Introducción

Tabla de contenido
- ¿Por qué deberíamos utilizar la ingeniería de funciones en la ciencia de datos?
- Selección de características
- Manejo de valores perdidos
- Manejo de datos desequilibrados
- Manejo de valores atípicos
- Binning
- Codificación
- Escala de funciones
1. ¿Por qué deberíamos utilizar la ingeniería de funciones en la ciencia de datos?
En Data Science, el rendimiento del modelo depende del preprocesamiento y el manejo de datos. Supongamos que si construimos un modelo sin Manejo de datos, obtenemos una precisión de alrededor del 70%. Al aplicar la ingeniería de funciones en el mismo modelo, existe la posibilidad de aumentar el rendimiento del 70% a más.
Simplemente, al utilizar la ingeniería de funciones, mejoramos el rendimiento del modelo.
2. Selección de funciones
La selección de funciones no es más que una selección de funciones independientes necesarias. Seleccionar las características independientes importantes que tienen más relación con la característica dependiente ayudará a construir un buen modelo. Existen algunos métodos para la selección de funciones:
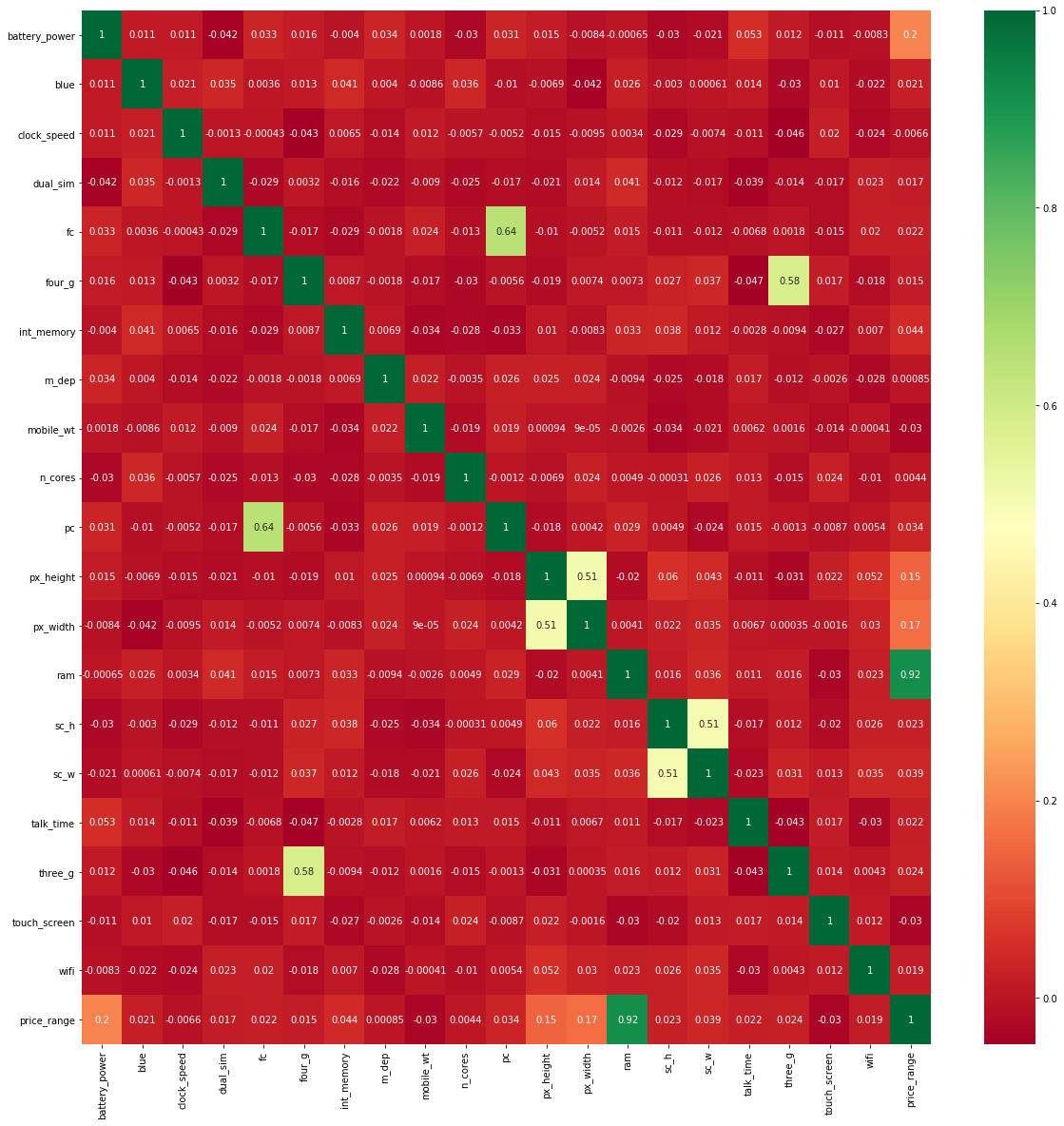
2.1 Matriz de correlación con mapa de calor
El mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas.... es una representación gráfica de datos 2D (bidimensionales). Cada valor de los datos se representa en una matriz.
