Introducción
¿Alguna vez te has topado con un conjunto de datos o una imagen y te has preguntado si podrías crear un sistema capaz de diferenciar o identificar la imagen?
El concepto de clasificación de imágenes nos ayudará con eso. La clasificación de imágenes es una de las aplicaciones más populares de la visión por computadora y un concepto imprescindible para cualquiera que desee desempeñar un papel en este campo.
En este artículo, veremos una aplicación muy simple pero muy utilizada que es la Clasificación de imágenes. No solo veremos cómo hacer un modelo simple y eficiente para clasificar los datos, sino que también aprenderemos cómo implementar un modelo previamente entrenado y comparar el desempeño de los dos.
Al final del artículo, podrá encontrar un conjunto de datos propio e implementar la clasificación de imágenes con facilidad.
Requisitos previos antes de comenzar:
¿Suena interesante? ¡Así que prepárate para crear tu propio clasificador de imágenes!
Tabla de contenido
- Clasificación de imágenes
- Comprensión de la declaración del problema
- Configuración de los datos de la imagen
- Construyamos nuestro modelo de clasificación de imágenes
- Preprocesamiento de datos
- Aumento de datos
- Definición y formación del modelo
- Evaluación de resultados
- El arte del aprendizaje transferido
- Importar el modelo base de MobileNetV2
- Sintonia FINA
- Capacitación
- Evaluación de resultados
- ¿Que sigue?
¿Qué es la clasificación de imágenes?
La clasificación de imágenes es la tarea de asignar una imagen de entrada, una etiqueta de un conjunto fijo de categorías. Este es uno de los problemas centrales de la Visión por Computador que, a pesar de su simplicidad, tiene una gran variedad de aplicaciones prácticas.
Tomemos un ejemplo para entenderlo mejor. Cuando realicemos la clasificación de imágenes, nuestro sistema recibirá una imagen como entrada, por ejemplo, un gato. Ahora el sistema conocerá un conjunto de categorías y su objetivo es asignar una categoría a la imagen.
Este problema puede parecer simple o fácil, pero es un problema muy difícil de resolver para la computadora. Como sabrá, la computadora ve una cuadrícula de números y no la imagen de un gato como lo vemos nosotros. Las imágenes son matrices tridimensionales de números enteros de 0 a 255, de tamaño Ancho x Alto x 3. El 3 representa los tres canales de color Rojo, Verde, Azul.
Entonces, ¿cómo puede nuestro sistema aprender a identificar esta imagen? Mediante el uso de redes neuronales convolucionales. Las redes neuronales convolucionales o CNN son una clase de redes neuronales de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... que representan un gran avance en el reconocimiento de imágenes. Es posible que ya tenga una comprensión básica de las CNN, y sabemos que las CNN consisten en capas convolucionales, capas ReluLa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción..., capas agrupadas y capas densas totalmente conectadas.
Para leer sobre Clasificación de imágenes y CNN en detalle, puede consultar los siguientes recursos: –
- https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
- https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
Ahora que comprendemos los conceptos, profundicemos en cómo se puede construir un modelo de clasificación de imágenes y cómo se puede implementar.
Comprensión de la declaración del problema
Considere la siguiente imagen:

Una persona bien versada en deportes podrá reconocer la imagen como Rugby. Puede haber diferentes aspectos de la imagen que te ayudaron a identificarla como Rugby, podría ser la forma de la pelota o el atuendo del jugador. ¿Pero notó que esta imagen muy bien podría identificarse como una imagen de fútbol?
Consideremos otra imagen: –

¿Qué crees que representa esta imagen? Difícil de adivinar, ¿verdad? La imagen para el ojo humano inexperto puede fácilmente clasificarse erróneamente como fútbol, pero en realidad, es una imagen de rugby, ya que podemos ver que el poste de la portería detrás no es una red y es de mayor tamaño. La pregunta ahora es si podemos hacer un sistema que posiblemente pueda clasificar la imagen correctamente.
