Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Big Data se caracteriza a menudo por: –
a) Volumen: – El volumen significa una enorme y enorme cantidad de datos que deben procesarse.
B) Velocidad: – La velocidad con la que llegan los datos como procesamiento en tiempo real.
C) Veracidad: – Veracidad significa la calidad de los datos (que en realidad debe ser excelente para generar informes de análisis, etc.)
D) Variedad: – Significa los diferentes tipos de datos como
* Datos estructurados: – Datos en formato de tabla.
* Datos no estructurados: – Datos no en formato de tabla
* Datos semiestructurados: – Mezcla de datos estructurados y no estructurados.
Para trabajar con grandes bytes de datos, primero necesitamos almacenar o volcar los datos en algún lugar. Por tanto, la solución a esto es HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información... (sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... Hadoop).
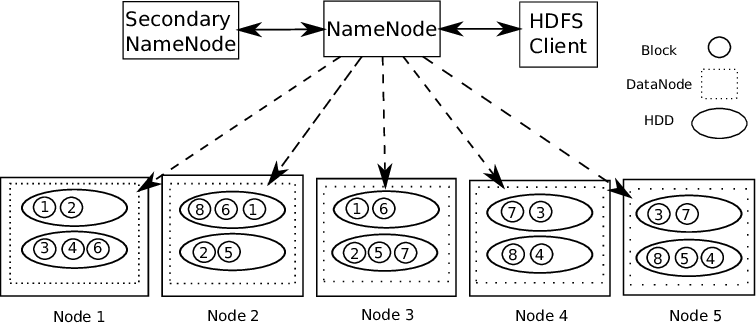
Soportes de Hadoop Arquitectura maestro-esclavo. Es un tipo de sistema distribuido donde se realiza el procesamiento paralelo de datos. Hadoop consta de 1 maestro y varios esclavos.
NodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... de regla de nombre: – Por cada bloque de datos que se almacena, hay 2 copias presentes. Uno en diferentes nodos de datos y una segunda copia en otro nodo de datos. De esta forma, se soluciona el problema de la tolerancia a fallos.
El nodo de nombre contiene la siguiente información: –
1) Información de metadatos de los archivos almacenados en los nodos de datos. Los metadatos constan de 2 archivos: FsImage y EditLogs. FsImage consiste en el estado completo del sistema de archivos desde el inicio del Name Node. EditLogs contiene modificaciones recientes que se realizan en el sistema de archivos.
2) ubicación del bloque de archivos almacenado en el nodo de datos.
3) Tamaño de los archivos.
El nodo de datos contiene los datos reales.
Por lo tanto, HDFS admite integridad de los datos. Los datos que se almacenan se verifican si son correctos o no al comparar los datos con su suma de verificación. Si se detectan fallas, se informa al nodo de nombres. Por lo tanto, crea copias adicionales de los mismos datos y elimina las copias dañadas.
HDFS consta de Nodo de nombre secundario que funciona al mismo tiempo que el Name Node principal como demonio auxiliar. No es un nodo de nombre de respaldo. Lee constantemente todos los sistemas de archivos y metadatos de la RAM del Name Node al disco duro. Es responsable de combinar EditLogs con FSImage de Name Node.
Por lo tanto, HDFS es como un almacén de datos donde podemos volcar cualquier tipo de datos. El procesamiento de estos datos requiere herramientas de Hadoop como HiveHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.... (para el manejo de datos estructurados), HBaseHBase es una base de datos NoSQL diseñada para manejar grandes volúmenes de datos distribuidos en clústeres. Basada en el modelo de columnas, permite un acceso rápido y escalable a la información. HBase se integra fácilmente con Hadoop, lo que la convierte en una opción popular para aplicaciones que requieren almacenamiento y procesamiento de datos masivos. Su flexibilidad y capacidad de crecimiento la hacen ideal para proyectos de big data.... (para el manejo de datos no estructurados), etc. Hadoop admite el concepto «Escribir una vez, listo para muchos».
Entonces, tomemos un ejemplo y entendamos cómo podemos procesar una enorme cantidad de datos y realizar muchas transformaciones usando Scala Language.
A) Configuración de Eclipse IDE con la configuración de Scala.
Enlace para descargar eclipse IDE – https://www.eclipse.org/downloads/
Debe descargar el IDE de Eclipse teniendo en cuenta los requisitos de su computadora. Al iniciar el IDE de eclipse, verá este tipo de pantalla.

