Una analogía simple para explicar el árbol de decisión frente al bosque aleatorio
Comencemos con un experimento mental que ilustrará la diferencia entre un árbol de decisiones y un modelo de bosque aleatorio.
Suponga que un banco tiene que aprobar un pequeño monto de préstamo para un cliente y el banco necesita tomar una decisión rápidamente. El banco verifica el historial crediticio de la persona y su situación financiera y descubre que aún no ha reembolsado el préstamo anterior. Por tanto, el banco rechaza la solicitud.
Pero aquí está el problema: el monto del préstamo era muy pequeño para las inmensas arcas del banco y podrían haberlo aprobado fácilmente en una medida de muy bajo riesgo. Por lo tanto, el banco perdió la oportunidad de ganar algo de dinero.
Ahora, otra solicitud de préstamo llegará dentro de unos días, pero esta vez el banco presenta una estrategia diferente: múltiples procesos de toma de decisiones. A veces, primero verifica el historial crediticio y, a veces, primero verifica la condición financiera del cliente y el monto del préstamo. Luego, el banco combina los resultados de estos múltiples procesos de toma de decisiones y decide otorgar el préstamo al cliente.
Incluso si este proceso tomó más tiempo que el anterior, el banco se benefició con este método. Este es un ejemplo clásico en el que la toma de decisiones colectiva superó a un solo proceso de toma de decisiones. Ahora, aquí está mi pregunta para ti: ¿Sabes qué representan estos dos procesos?

¡Estos son árboles de decisión y un bosque aleatorio! Exploraremos esta idea en detalle aquí, profundizaremos en las principales diferencias entre estos dos métodos y responderemos la pregunta clave: ¿con qué algoritmo de aprendizaje automático debería utilizar?
Tabla de contenido
- Breve introducción a los árboles de decisión
- Una descripción general de los bosques aleatorios
- Choque de bosque aleatorio y árbol de decisiones (¡en código!)
- ¿Por qué Random Forest superó a un árbol de decisiones?
- Árbol de decisión frente a bosque aleatorio: ¿cuándo debe elegir qué algoritmo?
Breve introducción a los árboles de decisión
Un árbol de decisiones es un algoritmo de aprendizaje automático supervisado que se puede utilizar para problemas de clasificación y regresión. Un árbol de decisiones es simplemente una serie de decisiones secuenciales que se toman para alcanzar un resultado específico. Aquí hay una ilustración de un árbol de decisiones en acción (usando nuestro ejemplo anterior):
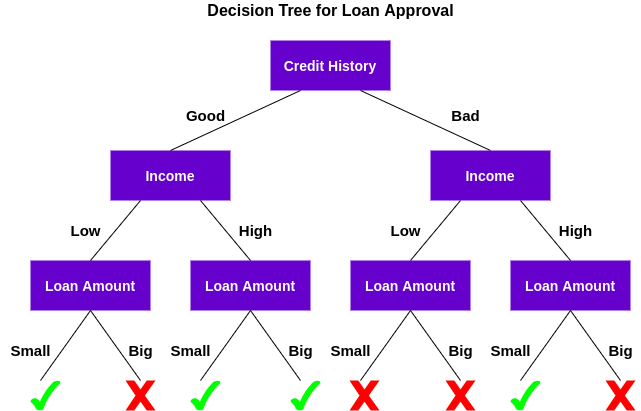
Entendamos cómo funciona este árbol.
Primero, verifica si el cliente tiene un buen historial crediticio. En base a eso, clasifica al cliente en dos grupos, es decir, clientes con buen historial crediticio y clientes con historial crediticio malo. Luego, verifica los ingresos del cliente y nuevamente lo clasifica en dos grupos. Finalmente, verifica el monto del préstamo solicitado por el cliente. Según los resultados de la verificación de estas tres características, el árbol de decisiones decide si el préstamo del cliente debe aprobarse o no.
Las características / atributos y las condiciones pueden cambiar según los datos y la complejidad del problema, pero la idea general sigue siendo la misma. Entonces, un árbol de decisiones toma una serie de decisiones basadas en un conjunto de características / atributos presentes en los datos, que en este caso fueron el historial crediticio, los ingresos y el monto del préstamo.