Esa es la idea detrás de nuestro proyecto aquí, queremos construir un sistema que sea capaz de identificar el deporte representado en esa imagen. Las dos clases de clasificación aquí son Rugby y Fútbol. El planteamiento del problema puede ser un poco complicado ya que los deportes tienen muchos aspectos en común, sin embargo, aprenderemos cómo abordar el problema y crear un sistema de buen rendimiento.
Configuración de nuestros datos de imagen
Dado que estamos trabajando en un problema de clasificación de imágenes, he utilizado dos de las mayores fuentes de datos de imágenes, es decir, ImageNet y Google OpenImages. Implementé dos scripts de Python para que podamos descargar las imágenes fácilmente. Se descargaron un total de 3058 imágenes, que se dividieron en tren y prueba. Realicé una división 80-20 con la carpeta del tren que tenía 2448 imágenes y la carpeta de la prueba tiene 610. Ambas clases de Rugby y Fútbol tienen 1224 imágenes cada una.
Nuestra estructura de datos es la siguiente: –
- Entrada – 3058
- Tren – 2048
- Rugby – 1224
- Fútbol – 1224
- Tren – 2048
-
- Prueba – 610
- Rugby – 310
- Fútbol – 310
- Prueba – 610
¡Construyamos nuestro modelo de clasificación de imágenes!
Paso 1: – Importe las bibliotecas necesarias
Aquí usaremos la biblioteca de Keras para crear nuestro modelo y entrenarlo. También usamos Matplotlib y Seaborn para visualizar nuestro conjunto de datos y obtener una mejor comprensión de las imágenes que vamos a manejar. Otra biblioteca importante para manejar datos de imágenes es Opencv.
import matplotlib.pyplot as plt import seaborn as sns import keras from keras.models import Sequential from keras.layers import Dense, Conv2D , MaxPool2D , Flatten , Dropout from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import Adam from sklearn.metrics import classification_report,confusion_matrix import tensorflow as tf import cv2 import os import numpy as np
Paso 2: – Cargando los datos
A continuación, definamos la ruta a nuestros datos. Definamos una función llamada get_data () que nos facilite la creación de nuestro conjunto de datos de validación y tren. Definimos las dos etiquetas ‘Rugby’ y ‘Fútbol’ que usaremos. Usamos la función imread de Opencv para leer las imágenes en formato RGB y cambiar el tamaño de las imágenes a nuestro ancho y alto deseados, en este caso ambos son 224.
labels = ['rugby', 'soccer'] img_size = 224 def get_data(data_dir): data = [] for label in labels: path = os.path.join(data_dir, label) class_num = labels.index(label) for img in os.listdir(path): try: img_arr = cv2.imread(os.path.join(path, img))[...,::-1] #convert BGR to RGB format resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size data.append([resized_arr, class_num]) except Exception as e: print(e) return np.array(data)
Now we can easily fetch our train and validation data.
train = get_data('../input/traintestsports/Main/train')
val = get_data('../input/traintestsports/Main/test')
Paso 3: – Visualiza los datos
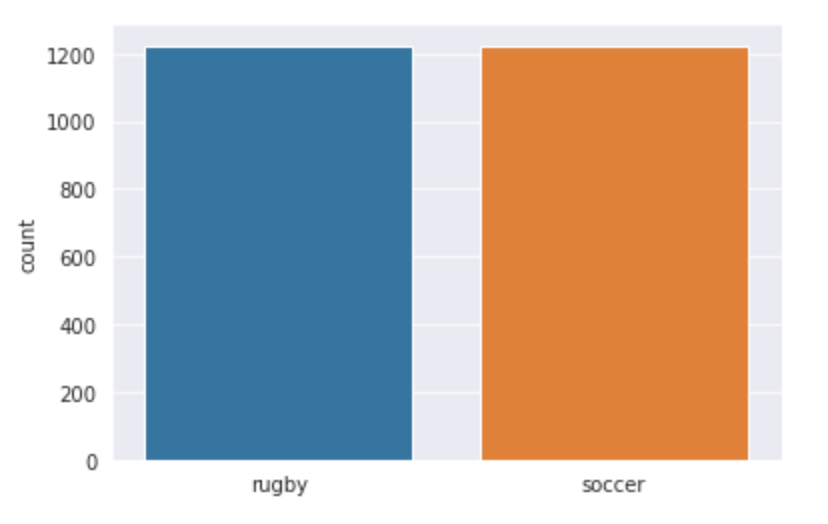
Visualicemos nuestros datos y veamos con qué estamos trabajando exactamente. Usamos seaborn para trazar el número de imágenes en ambas clases y puede ver cómo se ve la salida.
l = []
for i in train:
if(i[1] == 0):
l.append("rugby")
else
l.append("soccer")
sns.set_style('darkgrid')
sns.countplot(l)
Producción:
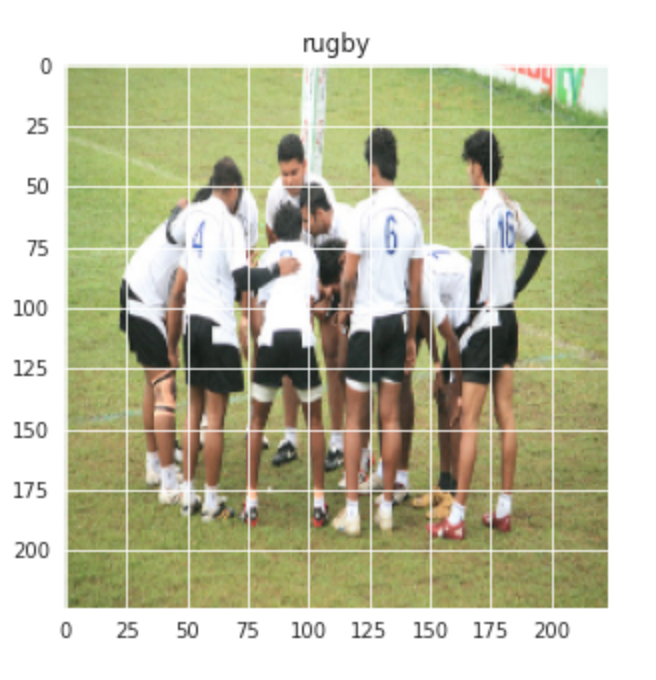
Visualicemos también una imagen aleatoria de las clases de Rugby y Fútbol: –
plt.figure(figsize = (5,5)) plt.imshow(train[1][0]) plt.title(labels[train[0][1]])
Producción:-
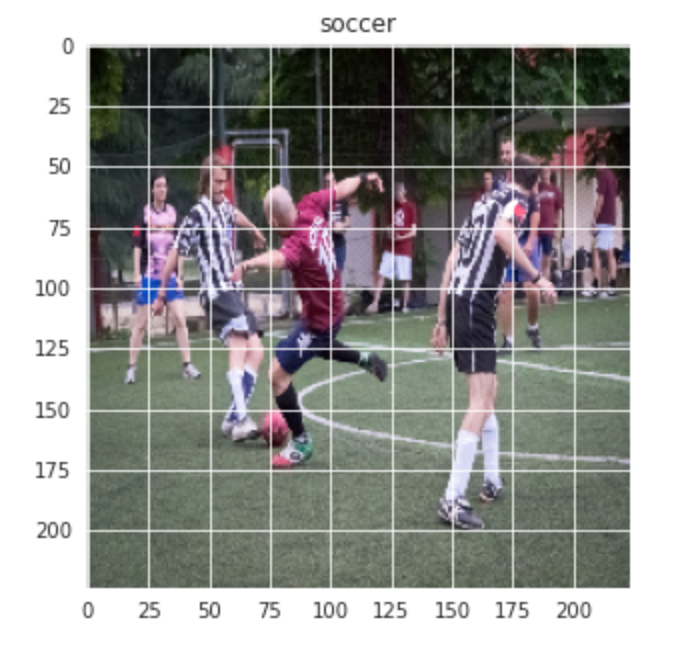
De manera similar para la imagen de fútbol: –
plt.figure(figsize = (5,5)) plt.imshow(train[-1][0]) plt.title(labels[train[-1][1]])
Producción:-
Paso 4: – Preprocesamiento y aumento de datos
A continuación, realizamos un poco de preprocesamiento y aumento de datos antes de que podamos continuar con la construcción del modelo.