Ir a Ayudar -> Eclipse Marketplace -> Buscar -> Scala-Ide -> Instalar en pc
Después de eso en Eclipse IDE – seleccione Perspectiva abierta -> Scala, obtendrá todos los componentes de scala en el ide para usar.
Cree un nuevo proyecto en eclipse y actualice el archivo pom con los siguientes pasos:https://medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883
Cambie la versión de la biblioteca scala haciendo clic derecho en Proyecto -> Construir camino -> Configurar ruta de compilación.
Actualice el proyecto haciendo clic derecho en Proyecto -> Maven -> Actualizar proyecto Maven -> Forzar actualización de instantáneas / versiones. Por lo tanto, el archivo pom se guarda y todas las dependencias requeridas se descargan para el proyecto.
Después de eso, descargue la versión Spark con Hadoop winutils colocadas en la ruta bin. Siga este camino para completar la configuración: https://stackoverflow.com/questions/25481325/how-to-set-up-spark-on-windows
B) Creación de sesiones de Spark – 2 tipos.
Spark Session es el punto de entrada o el comienzo para crear RDD’S, Dataframe, Datasets. Para crear cualquier aplicación de chispa, primero necesitamos una sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... de chispa.
Spark Session puede ser de 2 tipos: –
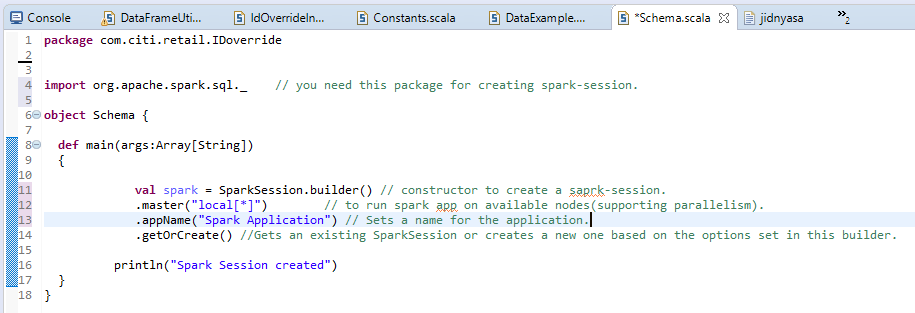
a) Sesión normal de Spark: –
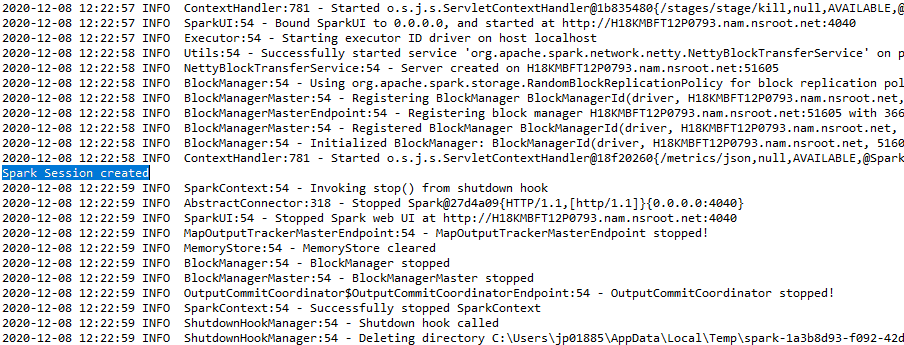
La salida se mostrará como: –
b) Sesión de Spark para el entorno de Hive: –
Para crear un entorno de colmena a escala, necesitamos la misma sesión de chispa con una línea adicional agregada. enableHiveSupport () – habilita el soporte de Hive, incluida la conectividad con el metastore de Hive persistente, el soporte para serdes de Hive y las funciones definidas por el usuario de Hive.
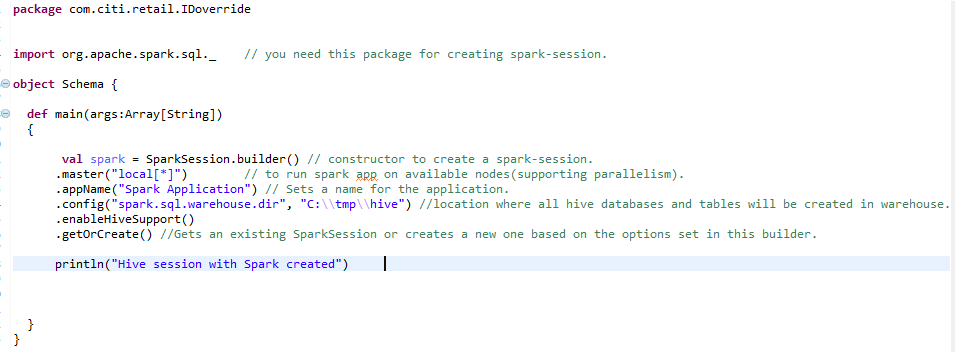
C) Creación de RDD (Resilient Distributed Dataset)RDD (Resilient Distributed Dataset) es una abstracción fundamental en Apache Spark que permite el procesamiento eficiente de grandes volúmenes de datos. Se caracteriza por su capacidad para ser tolerante a fallos, permitiendo la recuperación de datos perdidos mediante la reconstrucción de particiones. Los RDD son inmutables, lo que facilita la paralelización de operaciones y mejora el rendimiento en la computación distribuida. Su uso es esencial para el análisis de datos... y transformación de RDD en DataFrame: –
Entonces, después del primer paso de crear Spark-Session, somos libres de crear RDD, conjuntos de datos o marcos de datos. Estas son las estructuras de datos en las que podemos almacenar grandes cantidades de datos.
