Introducción
Se está volviendo muy difícil mantenerse actualizado con los avances recientes que se están produciendo en el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... Casi no pasa un día sin que llegue una nueva innovación o una nueva aplicación de aprendizaje profundo. Sin embargo, la mayoría de estos avances están ocultos dentro de una gran cantidad de artículos de investigación que se publican en medios como ArXiv / Springer.

Para mantenernos actualizados, hemos creado un pequeño grupo de lectura para compartir nuestros aprendizajes internamente en DataPeaker. Uno de esos aprendizajes que me gustaría compartir con la comunidad es un estudio de arquitecturas avanzadas que han sido desarrolladas por la comunidad de investigadores.
Este artículo contiene algunos de los avances recientes en Deep Learning junto con códigos para la implementación en la biblioteca de keras. También he proporcionado enlaces a los artículos originales, en caso de que esté interesado en leerlos o quiera hacer referencia a ellos.
Para mantener el artículo conciso, solo he considerado las arquitecturas que han tenido éxito en el dominio de la Visión por Computadora.
Si estás interesado, ¡sigue leyendo!
PD: Este artículo asume el conocimiento de las redes neuronales y la familiaridad con keras. Si necesita ponerse al día con estos temas, le recomiendo encarecidamente que lea primero los siguientes artículos:
Tabla de contenido
- ¿Qué entendemos por arquitectura avanzada?
- Tipos de tareas de visión artificial
- Lista de arquitecturas de aprendizaje profundo
¿Qué entendemos por arquitectura avanzada?
Los algoritmos de aprendizaje profundo constan de un conjunto de modelos tan diverso en comparación con un único algoritmo de aprendizaje automático tradicional. Esto se debe a la flexibilidad que proporciona la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... al crear un modelo completo de extremo a extremo.
La red neuronal a veces se puede comparar con los bloques de lego, donde puedes construir casi cualquier estructura simple o compleja que tu imaginación te ayude a construir.
Podemos definir una arquitectura avanzada como aquella que tiene un historial probado de ser un modelo exitoso. Esto se ve principalmente en desafíos como ImageNet, donde su tarea es resolver un problema, digamos el reconocimiento de imágenes, utilizando los datos proporcionados. Aquellos que no saben qué es ImageNet, es el conjunto de datos que se proporciona en el desafío ILSVR (ImageNet Large Scale Visual Recognition).
También como se describe en las arquitecturas mencionadas a continuación, cada una de ellas tiene un matiz que las diferencia de los modelos habituales; dándoles una ventaja cuando se utilizan para resolver un problema. Estas arquitecturas también entran en la categoría de modelos «profundos», por lo que es probable que funcionen mejor que sus contrapartes superficiales.
Tipos de tareas de visión artificial
Este artículo se centra principalmente en la visión por computadora, por lo que es natural describir el horizonte de las tareas de visión por computadora. Visión por computador; como su nombre indica, es simplemente crear modelos artificiales que pueden replicar las tareas visuales realizadas por un ser humano. Esto esencialmente significa que lo que podemos ver y lo que percibimos es un proceso que se puede entender e implementar en un sistema artificial.
Los principales tipos de tareas en las que se puede clasificar la visión por computadora son los siguientes:
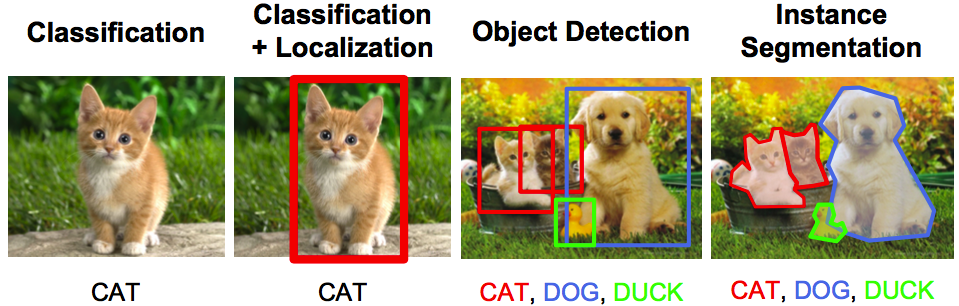
- Reconocimiento / clasificación de objetos – En el reconocimiento de objetos, se le da una imagen en bruto y su tarea es identificar a qué clase pertenece la imagen.