x_train = [] y_train = [] x_val = [] y_val = [] for feature, label in train: x_train.append(feature) y_train.append(label) for feature, label in val: x_val.append(feature) y_val.append(label) # Normalize the data x_train = np.array(x_train) / 255 x_val = np.array(x_val) / 255 x_train.reshape(-1, img_size, img_size, 1) y_train = np.array(y_train) x_val.reshape(-1, img_size, img_size, 1) y_val = np.array(y_val)
Aumento de datos sobre los datos del tren: –
datagen = ImageDataGenerator( featurewise_center=False, # set input mean to 0 over the dataset samplewise_center=False, # set each sample mean to 0 featurewise_std_normalization=False, # divide inputs by std of the dataset samplewise_std_normalization=False, # divide each input by its std zca_whitening=False, # apply ZCA whitening rotation_range = 30, # randomly rotate images in the range (degrees, 0 to 180) zoom_range = 0.2, # Randomly zoom image width_shift_range=0.1, # randomly shift images horizontally (fraction of total width) height_shift_range=0.1, # randomly shift images vertically (fraction of total height) horizontal_flip = True, # randomly flip images vertical_flip=False) # randomly flip images datagen.fit(x_train)
Paso 5: – Definir el modelo
Definamos un modelo CNN simple con 3 capas convolucionales seguidas de capas de agrupación máxima. Se agrega una capa de caída después de la tercera operación de maxpool para evitar el sobreajuste.
model = Sequential() model.add(Conv2D(32,3,padding="same", activation="relu", input_shape=(224,224,3))) model.add(MaxPool2D()) model.add(Conv2D(32, 3, padding="same", activation="relu")) model.add(MaxPool2D()) model.add(Conv2D(64, 3, padding="same", activation="relu")) model.add(MaxPool2D()) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128,activation="relu")) model.add(Dense(2, activation="softmax")) model.summary()
Compilemos el modelo ahora usando Adam como nuestro optimizador y SparseCategoricalCrossentropy como la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y.... Estamos usando una tasa de aprendizaje más baja de 0.000001 para una curva más suave.
opt = Adam(lr=0.000001) model.compile(optimizer = opt , loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) , metrics = ['accuracy'])
Ahora, entrenemos nuestro modelo durante 500 épocas, ya que nuestra tasa de aprendizaje es muy pequeña.
history = model.fit(x_train,y_train,epochs = 500 , validation_data = (x_val, y_val))
Paso 6: – Evaluación del resultado
Trazaremos nuestra precisión de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y validación junto con la pérdida de entrenamiento y validación.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(500)
plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc, label="Validation Accuracy")
plt.legend(loc="lower right")
plt.title('Training and Validation Accuracy')
plt.subplot(2, 2, 2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss, label="Validation Loss")
plt.legend(loc="upper right")
plt.title('Training and Validation Loss')
plt.show()
Veamos cómo se ve la curva: –
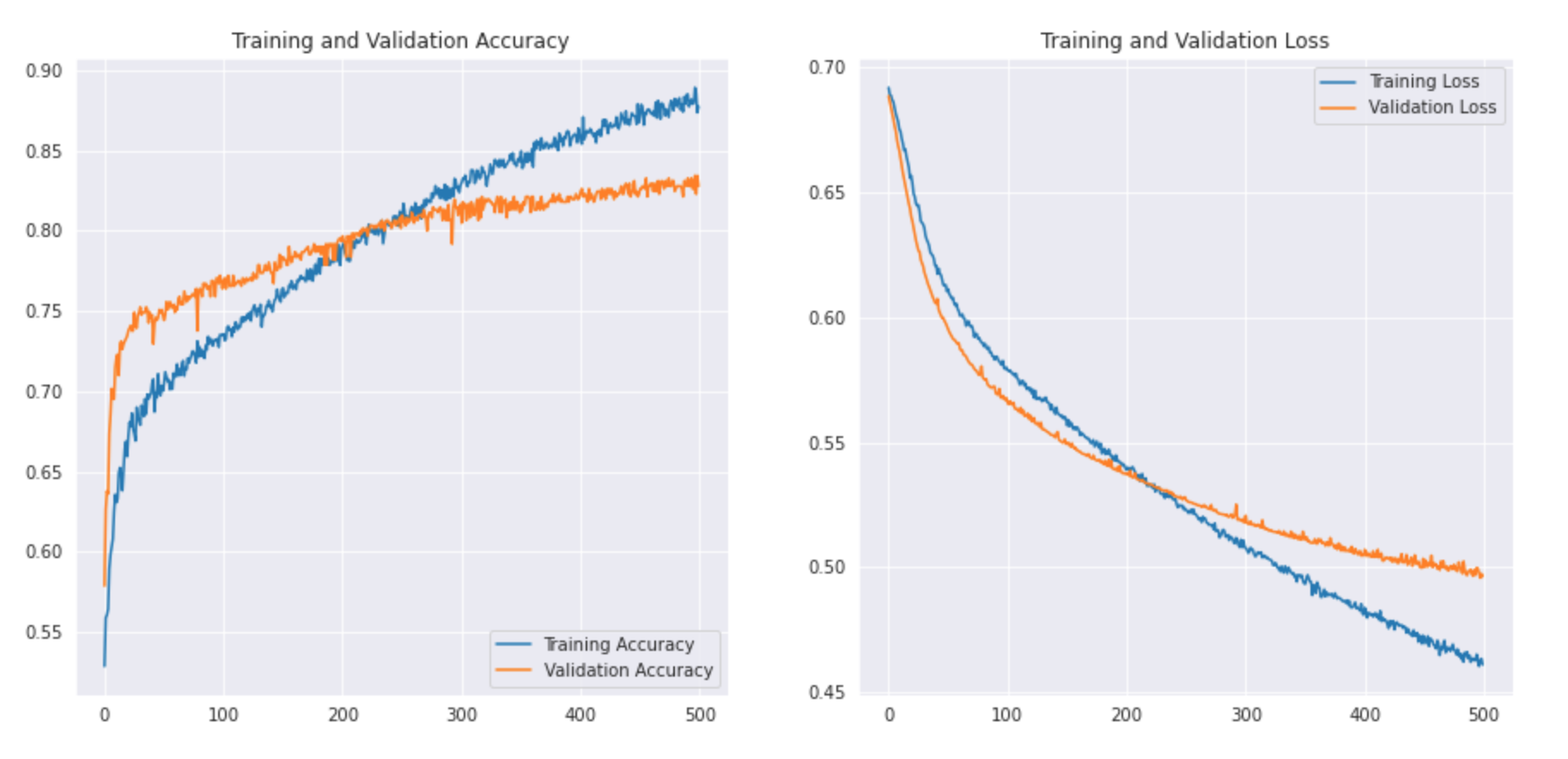
Podemos imprimir el informe de clasificación para ver la precisión y exactitud.