Elástico:- significa tolerancia a fallas para que puedan volver a calcular las particiones faltantes o dañadas debido a fallas en los nodos.
Repartido:- significa que los datos se distribuyen en varios nodos (poder del paralelismo).
Conjuntos de datos: – Datos que se pueden cargar externamente y que pueden ser de cualquier forma, es decir, JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software..., CSV o archivo de texto.
Las características de los RDD incluyen: –
a) Cálculo en memoria: – Después de realizar transformaciones en datos, los resultados se almacenan en la RAM en lugar de en un disco. Por lo tanto, RDD no puede utilizar grandes conjuntos de datos. La solución a esto es, en lugar de utilizar RDD, se considera el uso de DataFrame / DatasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.....
B) Evaluaciones perezosas: – Significa que las acciones de las transformaciones realizadas se evalúan solo cuando se necesita el valor.
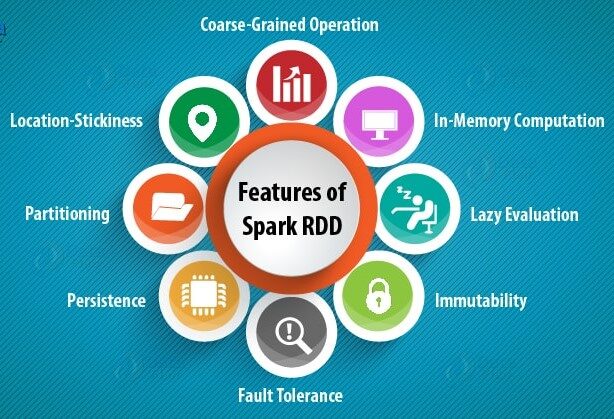
C) Tolerancia a fallos: – Los RDD de Spark son tolerantes a fallas ya que rastrean la información del linaje de datos para reconstruir los datos perdidos automáticamente en caso de falla.
D) Inmutabilidad: – Los datos inmutables (no modificables) siempre son seguros para compartir en múltiples procesos. Podemos recrear el RDD en cualquier momento.
mi) Fraccionamiento: – Significa dividir los datos, por lo que cada partición puede ser ejecutada por diferentes nodos, por lo que el procesamiento de datos se vuelve más rápido.
F) Persistencia:- Los usuarios pueden elegir qué RDD necesitan usar y elegir una estrategia de almacenamiento para ellos.
gramo) Operaciones de grano grueso: – Significa que cuando los datos se dividen en diferentes clústeres para diferentes operaciones, podemos aplicar transformaciones una vez para todo el clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... y no para diferentes particiones por separado.
D) Uso del marco de datos y realización de transformaciones: –
Al convertir RDD en marcos de datos, debe agregar import spark.implicits._ después de la chispa sesión.
El marco de datos se puede crear de muchas formas. Veamos las diferentes transformaciones que se pueden aplicar al marco de datos.
Paso 1:- Creando marco de datos: –
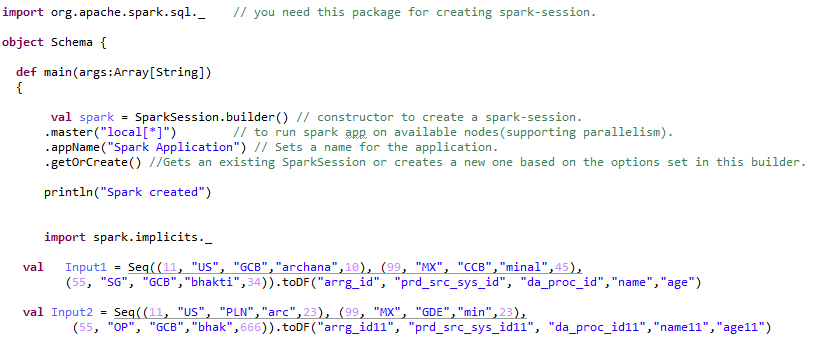
Paso 2:- Realización de diferentes tipos de transformaciones en un marco de datos: –
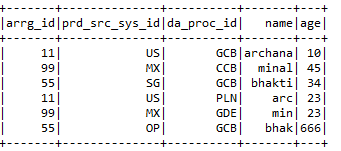
a) Seleccione:- Selecciona las columnas requeridas del marco de datos que requiere el usuario.
Input1.select («arrg_id», «da_proc_id»). Show ()