- Clasificación + Localización – Si solo hay un objeto en la imagen y su tarea es encontrar la ubicación de ese objeto, un término más específico para este problema es problema de localización.
- Detección de objetos – En la detección de objetos, su tarea es identificar en qué parte de la imagen se encuentran los objetos. Estos objetos pueden ser de la misma clase o de una clase completamente diferente.
- SegmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo.... de imagen – La segmentación de imágenes es una tarea un poco sofisticada, donde el objetivo es asignar cada píxel a su clase legítima.
Lista de arquitecturas de aprendizaje profundo
Ahora que hemos entendido qué es una arquitectura avanzada y hemos explorado las tareas de la visión por computadora, enumeremos las arquitecturas más importantes y sus descripciones:
1. AlexNet
AlexNet es la primera arquitectura profunda que fue introducida por uno de los pioneros en aprendizaje profundo: Geoffrey Hinton y sus colegas. Es una arquitectura de red simple pero poderosa, que ayudó a allanar el camino para una investigación innovadora en Deep Learning como es ahora. Aquí hay una representación de la arquitectura propuesta por los autores.
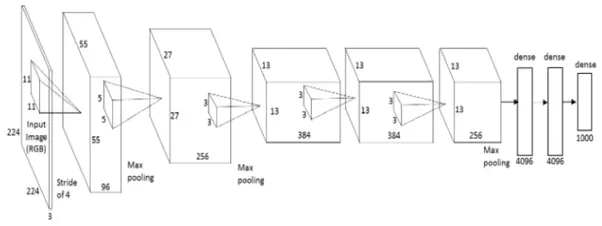
Cuando se descompone, AlexNet parece una arquitectura simple con capas convolucionales y agrupadas una encima de la otra, seguidas de capas completamente conectadas en la parte superior. Esta es una arquitectura muy simple, que fue conceptualizada en la década de 1980. Lo que distingue a este modelo es la escala en la que realiza la tarea y el uso de la GPU para el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... En la década de 1980, la CPU se utilizó para entrenar una red neuronal. Mientras que AlexNet acelera el entrenamiento 10 veces solo con el uso de GPU.
Aunque un poco desactualizado en este momento, AlexNet todavía se usa como punto de partida para aplicar redes neuronales profundas para todas las tareas, ya sea visión por computadora o reconocimiento de voz.
2. VGG Net
La red VGG fue presentada por los investigadores de Visual Graphics Group en Oxford (de ahí el nombre VGG). Esta red se caracteriza especialmente por su forma piramidal, donde las capas inferiores más cercanas a la imagen son anchas, mientras que las capas superiores son profundas.
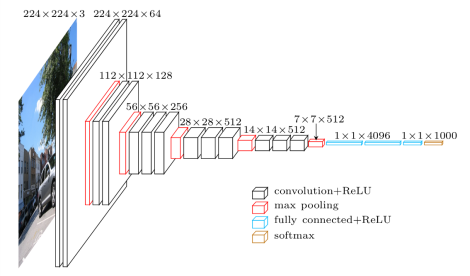
Como muestra la imagen, VGG contiene capas convolucionales posteriores seguidas de capas agrupadas. Las capas de agrupación son responsables de hacer que las capas sean más estrechas. En su artículo, propusieron múltiples tipos de redes de este tipo, con cambios en la profundidad de la arquitectura.
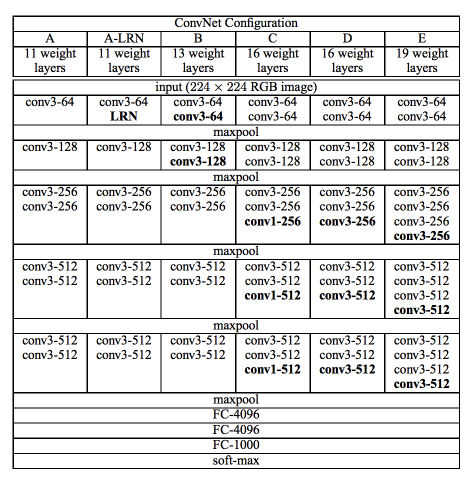
Las ventajas de VGG son:
- Es una muy buena arquitectura para realizar evaluaciones comparativas en una tarea en particular.
- Además, las redes previamente capacitadas para VGG están disponibles gratuitamente en Internet, por lo que se usa comúnmente para varias aplicaciones.
Por otro lado, su principal desventaja es que es muy lento de entrenar si se entrena desde cero. Incluso con una GPU decente, se necesitaría más de una semana para que funcione.
3. GoogleNet
GoogleNet (o Inception Network) es una clase de arquitectura diseñada por investigadores de Google. GoogleNet fue el ganador de ImageNet 2014, donde demostró ser un modelo poderoso.
En esta arquitectura, además de profundizar (contiene 22 capas en comparación con VGG que tenía 19 capas), los investigadores también hicieron un enfoque novedoso llamado módulo Inception.
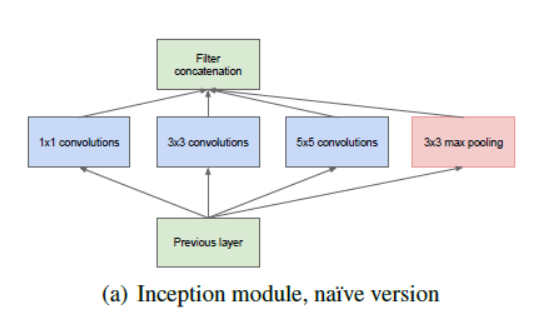
Como se vio anteriormente, es un cambio drástico de las arquitecturas secuenciales que vimos anteriormente. En una sola capa, están presentes varios tipos de «extractores de características». Esto ayuda indirectamente a que la red funcione mejor, ya que la red en el entrenamiento tiene muchas opciones para elegir al resolver la tarea. Puede optar por convolucionar la entrada o agruparla directamente.
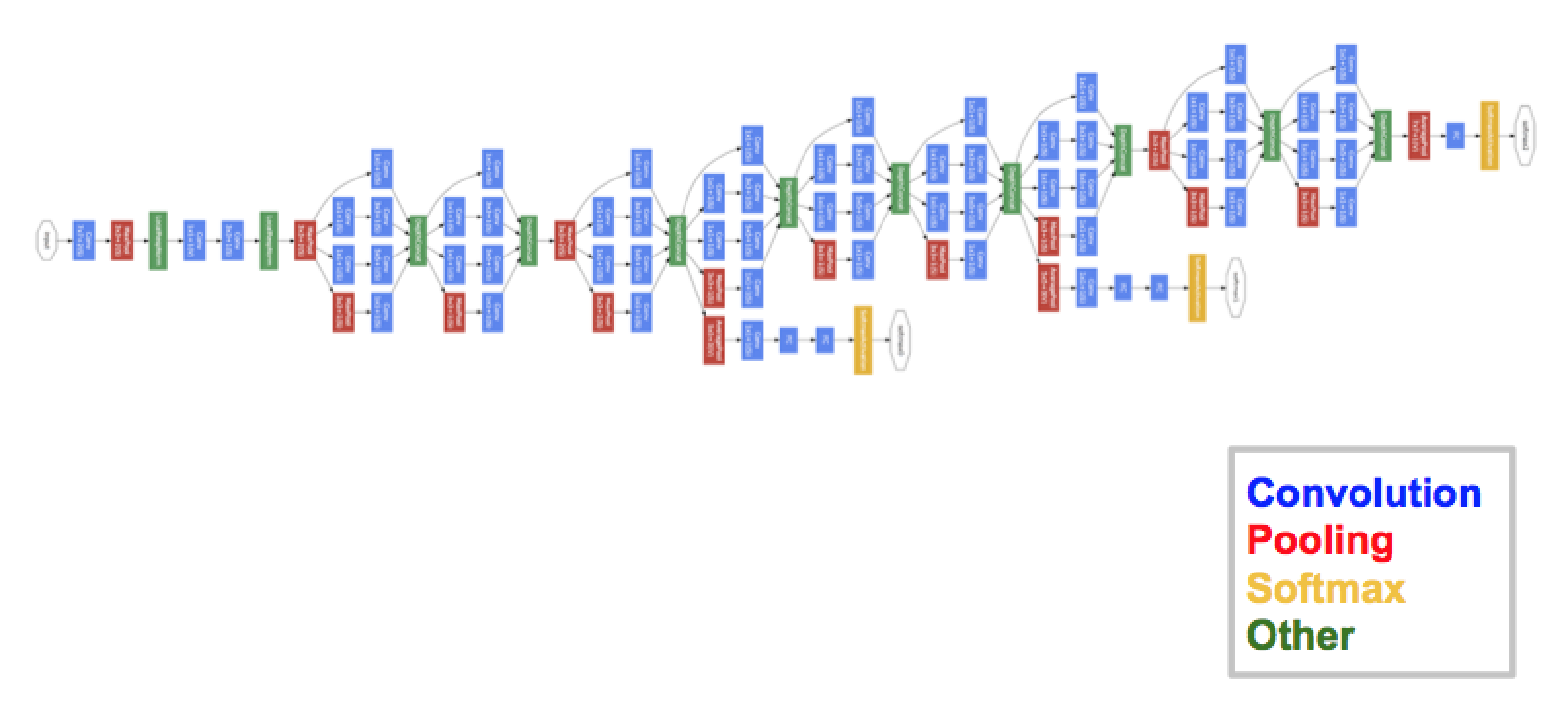
