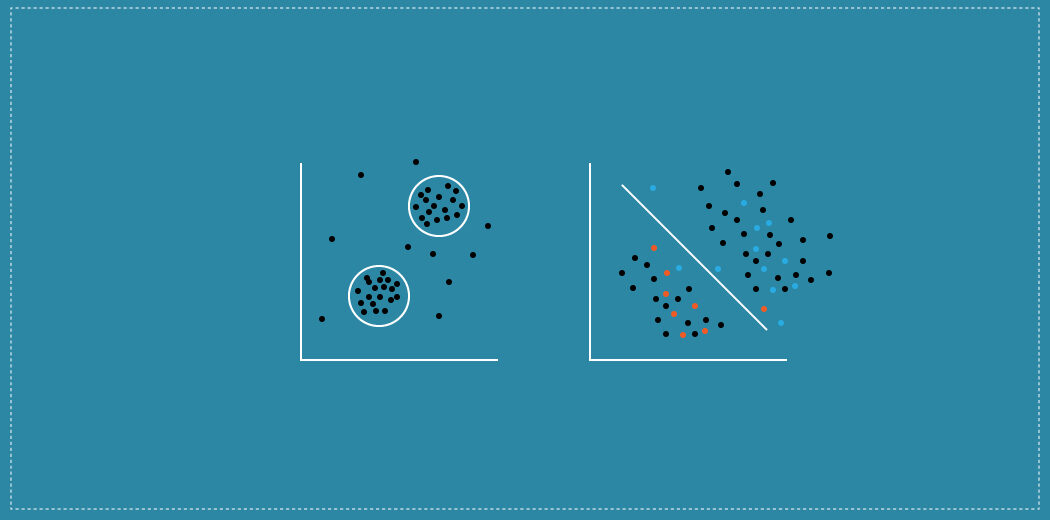
La máquina debe programarse para que aprenda por sí misma. La computadora necesita comprender y proporcionar información a partir de datos estructurados y no estructurados. Aquí hay una ilustración precisa del aprendizaje no supervisado:

Categorización de aprendizaje automático sin supervisión
1) Agrupación es uno de los métodos de aprendizaje no supervisado más comunes. El método de agrupación implica organizar los datos sin etiquetar en grupos similares llamados agrupaciones. Por lo tanto, un grupo es una colección de elementos de datos similares. El objetivo principal aquí es encontrar similitudes en los puntos de datos y agrupar puntos de datos similares en un grupo.
2) Detección de anomalías es el método para identificar elementos raros, eventos u observaciones que difieren significativamente de la mayoría de los datos. Por lo general, buscamos anomalías o valores atípicos en los datos porque son sospechosos. La detección de anomalías se utiliza a menudo en la detección de fraudes bancarios y errores médicos.
Aplicaciones de algoritmos de aprendizaje no supervisados
Algunas aplicaciones prácticas de los algoritmos de aprendizaje no supervisados incluyen:
- Detección de fraudes
- Detección de malware
- Identificación de errores humanos durante la entrada de datos
- Realización de análisis precisos de la canasta, etc.
¿Cuándo debería elegir el aprendizaje supervisado frente al aprendizaje no supervisado?
En la fabricación, una gran cantidad de factores afectan qué enfoque de aprendizaje automático es mejor para una tarea determinada. Y, dado que cada problema de aprendizaje automático es diferente, decidir qué técnica utilizar es un proceso complejo.
En general, una buena estrategia para perfeccionar el enfoque de aprendizaje automático correcto es:
- Evalúe los datos. ¿Está etiquetado / sin etiquetar? ¿Existe conocimiento experto disponible para respaldar el etiquetado adicional? Esto ayudará a determinar si se debe utilizar un enfoque de aprendizaje supervisado, no supervisado, semi-supervisado o reforzado.
- Define el objetivo. ¿El problema es recurrente, definido? ¿O se esperará que el algoritmo prediga nuevos problemas?
- Revise los algoritmos disponibles que puede adaptarse al problema con respecto a la dimensionalidad (número de características, atributos o características). Los algoritmos candidatos deben adaptarse al volumen general de datos y su estructura.
- Estudiar aplicaciones exitosas del tipo de algoritmo en problemas similares
Notas finales
El aprendizaje supervisado y el aprendizaje no supervisado son conceptos clave en el campo del aprendizaje automático. Una comprensión adecuada de los conceptos básicos es muy importante antes de saltar al grupo de diferentes algoritmos de aprendizaje automático.
Como siguiente paso, siga adelante y consulte el siguiente artículo que cubre los algoritmos de aprendizaje automático populares y principales:





