Visión general
- La guía paso a paso para desarrollar debe aprender habilidades para convertirse en un científico de datos
- Recursos como MOOC, canales de YouTube, páginas de blogs, sitios web de la comunidad de ciencia de datos para aprender diversas habilidades
- Sitios web de la comunidad de ciencia de datos como Kaggle, Driven Data, Analytics Vidhya para obtener experiencia práctica con conjuntos de datos y
otras técnicas útiles de aprendizaje automático
¿Qué es la ciencia de datos?
La ciencia de datos se trata «Utilizando varias técnicas, algoritmos para analizar grandes cantidades de conjuntos de datos (tanto estructurados como no estructurados), para extraer información útil sobre los datos, aplicándolos así en varios dominios comerciales».
¿Por qué hay demanda de científicos de datos?
Datos se genera día a día a un ritmo masivo y para procesar conjuntos de datos tan masivos, las grandes empresas están buscando buenos científicos de datos para extraer información valiosa de estos conjuntos de datos y usarlos para diversas estrategias, modelos y planes comerciales.
Tabla de contenido
- Aprende Python
- Aprender estadísticas
- Recopilación de datos
- Limpieza de datos
- Conocimiento de EDA (análisis de datos exploratorios)
- Aprendizaje automático y aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud...
- Más información sobre la implementación del modelo de AA
- Pruebas del mundo real
- Explorando y practicando conjuntos de datos en Kaggle, Analytics Vidhya
- Curiosidad analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico....
- Habilidades no técnicas

1. Aprende Python
El primer y principal paso hacia la ciencia de datos debe ser un lenguaje de programación (es decir, Python). Python es el lenguaje de codificación más común, utilizado por la mayoría de los científicos de datos, debido a su simplicidad, versatilidad y estar preequipado con bibliotecas poderosas (como NumPy, SciPy y Pandas) útiles en el análisis de datos y otros aspectos en Data Ciencias. Python es un lenguaje de código abierto y es compatible con varias bibliotecas.
Recurso:
MOOC: Curso de Udacity Python, Curso de Coursera Python
Canal de Youtube: Krish Naik, Conceptos básicos del código
Blogs: Analytics Vidhya, Nuggets de KD
2. Aprender estadísticas

Si La ciencia de datos es un lenguaje, luego la estadística es básicamente la gramática. La estadística es básicamente el método de análisis e interpretación de grandes conjuntos de datos. Cuando se trata de análisis de datos y recopilación de información, las estadísticas son tan notables como el aire para nosotros. Las estadísticas nos ayudan a comprender los detalles ocultos de grandes conjuntos de datos
Recurso:
MOOC: Curso de Estadística de Coursera
Canal de Youtube: Krish Naik, Conceptos básicos del código
Blogs: Analytics Vidhya, Nuggets de KD
3. Recopilación de datos
Este es uno de los pasos clave e importantes en el campo de la ciencia de datos. Esta habilidad implica el conocimiento de varias herramientas para importar datos de ambos sistemas locales, como archivos CSV, y extraer datos de sitios web, utilizando biblioteca de python de beautifulsoup. El desguace también puede basarse en API. La recopilación de datos se puede administrar con conocimiento de Query Language o canalizaciones ETL en Python
Recurso:
MOOC: Recopilación de datos de Coursera con Python
4. Limpieza de datos
Este es el paso en el que se dedica la mayor parte del tiempo como científico de datos. La limpieza de datos se trata de obtener los datos, aptos para realizar trabajos y análisis, mediante la eliminación de valores no deseados, valores perdidos, valores categóricos, valores atípicos y registros enviados incorrectamente, desde la forma sin procesar de los datos.. La limpieza de datos es muy importante ya que los datos del mundo real son desordenados por naturaleza y lograrlo con la ayuda de varias bibliotecas de Python (Pandas y NumPy) es realmente importante para un aspirante a científico de datos.
Recurso:
Blog: Blog sobre limpieza de datos con Python