La arquitectura final contiene varios de estos módulos iniciales apilados uno sobre otro. Incluso el entrenamiento es ligeramente diferente en GoogleNet, ya que la mayoría de las capas superiores tienen su propia capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados..... Este matiz ayuda a que el modelo converja más rápido, ya que hay un entrenamiento conjunto y un entrenamiento paralelo para las propias capas.
Las ventajas de GoogleNet son:
- GoogleNet entrena más rápido que VGG.
- El tamaño de una red de Google previamente entrenada es comparativamente más pequeña que la de VGG. Un modelo VGG puede tener> 500 MB, mientras que GoogleNet tiene un tamaño de solo 96 MB
GoogleNet no tiene una desventaja inmediata per se, pero se proponen cambios adicionales en la arquitectura, que hacen que el modelo funcione mejor. Uno de esos cambios se denomina Red Xception, en la que se incrementa el límite de divergencia del módulo de inicio (4 en GoogleNet como vimos en la imagen de arriba). Ahora teóricamente puede ser infinito (¡de ahí que se le llame inicio extremo!)
4. ResNet
ResNet es una de las arquitecturas monstruosas que realmente define cuán profunda puede ser una arquitectura de aprendizaje profundo. Las redes residuales (ResNet para abreviar) consta de varios módulos residuales posteriores, que son el bloque de construcción básico de la arquitectura ResNet. Una representación del módulo residual es la siguiente
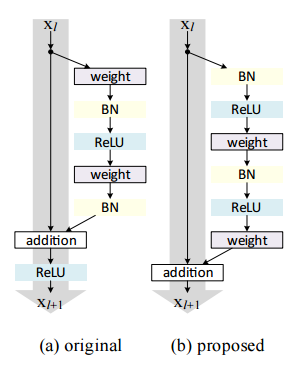
En palabras simples, un módulo residual tiene dos opciones, puede realizar un conjunto de funciones en la entrada o puede omitir este paso por completo.