B) selectExpr: – Selecciona las columnas requeridas y también cambia el nombre de las columnas.
Input2.selectExpr («arrg_id11», «prd_src_sys_id11 como prd_src_new», «da_proc_id11»). Show ()

C) con Columna: – withColumns ayuda a agregar una nueva columna con el valor particular que el usuario desea en el marco de datos seleccionado.
Input1.withColumn («New_col», iluminado (nulo))

D) withColumnRenamed: – Cambia el nombre de las columnas del marco de datos particular que requiere el usuario.
Input1.withColumnRenamed («da_proc_id», «da_proc_id_newname»)

mi) soltar:- Elimina las columnas que el usuario no quiere.
Input2.drop («arrg_id11 ″,» prd_src_sys_id11 ″, «da_proc_id11»)
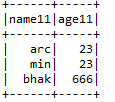
F) Entrar:- Une 2 marcos de datos junto con claves de unión de ambos marcos de datos.
Input1.join (Input2, Input1.col («arrg_id») === Input2.col («arrg_id11 ″),» right «)
.withColumn («prd_src_sys_id», iluminado (nulo))
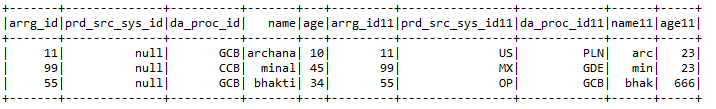
gramo) Funciones agregadas:- Algunas de las funciones agregadas incluyen
* Contar:- Da el recuento de una columna en particular o el recuento del marco de datos como un todo.
println (Input1.count ())
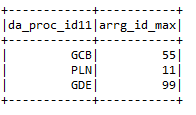
* Máx .: – Da el valor máximo de la columna según una condición particular.
input2.groupBy («da_proc_id»). max («arrg_id»). withColumnRenamed («max (arrg_id)»,
«Arrg_id_max»)
* Min: – Da un valor mínimo de la columna del marco de datos.

h) filtrar: – Filtra las columnas de un marco de datos ejecutando una condición particular.

I) printSchema: – Proporciona detalles como nombres de columna, tipos de datos de columnas y si las columnas pueden ser anulables o no.
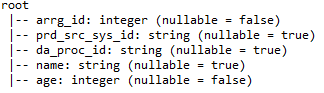
j) Unión: – Combina los valores de 2 marcos de datos siempre que los nombres de columna de ambos marcos de datos sean iguales.
MI) Colmena:-
Hive es una de las bases de datos más utilizadas en Big Data. Es una especie de base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... relacional donde los datos se almacenan en formato tabular. La base de datos predeterminada de la colmena es la derby. Procesos de colmena estructurado y semiestructurado datos. En caso de datos no estructurados, primero cree una tabla en la colmena y cargue los datos en la tabla, así estructurada. Hive admite todos los tipos de datos primitivos de SQL.
Hive admite 2 tipos de tablas: –
a) Tablas gestionadas: – Es la tabla predeterminada en Hive. Cuando el usuario crea una tabla en Hive sin especificarla como externa, de forma predeterminada, se crea una tabla interna en una ubicación específica en HDFS.
De forma predeterminada, se creará una tabla interna en una ruta de carpeta similar a / usuario / colmena / almacén directorio de HDFS. Podemos anular la ubicación predeterminada por la propiedad de ubicación durante la creación de la tabla.
Si descartamos la tabla o partición administrada, los datos de la tabla y los metadatos asociados con esa tabla se eliminarán del HDFS.
B) Mesa externa: – Las tablas externas se almacenan fuera del directorio del almacén. Pueden acceder a los datos almacenados en fuentes como ubicaciones HDFS remotas o volúmenes de almacenamiento de Azure.
Siempre que dejamos caer la tabla externa, solo se eliminarán los metadatos asociados con la tabla, los datos de la tabla permanecen intactos por Hive.
Podemos crear la tabla externa especificando el EXTERNO palabra clave en la instrucción de tabla de creación de Hive.
Comando para crear una tabla externa.
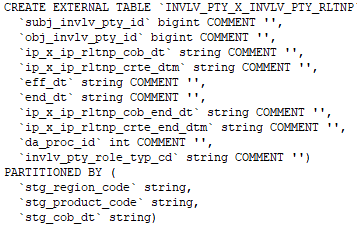
Comando para comprobar si la tabla creada es externa o no: –
desc con formato