predictions = model.predict_classes(x_val) predictions = predictions.reshape(1,-1)[0] print(classification_report(y_val, predictions, target_names = ['Rugby (Class 0)','Soccer (Class 1)']))
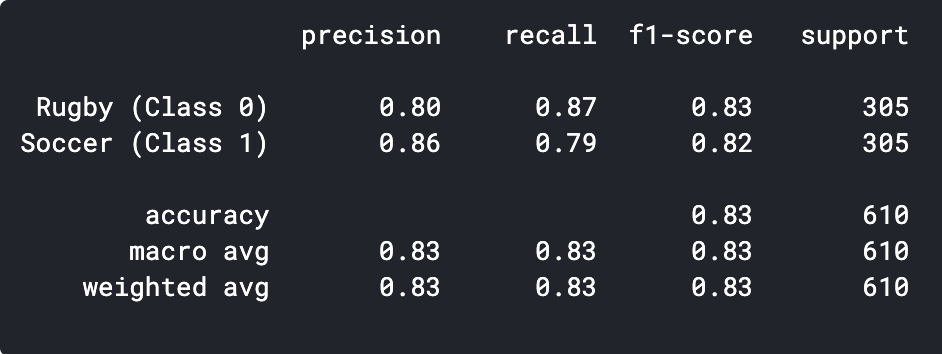
Como podemos ver, nuestro modelo simple de CNN fue capaz de lograr una precisión del 83%. Con algunos ajustes de hiperparámetros, podríamos lograr una precisión del 2-3%.
También podemos visualizar algunas de las imágenes predichas incorrectamente y ver dónde está fallando nuestro clasificador.
El arte del aprendizaje transferido
Veamos primero qué es el aprendizaje por transferencia. El aprendizaje por transferencia es una técnica de aprendizaje automático en la que un modelo entrenado en una tarea se reorienta en una segunda tarea relacionada. Otra aplicación crucial del aprendizaje por transferencia es cuando el conjunto de datos es pequeño, mediante el uso de un modelo previamente entrenado en imágenes similares podemos lograr fácilmente un alto rendimiento. Dado que nuestro planteamiento del problema es una buena opción para el aprendizaje por transferencia, veamos cómo podemos implementar un modelo previamente entrenado y qué precisión podemos lograr.
Paso 1: – Importar el modelo
Crearemos un modelo base a partir del modelo MobileNetV2. Esto está pre-entrenado en el conjunto de datos ImageNet, un gran conjunto de datos que consta de 1,4 millones de imágenes y 1000 clases. Esta base de conocimiento nos ayudará a clasificar el rugby y el fútbol a partir de nuestro conjunto de datos específico.
Al especificar el argumento include_top = False, carga una red que no incluye las capas de clasificación en la parte superior.
base_model = tf.keras.applications.MobileNetV2(input_shape = (224, 224, 3), include_top = False, weights = "imagenet")
Es importante congelar nuestra base antes de compilar y entrenar el modelo. La congelación evitará que los pesos de nuestro modelo base se actualicen durante el entrenamiento.
base_model.trainable = False
A continuación, definimos nuestro modelo usando nuestro base_model seguido de una función GlobalAveragePooling para convertir las características en un solo vector por imagen. Agregamos una deserción de 0.2 y la capa densaLa capa densa es una formación geológica que se caracteriza por su alta compacidad y resistencia. Comúnmente se encuentra en el subsuelo, donde actúa como una barrera al flujo de agua y otros fluidos. Su composición varía, pero suele incluir minerales pesados, lo que le confiere propiedades únicas. Esta capa es crucial en estudios de ingeniería geológica y recursos hídricos, ya que influye en la disponibilidad y calidad del agua... final con 2 neuronas y activación softmax.
model = tf.keras.Sequential([base_model, tf.keras.layers.GlobalAveragePooling2D(), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(2, activation="softmax") ])
A continuación, compilemos el modelo y comencemos a entrenarlo.