Ahora similar a GoogleNet, estos módulos residuales se apilan uno sobre otro para formar una red completa de un extremo a otro.

Algunas técnicas más novedosas que introdujo ResNet son:
- Uso de SGD estándar en lugar de una elegante técnica de aprendizaje adaptativo. Esto se hace junto con una función de inicialización razonable que mantiene intacto el entrenamiento.
- Cambios en el preprocesamiento de la entrada, donde la entrada se divide primero en parches y luego se alimenta a la red.
La principal ventaja de ResNet es que cientos, incluso miles de estas capas residuales pueden usarse para crear una red y luego entrenarse. Esto es un poco diferente de las redes secuenciales habituales, donde ve que hay mejoras de rendimiento reducidas a medida que aumenta el número de capas.
5. ResNeXt
Se dice que ResNeXt es la técnica actual más avanzada para el reconocimiento de objetos. Se basa en los conceptos de inicio y resnet para generar una arquitectura nueva y mejorada. La siguiente imagen es un resumen de cómo se ve un módulo residual del módulo ResNeXt.
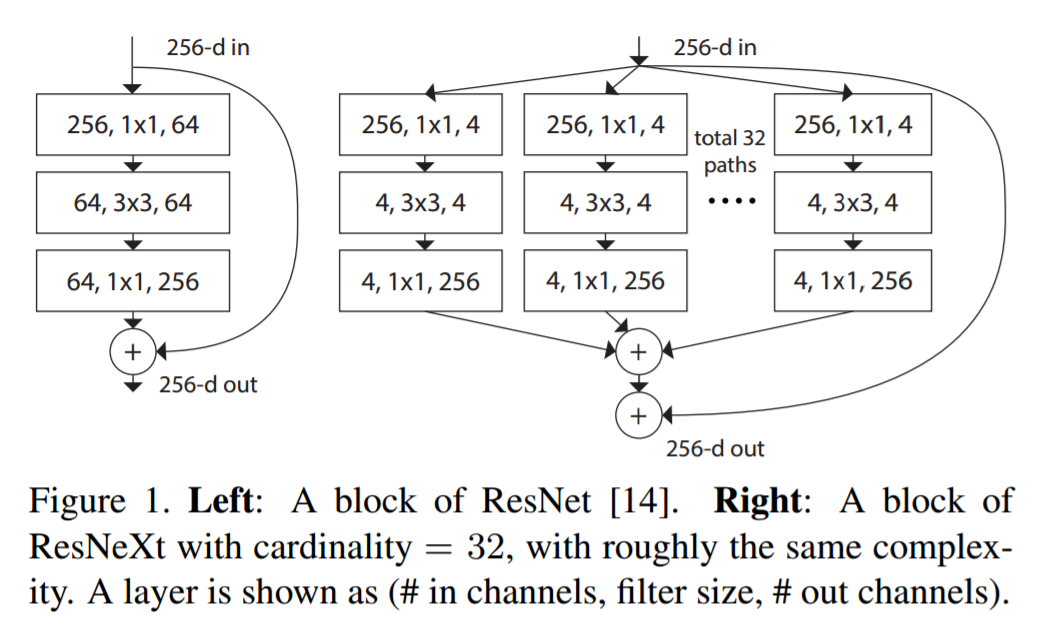
6. RCNN (CNN regional)