Ahora, es posible que se esté preguntando:
¿Por qué el árbol de decisiones verificó primero el puntaje crediticio y no los ingresos?
Esto se conoce como importancia de la característica y la secuencia de atributos a verificar se decide sobre la base de criterios como ÍndiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de impureza de Gini o Ganancia de información. La explicación de estos conceptos está fuera del alcance de nuestro artículo aquí, pero puede consultar cualquiera de los recursos a continuación para aprender todo sobre los árboles de decisión:
Nota: La idea detrás de este artículo es comparar árboles de decisión y bosques aleatorios. Por lo tanto, no entraré en los detalles de los conceptos básicos, pero proporcionaré los enlaces relevantes en caso de que desee explorar más.
Una descripción general de Random Forest
El algoritmo del árbol de decisiones es bastante fácil de entender e interpretar. Pero a menudo, un solo árbol no es suficiente para producir resultados efectivos. Aquí es donde entra en escena el algoritmo Random Forest.

Random Forest es un algoritmo de aprendizaje automático basado en árboles que aprovecha el poder de múltiples árboles de decisión para tomar decisiones. Como sugiere el nombre, ¡es un «bosque» de árboles!
Pero, ¿por qué lo llamamos bosque «aleatorio»? Eso es porque es un bosque de árboles de decisión creados aleatoriamente. Cada nodo del árbol de decisiones trabaja en un subconjunto aleatorio de características para calcular la salida. El bosque aleatorio luego combina la salida de árboles de decisión individuales para generar la salida final.
En palabras simples:
El algoritmo de bosque aleatorio combina la salida de varios árboles de decisión (creados aleatoriamente) para generar la salida final.
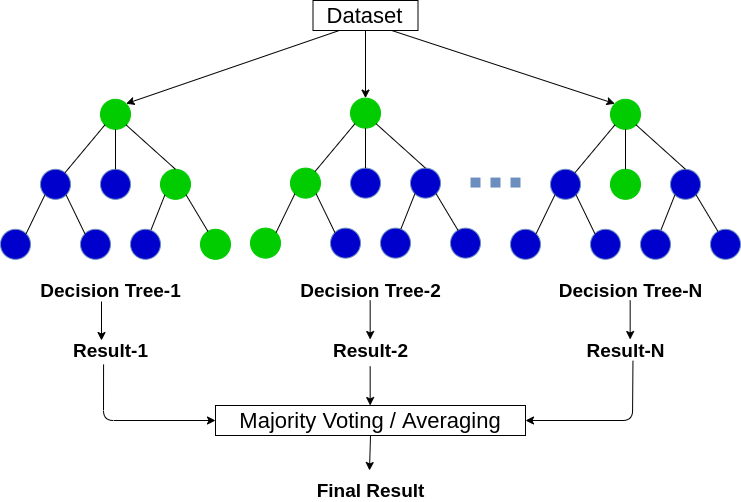
Este proceso de combinar la salida de múltiples modelos individuales (también conocido como estudiantes débiles) se llama Aprendizaje conjunto. Si desea leer más sobre cómo funcionan el bosque aleatorio y otros algoritmos de aprendizaje por conjuntos, consulte los siguientes artículos:
Ahora la pregunta es, ¿cómo podemos decidir qué algoritmo elegir entre un árbol de decisión y un bosque aleatorio? ¡Veámoslos a ambos en acción antes de sacar conclusiones!
Choque de bosque aleatorio y árbol de decisiones (¡en código!)
En esta sección, usaremos Python para resolver un problema de clasificación binaria utilizando tanto un árbol de decisiones como un bosque aleatorio. Luego compararemos sus resultados y veremos cuál se adapta mejor a nuestro problema.
Estaremos trabajando en el Conjunto de datos de predicción de préstamos de DataPeaker’s Plataforma DataHack. Este es un problema de clasificación binaria en el que tenemos que determinar si una persona debe recibir un préstamo o no en función de un determinado conjunto de características.
Nota: puede ir a la DataHack plataforma y competir con otras personas en varias competiciones de aprendizaje automático en línea y tener la oportunidad de ganar premios emocionantes.