base_learning_rate = 0.00001 model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate), loss=tf.keras.losses.BinaryCrossentropy(from_logits=True), metrics=['accuracy']) history = model.fit(x_train,y_train,epochs = 500 , validation_data = (x_val, y_val))
Paso 2: – Evaluación del resultado.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(500)
plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc, label="Validation Accuracy")
plt.legend(loc="lower right")
plt.title('Training and Validation Accuracy')
plt.subplot(2, 2, 2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss, label="Validation Loss")
plt.legend(loc="upper right")
plt.title('Training and Validation Loss')
plt.show()
Veamos cómo se ve la curva: –
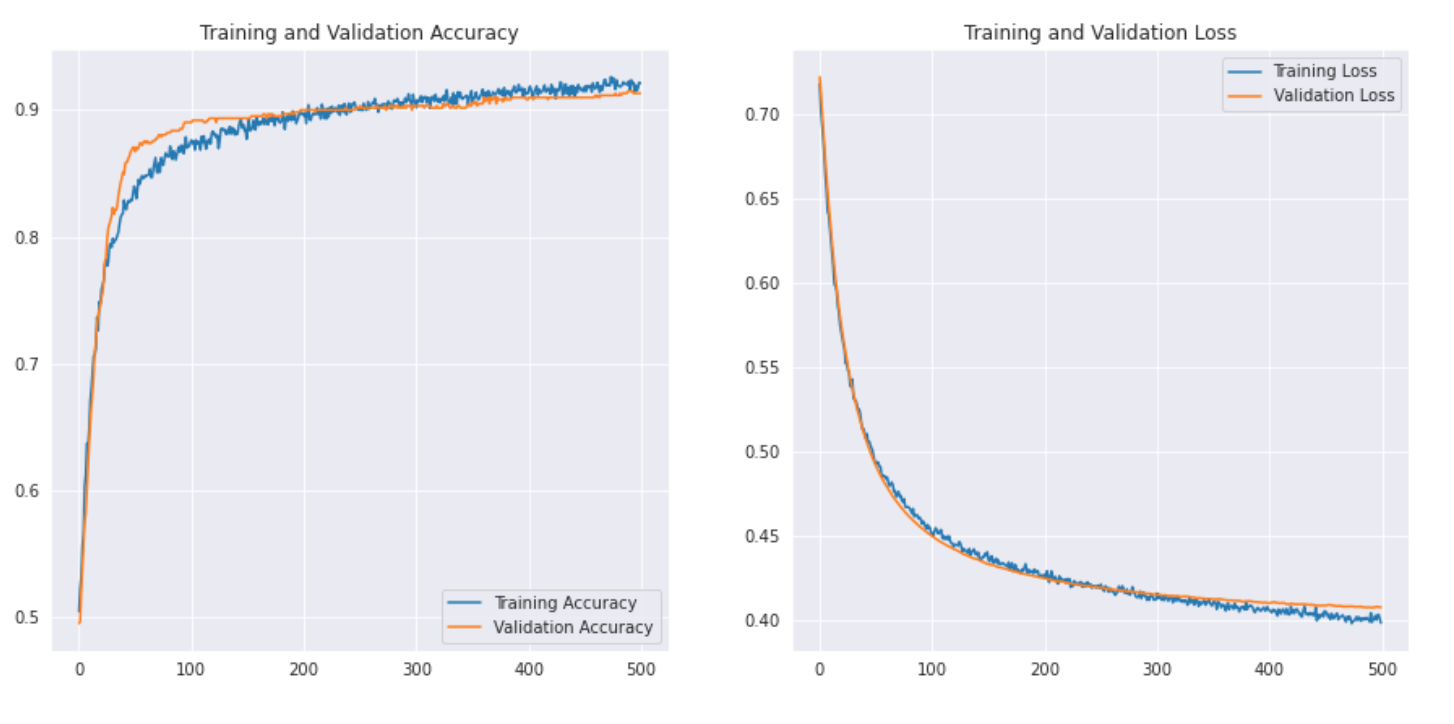
Imprimamos también el informe de clasificación para obtener resultados más detallados.