En primer lugar, trace la gráfica de pares entre todas las características independientes y las características dependientes. Dará la relación entre características dependientes e independientes. La relación entre la característica independiente y la característica dependiente es menor que 0.2, luego elija esa característica independiente para construir un modelo.
2.2 Selección univariante
En esto, las pruebas estadísticas se pueden utilizar para seleccionar las características independientes que tienen la relación más fuerte con la característica dependiente. SeleccionarKBest El método se puede utilizar con un conjunto de diferentes pruebas estadísticas para seleccionar un número específico de características.
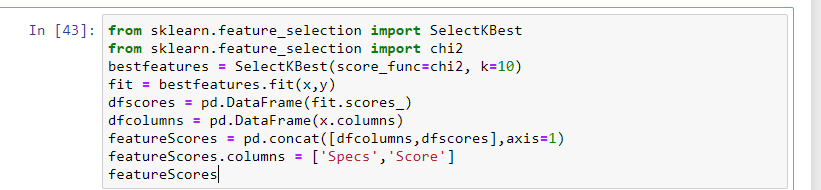
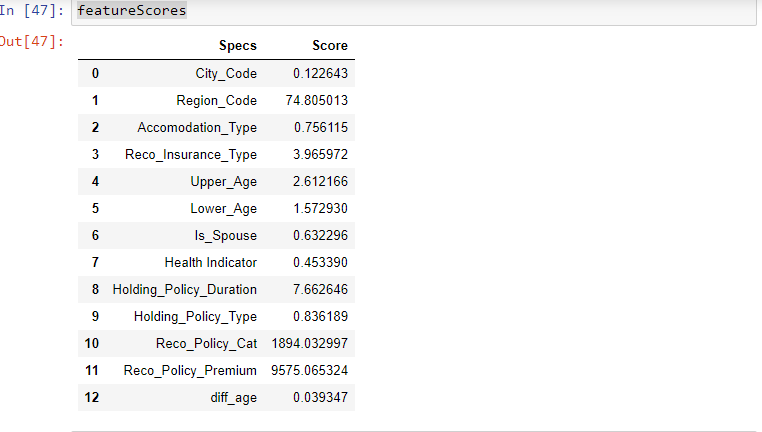
- La característica que tenga la puntuación más alta estará más relacionada con la característica dependiente y elija esas características para el modelo.
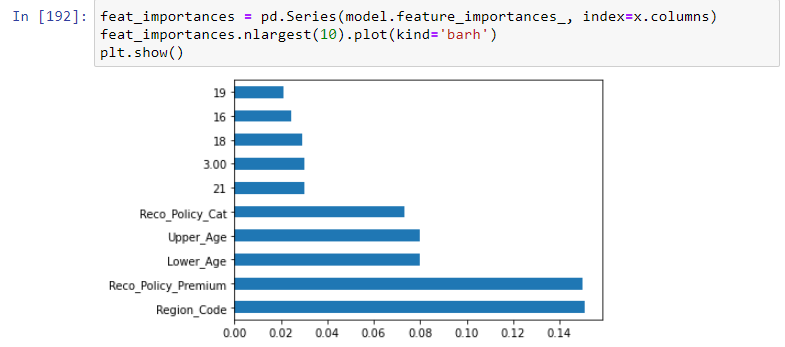
2.3 Método ExtraTreesClassifier
En este método, el método ExtraTreesClassifier ayudará a dar la importancia de cada característica independiente con una característica dependiente. La importancia de la función le dará una puntuación para cada función de sus datos, cuanto mayor sea la puntuación, más importante o relevante para la función con respecto a su variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de salida.