¿Listo para codificar?
Paso 1: cargar las bibliotecas y el conjunto de datos
Comencemos por importar las bibliotecas de Python requeridas y nuestro conjunto de datos:

El conjunto de datos consta de 614 filas y 13 características, incluido el historial crediticio, el estado civil, el monto del préstamo y el género. Aquí, la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de destino es Loan_Status, que indica si una persona debe recibir un préstamo o no.
Paso 2: preprocesamiento de datos
Ahora viene la parte más crucial de cualquier proyecto de ciencia de datos: Data preprocesamiento y feingeniería natural. En esta sección, trataré las variables categóricas en los datos y también imputaré los valores faltantes.
Imputaré los valores perdidos en las variables categóricas con la moda, y para las variables continuas, con la media (para las respectivas columnas). Además, etiquetaremos codificando los valores categóricos en los datos. Puede leer este artículo para obtener más información sobre Codificación de etiquetas.

Paso 3: creación de conjuntos de pruebas y trenes
Ahora, dividamos el conjunto de datos en un 80:20 relación para entrenamiento y prueba, respectivamente:
Echemos un vistazo a la forma del tren creado y los conjuntos de prueba:

¡Excelente! ¡Ahora estamos listos para la siguiente etapa en la que crearemos el árbol de decisiones y los modelos de bosque aleatorios!
Paso 4: construcción y evaluación del modelo
Dado que tenemos los conjuntos de capacitación y prueba, es hora de entrenar nuestros modelos y clasificar las solicitudes de préstamo. Primero, entrenaremos un árbol de decisiones en este conjunto de datos:
A continuación, evaluaremos este modelo utilizando F1-Score. F1-Score es la media armónica de precisión y recuperación dada por la fórmula:
![]()
Puede obtener más información sobre esta y otras métricas de evaluación aquí:
Evaluemos el desempeño de nuestro modelo usando la puntuación F1:
![]()
![]()
Aquí, puede ver que el árbol de decisiones funciona bien en la evaluación dentro de la muestra, pero su rendimiento disminuye drásticamente en la evaluación fuera de la muestra. ¿Por qué crees que ese es el caso? Desafortunadamente, nuestro modelo de árbol de decisiones está sobreajustado a los datos de entrenamiento. ¿El bosque aleatorio resolverá este problema?
Construyendo un modelo de bosque aleatorio
Veamos un modelo de bosque aleatorio en acción:
![]()
![]()
Aquí, podemos ver claramente que el modelo de bosque aleatorio funcionó mucho mejor que el árbol de decisiones en la evaluación fuera de la muestra. Analicemos las razones detrás de esto en la siguiente sección.
¿Por qué nuestro modelo de bosque aleatorio superó al árbol de decisiones?