predictions = model.predict_classes(x_val) predictions = predictions.reshape(1,-1)[0] print(classification_report(y_val, predictions, target_names = ['Rugby (Class 0)','Soccer (Class 1)']))
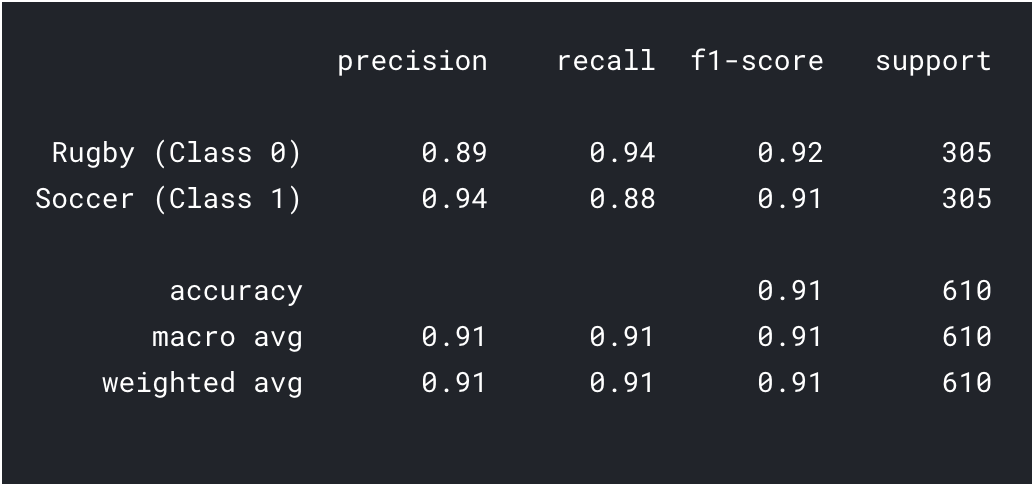
Como podemos ver con el aprendizaje por transferencia, pudimos obtener un resultado mucho mejor. Tanto la precisión de Rugby como de Fútbol son más altas que nuestro modelo de CNN y también la precisión general alcanzó el 91%, lo que es realmente bueno para un conjunto de datos tan pequeño. Con un poco de ajuste de hiperparámetros y cambios de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto...., ¡también podríamos lograr un rendimiento un poco mejor!
¿Que sigue?
Este es solo el punto de partida en el campo de la visión por computadora. De hecho, intente mejorar sus modelos básicos de CNN para igualar o superar el rendimiento de referencia.
- Puede aprender de las arquitecturas de VGG16, etc. para obtener algunas pistas sobre el ajuste de hiperparámetros.
- Puede usar el mismo ImageDataGenerator para aumentar sus imágenes y aumentar el tamaño del conjunto de datos.
- Además, puede intentar implementar arquitecturas más nuevas y mejores como DenseNet y XceptionNet.
- También puede pasar a otras tareas de visión por computadora, como la detección y segmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo.... de objetos, que luego se dará cuenta de que también se puede reducir a la clasificación de imágenes.
Notas finales
Enhorabuena, ha aprendido a crear un conjunto de datos propio y a crear un modelo de CNN oa realizar el aprendizaje por transferencia para resolver un problema. Aprendimos mucho en este artículo, desde aprender a buscar datos de imágenes hasta crear un modelo CNN simple que pudo lograr un rendimiento razonable. También aprendimos la aplicación del aprendizaje por transferencia para mejorar aún más nuestro desempeño.
Ese no es el final, vimos que nuestros modelos clasificaban erróneamente muchas imágenes, lo que significa que todavía hay margenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial... de mejora. Podríamos comenzar encontrando más datos o incluso implementando arquitecturas mejores y más recientes que podrían ser mejores para identificar las características.
¿Le ha resultado útil este artículo? Comparta sus valiosos comentarios en la sección de comentarios a continuación. No dude en compartir también sus cuadernos de códigos completos, que serán útiles para los miembros de nuestra comunidad.