5. Conocimiento de EDA (análisis de datos exploratorios)
EDA (análisis de datos exploratorios) es el aspecto más importante en el vasto campo de la ciencia de datos. Incluye analizar varios datos, variables, diversos patrones de datos, tendencias y extraer información útil de ellos con la ayuda de varios métodos gráficos y estadísticos. EDA identifica varios patrones que el algoritmo de aprendizaje automático podría no identificar. Incluye toda la manipulación, análisis y visualización de datos.
Recurso:
Comunidades de ciencia de datos: Kaggle, Analítica Vidhya
Blog: EDA en conjunto de datos de iris
Canal de YouTube: videos de EDA en Krish Naik, Conceptos básicos del código
MOOC: Curso de Coursera sobre EDA, estadística, probabilidad
6. Aprendizaje automático y aprendizaje profundo
El aprendizaje automático es la habilidad principal necesaria para ser un científico de datos. El aprendizaje automático se utiliza para construir varios modelos predictivos, modelos de clasificación, etc., y las grandes empresas, las empresas, lo utilizan para optimizar su planificación según las predicciones. Por ejemplo, predicción del precio del automóvil
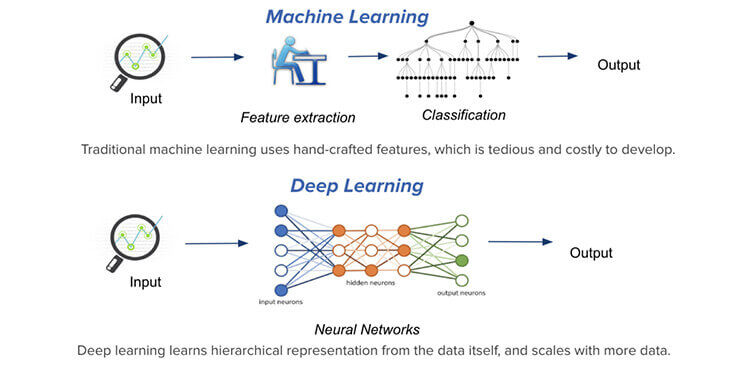
Deep Learning, por otro lado, es una versión avanzada de Machine Learning que implementa el uso de Neural Network, un marco que combina varios algoritmos de aprendizaje automático para resolver diversas tareas, para entrenar datos. Varias redes neuronales son una red neuronal recurrenteLas redes neuronales recurrentes (RNN) son un tipo de arquitectura de redes neuronales diseñadas para procesar secuencias de datos. A diferencia de las redes neuronales tradicionales, las RNN utilizan conexiones internas que permiten recordar información de entradas anteriores. Esto las hace especialmente útiles en tareas como el procesamiento de lenguaje natural, la traducción automática y el análisis de series temporales, donde el contexto y la secuencia son fundamentales para la... (RNN) o una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... (CNN), etc.
Por ejemplo: reconocimiento facial
Recursos:
Comunidades de ciencia de datos: Kaggle, Analítica Vidhya
Blog: Analytics Vidhya, Nuggets de KD
Canal de YouTube: videos en Krish Naik, Conceptos básicos del código
MOOC: Curso de Coursera Machine Learning, Especialización en aprendizaje profundo de Coursera
7. Aprenda a implementar el modelo de AA
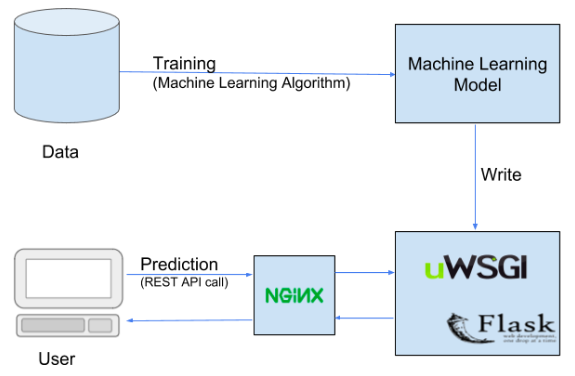
La implementación es básicamente el proceso de poner su modelo de aprendizaje automático a disposición de los usuarios finales para su uso. Esto se logra mediante la integración del modelo con varios entornos de producción existentes, implementando así el uso práctico del modelo ML para diversas soluciones comerciales.
Hay muchos servicios para implementar su modelo de ML como Flask, Pythoneverywhere, MLOps, Microsoft Azure, Google Cloud, Heroku, etc.
Recursos:
Canal de YouTube: videos de implementación de AA en Krish Naik, Conceptos básicos del código
Blogs: Analytics Vidhya, Nuggets de KD
8. Pruebas del mundo real
Se deben realizar pruebas y validación del modelo de aprendizaje automático después de la implementación para verificar su efectividad y precisión. Las pruebas son un paso importante en la ciencia de datos para mantener bajo control la eficiencia y la eficacia del modelo ML.
Hay varios tipos de pruebas como A / B, AAB Testing, etc.
9. Exploración y práctica de conjuntos de datos en Kaggle, Analytics Vidhya

Las comunidades de ciencia de datos más grandes del mundo como Kaggle, Analytics Vidhya es muy útil para ponerse en contacto con varios conjuntos de datos y, por lo tanto, se puede utilizar para practicar diversas técnicas de análisis de datos, algoritmos de aprendizaje automático. Los concursos que se llevan a cabo en estas comunidades también son útiles para mejorar las habilidades de la ciencia de datos, lo que nos ayuda a lograr nuestro objetivo de ser competentes en ciencia de datos más rápido..
10. Curiosidad analítica
El campo de la ciencia de datos es un campo que está evolucionando a un ritmo más rápido., por lo tanto, requiere una curiosidad innata para explorar más sobre el campo, actualizando y aprendiendo regularmente diversas habilidades y técnicas.
Esta es la habilidad principal que siempre nos ayudará a mantener, actualizar nuevas habilidades y conceptos, evitando así que nos quedemos atrás de varios avances tecnológicos de la ciencia de datos.
11. Habilidades no técnicas
No técnico incluye trabajo en equipo, habilidades de comunicación, gestión de tareas, comprensión empresarial, etc
Trabajo en equipo juega un papel importante al entregar el resultado a las empresas, empresas en las que trabajamos como científicos de datos.
Habilidades de comunicación nos permiten expresar nuestras ideas técnicas, conceptos a diversos funcionarios / autoridades no técnicas de la Firma.
Tarea Gestión implica una gestión y planificación adecuadas para la entrega de la solución.
Comprensión / perspicacia empresarial o la comprensión sobre la industria en la que estamos trabajando es muy importante para varios análisis y soluciones efectivas para los problemas en esas industrias.