3. Manejo de valores perdidos
En algunos conjuntos de datos, obtuvimos los valores NA en las características. No son más que datos faltantes. Manejando este tipo de datos hay muchas formas:
- En los lugares de los valores perdidos, para reemplazar los valores perdidos con la media o medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... en los datos numéricos y para los datos categóricos con la moda.

- Elimina los valores de NA en filas enteras.

- Elimina los valores NA de características completas. (ayuda si los valores de NA son más del 50% en una función)

- Reemplaza los valores NA con 0.

Si elige descartar opciones, existe la posibilidad de perder información importante de ellas. Así que es mejor elegir reemplazar las opciones.
4. Manejo de datos desequilibrados
¿Por qué es necesario manejar datos desequilibrados? Debido a reducir el problema de sobreajuste y desajuste.
suponer una característica tiene un factor level2 (0 y 1). consta de 1 es 5% y 0 es 95%. Se llama datos desequilibrados.
Ejemplo:-

Para prevenir este problema, existen algunos métodos:
4.1 Clase mayoritaria submuestreada
Un submuestreo de la clase mayoritaria volverá a muestrear los puntos de la clase mayoritaria en los datos para hacerlos iguales a la clase minoritaria.

4.2 Clase de minoría de sobremuestreo por duplicación
El sobremuestreo de la clase minoritaria volverá a muestrear los puntos de la clase minoritaria en los datos para hacerlos iguales a la clase mayoritaria.

4.3 Sobremuestreo de la clase minoritaria utilizando la técnica de sobremuestreo de minorías sintéticas (SMOTE)
En este método, se generan muestras sintéticas para la clase minoritaria e iguales a la clase mayoritaria.

5. Manejo de valores atípicos
En primer lugar, calcule la asimetría de las características y compruebe si están sesgadas positivamente, negativamente o normalmente sesgadas. Otro método es trazar la gráfica de caja en las características y verificar si algún valor está fuera de los límites o no. si existen, se denominan valores atípicos.
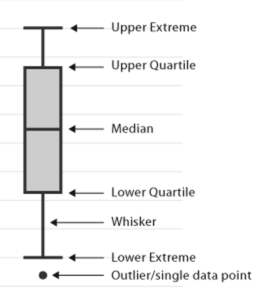
cómo manejar estos valores atípicos: –
Primero, calcule valores de cuantiles al 25% y 75%.

- a continuación, calcule el rango intercuartil
IQR = Q3 – Q1

- A continuación, calcule los valores de los extremos superior e inferior.
extremo inferior = Q1 – 1,5 * IQR
extremo superior = Q3– 1,5 * IQRe
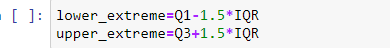
- por último, compruebe que los valores estén por encima del extremo superior o por debajo del extremo inferior. si se presenta, elimínelos o reemplácelos con la media, la mediana o cualquier valor de cuantil.
- Reemplazar valores atípicos con media

- Reemplazar valores atípicos con valores de cuantiles


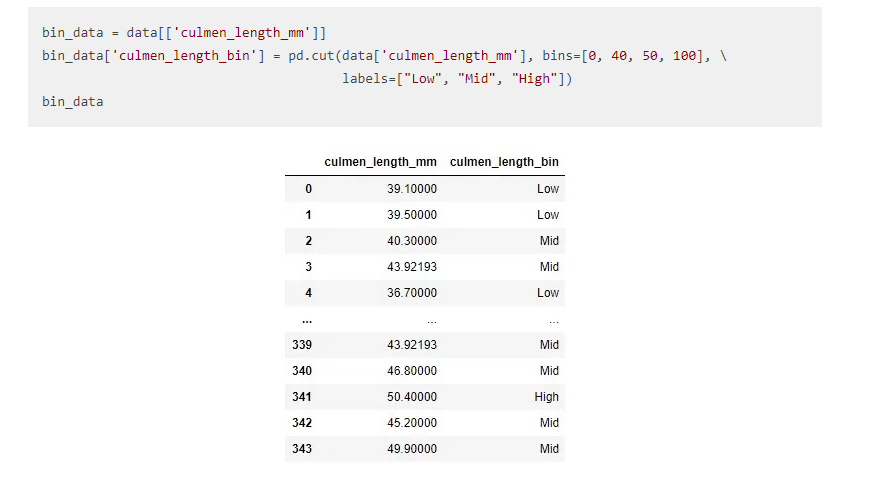
6. Binning
El binning no es más que cualquier valor de datos dentro del rango que se ajusta al bin. Es importante en su actividad de exploración de datos. Normalmente lo usamos para transformar variables continuas en discretas.
Supongamos que si tenemos la función AGE en forma continua y necesitamos dividir la edad en grupos como una función, entonces será útil.
7. Codificación:
¿Por qué se aplicará esto? porque en los conjuntos de datos podemos contener tipos de datos de objetos. para construir un modelo, necesitamos que todas las características estén en tipos de datos enteros. por lo tanto, Label Encoder y OneHotEncoder se utilizan para convertir el tipo de datos del objeto en un tipo de datos entero.