El bosque aleatorio aprovecha el poder de múltiples árboles de decisión. Lo hace no dependen de la importancia de la característica dada por un único árbol de decisión. Echemos un vistazo a la importancia de la característica dada por diferentes algoritmos a diferentes características:
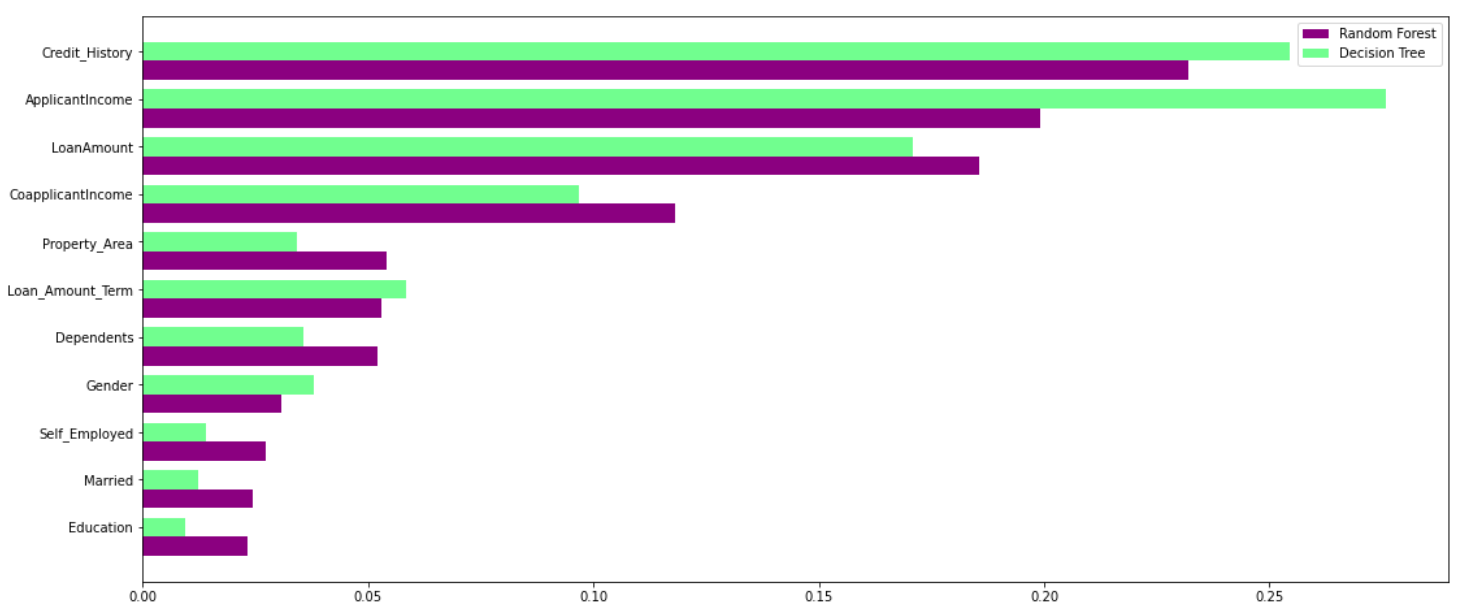
Como puede ver claramente en el gráfico anterior, el modelo de árbol de decisión otorga gran importancia a un conjunto particular de características. Pero el bosque aleatorio elige características al azar durante el proceso de entrenamiento. Por lo tanto, no depende en gran medida de ningún conjunto específico de características. Ésta es una característica especial del bosque aleatorio sobre árboles ensacados. Puedes leer más sobre la bolsa.clasificador de árboles ing aquí.
Por lo tanto, el bosque aleatorio puede generalizar los datos de una mejor manera. Esta selección aleatoria de características hace que el bosque aleatorio sea mucho más preciso que un árbol de decisiones.
Entonces, ¿cuál debería elegir: árbol de decisión o bosque aleatorio?
Random Forest es adecuado para situaciones en las que tenemos un gran conjunto de datos y la interpretabilidad no es una preocupación importante.
Los árboles de decisión son mucho más fáciles de interpretar y comprender. Dado que un bosque aleatorio combina varios árboles de decisión, se vuelve más difícil de interpretar. Aquí están las buenas noticias: no es imposible interpretar un bosque aleatorio. Aquí hay un artículo que habla sobre interpretar los resultados de un modelo de bosque aleatorio:
Además, Random Forest tiene un tiempo de entrenamiento más alto que un solo árbol de decisiones. Debe tener esto en cuenta porque a medida que aumentamos la cantidad de árboles en un bosque aleatorio, el tiempo que se tarda en entrenar a cada uno de ellos también aumenta. Eso a menudo puede ser crucial cuando trabaja con una fecha límite ajustada en un proyecto de aprendizaje automático.
Pero diré esto: a pesar de la inestabilidad y la dependencia de un conjunto particular de características, los árboles de decisión son realmente útiles porque son más fáciles de interpretar y más rápidos de entrenar. Cualquiera con muy poco conocimiento de la ciencia de datos también puede usar árboles de decisión para tomar decisiones rápidas basadas en datos.
Notas finales
Eso es esencialmente lo que necesita saber en el árbol de decisiones frente al debate forestal aleatorio. Puede resultar complicado cuando eres nuevo en el aprendizaje automático, pero este artículo debería haber aclarado las diferencias y similitudes para ti.
Puede comunicarse conmigo con sus consultas y pensamientos en la sección de comentarios a continuación.