Se dice que la arquitectura CNN basada en regiones es la más influyente de todas las arquitecturas de aprendizaje profundo que se han aplicado al problema de detección de objetos. Para resolver el problema de detección, lo que hace RCNN es intentar dibujar un cuadro delimitador sobre todos los objetos presentes en la imagen y luego reconocer qué objeto está en la imagen. Funciona de la siguiente manera:
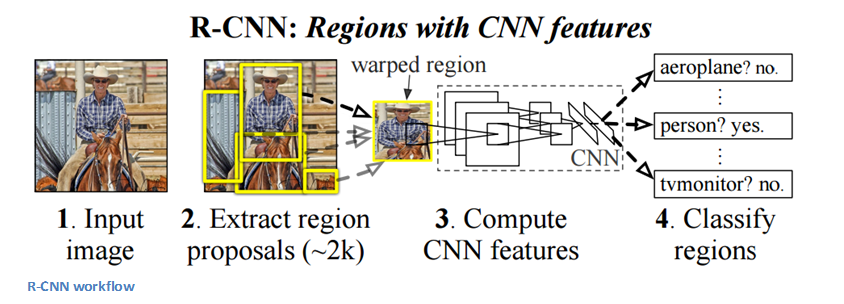
La estructura de RCNN es la siguiente:
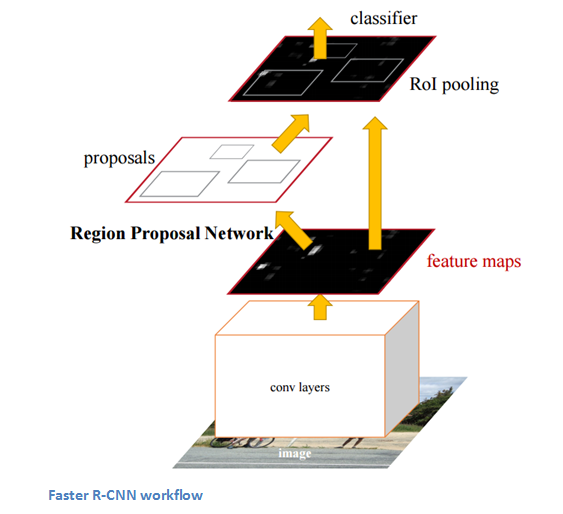
7. YOLO (solo miras una vez)
YOLO es el sistema actual de última generación en tiempo real basado en el aprendizaje profundo para resolver problemas de detección de imágenes. Como se ve en la imagen dada a continuación, primero divide la imagen en cuadros delimitadores definidos y luego ejecuta un algoritmo de reconocimiento en paralelo para todos estos cuadros para identificar a qué clase de objeto pertenecen. Después de identificar estas clases, pasa a fusionar estos cuadros de forma inteligente para formar un cuadro delimitador óptimo alrededor de los objetos.

Todo esto se hace en paralelo, por lo que puede ejecutarse en tiempo real; procesando hasta 40 imágenes en un segundo.
Aunque ofrece un rendimiento reducido que su contraparte RCNN, todavía tiene la ventaja de ser en tiempo real para ser viable para su uso en los problemas del día a día. Aquí hay una representación de la arquitectura de YOLO.