Antes de aplicar la codificación de etiquetas
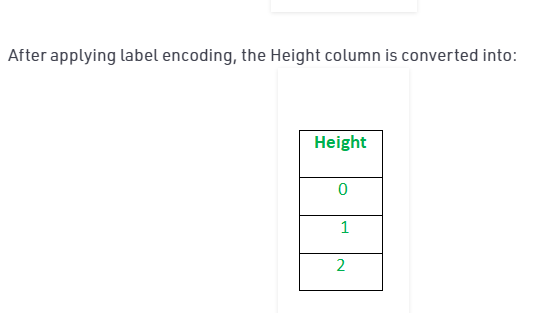
Después de aplicar la codificación de etiquetas, aplique el método de transformador de columna para convertir etiquetas a 0 y 1

Al aplicar get_dummies, convertimos directamente categórico a numérico

8. Escala de funciones
¿Por qué se aplica esta escala? porque para reducir el efecto de varianza y superar el problema de ajuste. hay dos tipos de métodos de escalado:
8.1 Estandarización
¿Cuándo se utiliza este método ?. cuando todas las características tienen valores altos, no 0 y 1.
Es una técnica para estandarizar las características independientes que se presentan en un rango fijo para llevar todos los valores a las mismas magnitudes.
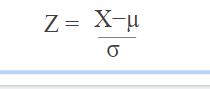
En la estandarización, la media de las características independientes es 0 y la desviación estándar es 1.
Método 1:

Método 2:

Después de codificar, las etiquetas de características están en 0 y 1. Esto puede afectar la estandarización. Para superar esto, usamos NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.....
8.2 Normalización
La normalización también hace que el proceso de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... sea menos sensible por la escala de las características. Esto da como resultado la obtención de mejores coeficientes después del entrenamiento.
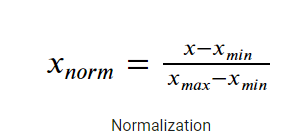
Método 1: -MinMaxScaler
Es un método para reescalar la característica a un rango rápido y estricto de [0,1] restando el valor mínimo de la característica y luego dividiendo por el rango.


Método 2: – Normalización media
Es un método para reescalar la característica a un rango rápido y estricto de [-1,1] con media = 0.
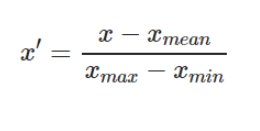


Notas finales: –
En este artículo, cubrí paso a paso el proceso de ingeniería de funciones. Esto es más útil para aumentar la precisión de la predicción.
Tenga en cuenta que no existen métodos particulares para aumentar la precisión de su predicción. Todo depende de sus datos y aplica múltiples métodos.
Como siguiente paso, te animo a que pruebes diferentes conjuntos de datos y los analices. ¡Y no olvide compartir sus ideas en la sección de comentarios a continuación!
Sobre el Autor:
Soy Pavan Kumar Reddy Elluru. Completé mi graduación en G.Pullareddy Engineering College en el año 2020. Soy un científico de datos certificado en el año 2021 y me apasiona el aprendizaje automático y los proyectos de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
Por favor, escríbame en caso de cualquier consulta o simplemente para decir hola.
Identificación de correo:- [email protected]
Identificación de Linkedin: – www.linkedin.com/in/elluru-pavan-kumar-reddy-a1b183197
ID de Github: – pawankumarreddy1999 (Pavan Kumar Reddy Elluru) (github.com)