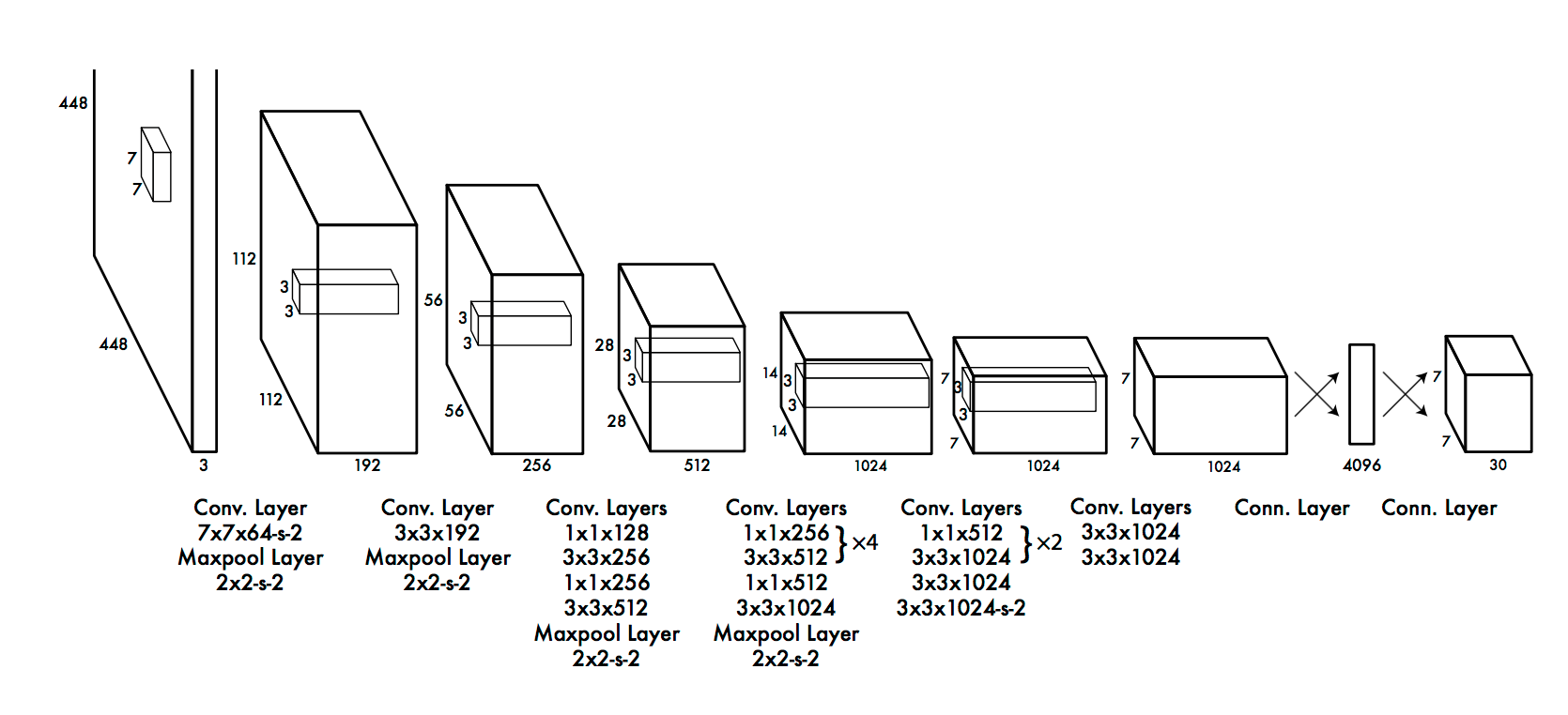
8. SqueezeNet
La arquitectura squeezeNet es una arquitectura más poderosa que es extremadamente útil en escenarios de ancho de banda bajo como las plataformas móviles. Esta arquitectura ocupa solo 4,9 MB de espacio, por otro lado, ¡el inicio ocupa ~ 100 MB! Este cambio drástico es provocado por una estructura especializada llamada módulo de incendios. La imagen de abajo es una representación del módulo de fuego.
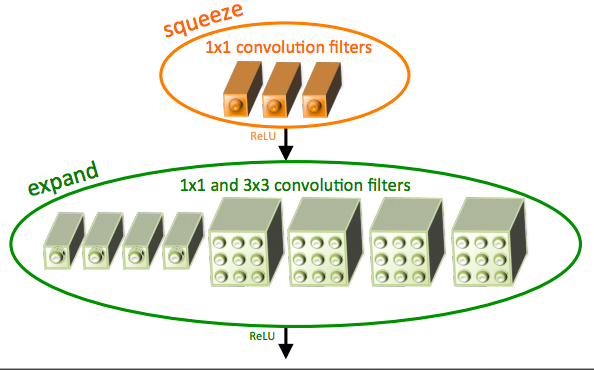
La arquitectura final de squeezeNet es la siguiente:
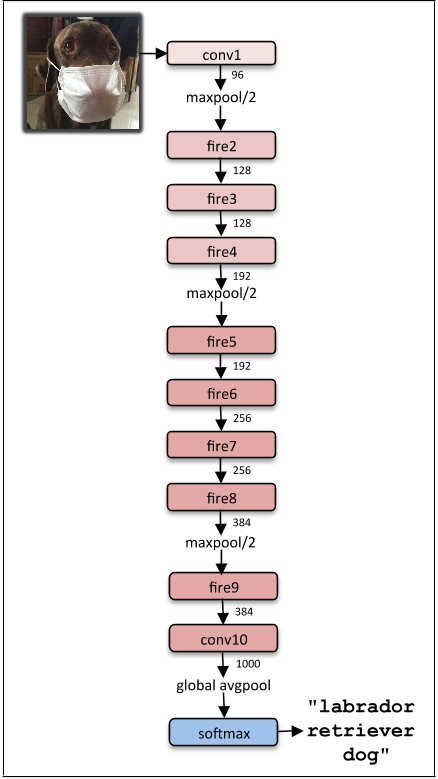
9. SegNet
SegNet es una arquitectura de aprendizaje profundo aplicada para resolver problemas de segmentación de imágenes. Consiste en una secuencia de capas de procesamiento (codificadores) seguida de un conjunto correspondiente de descodificadores para una clasificación por píxeles. La siguiente imagen resume el funcionamiento de SegNet.
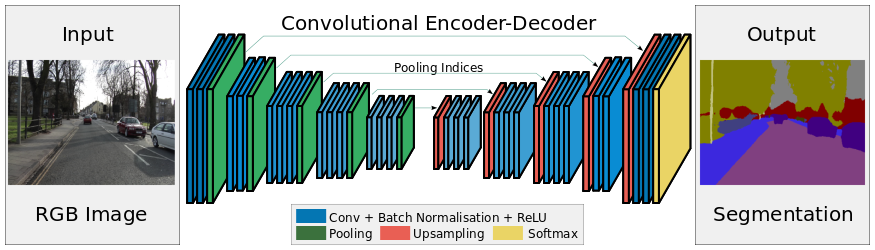
Una característica clave de SegNet es que conserva los detalles de alta frecuencia en la imagen segmentada, ya que los índices de agrupación de la red del codificador están conectados a los índices de agrupación de las redes de decodificadores. En resumen, la transferencia de información es directa en lugar de convolucionarlos. SegNet es uno de los mejores modelos para usar cuando se trata de problemas de segmentación de imágenes.
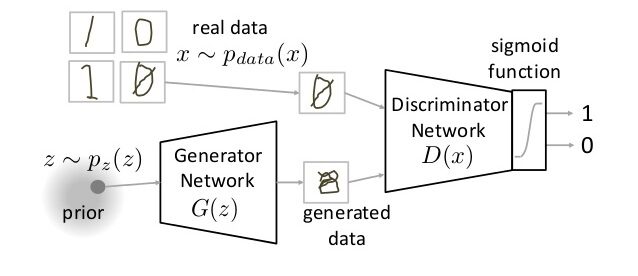
10. GAN (Generative Adversarial Network)
GAN es una clase completamente diferente de arquitecturas de redes neuronales, en las que se utiliza una red neuronal para generar una imagen completamente nueva que no está presente en el conjunto de datos de entrenamiento, pero es lo suficientemente realista como para estar en el conjunto de datos. Por ejemplo, la siguiente imagen es un desglose de las GAN. He cubierto cómo funcionan las GAN en este artículo. Revíselo si tiene curiosidad.
Notas finales
En este artículo, he cubierto una descripción general de las principales arquitecturas de aprendizaje profundo con las que debe familiarizarse. Si tiene alguna pregunta sobre arquitecturas de aprendizaje profundo, no dude en compartirla conmigo a través de los comentarios.





