Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
«Es parte de la pasantía de editor de contenido»
«Cada vez que voy al cine, es mágico, sin importar de qué se trate». – Steven Spielberg
A todo el mundo le encantan las películas, independientemente de su edad, sexo, raza, color o ubicación geográfica. Todos, de alguna manera, estamos conectados entre nosotros a través de este increíble medio. Sin embargo, lo más interesante es el hecho de que único nuestras elecciones y combinaciones están en términos de preferencias de películas. A algunas personas les gustan las películas de género específico, ya sea de suspenso, romance o ciencia ficción, mientras que otras se centran en los actores principales y directores. Cuando tenemos todo eso en cuenta, es asombrosamente difícil generalizar una película y decir que a todo el mundo le gustaría. Pero con todo lo dicho, todavía se ve que películas similares son del agrado de una parte específica de la sociedad.
Así que aquí es donde nosotros, como científicos de datos, entramos en juego y extraemos el jugo de todos los patrones de comportamiento no solo de la audiencia sino también de las propias películas. Entonces, sin más preámbulos, vayamos directamente a los conceptos básicos de un sistema de recomendación.
¿Qué es un sistema de recomendación?
Simplemente ponga un Sistema de recomendación es un programa de filtrado cuyo objetivo principal es predecir la «calificación» o la «preferencia» de un usuario hacia un elemento o elemento específico del dominio. En nuestro caso, este elemento específico del dominio es una película, por lo tanto, el enfoque principal de nuestro sistema de recomendación es filtrar y predecir solo aquellas películas que un usuario preferiría dados algunos datos sobre el propio usuario.
-
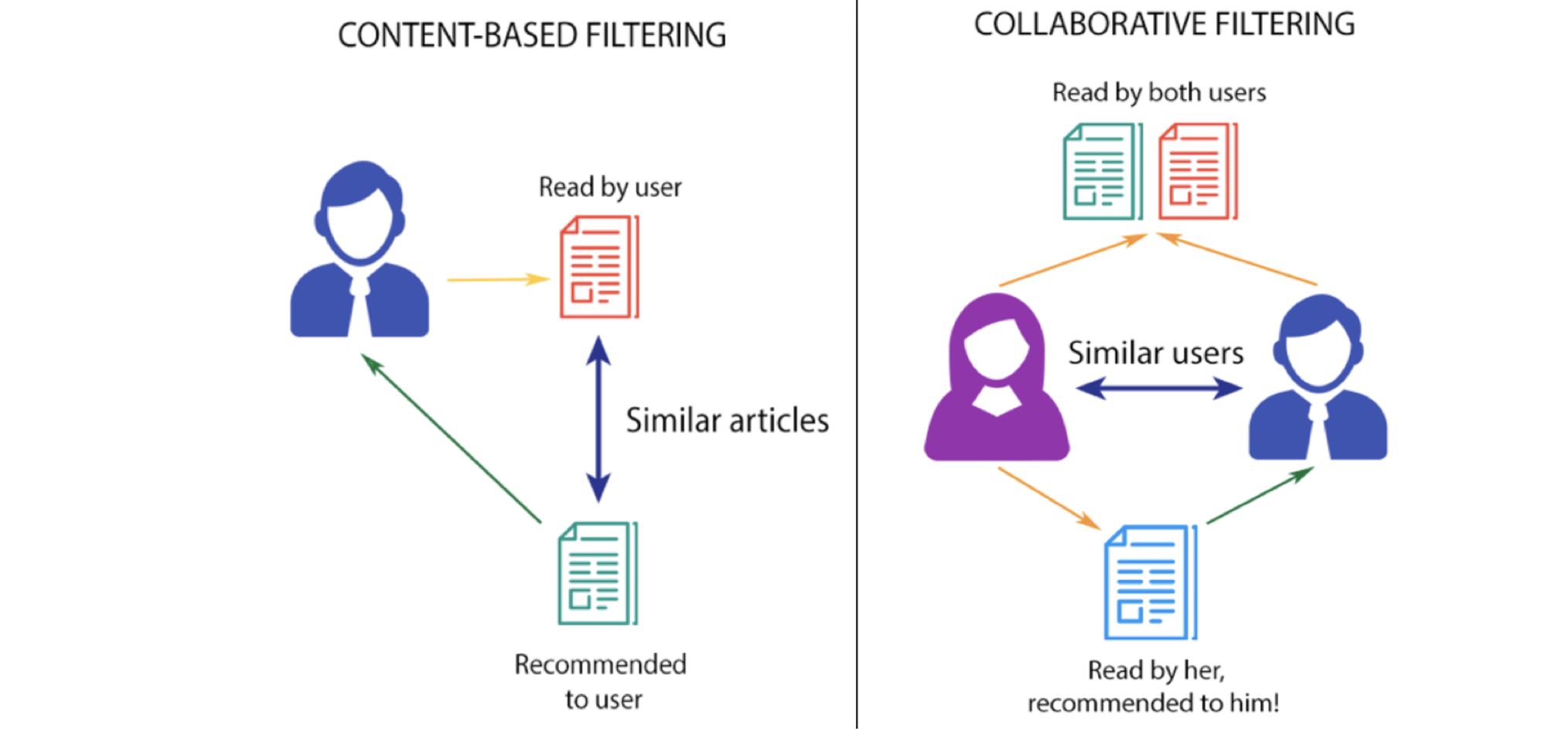
filtrado basado en contenido
Esta estrategia de filtrado se basa en los datos proporcionados sobre los artículos. El algoritmo recomienda productos que son similar a los que le ha gustado a un usuario en el pasado. Esta similitud (generalmente similitud de coseno) se calcula a partir de los datos que tenemos sobre los elementos, así como de las preferencias pasadas del usuario.
Por ejemplo, si a un usuario le gustan películas como ‘The Prestige’ entonces podemos recomendarle las películas de ‘Christian Bale’ o películas del género ‘Thriller’ o tal vez incluso películas dirigidas por ‘Christopher Nolan’. El sistema de recomendación comprueba las preferencias pasadas del usuario y encuentra la película «El prestigio», luego intenta encontrar películas similares a la que utiliza la información disponible en la base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos...., como los actores principales, el director, el género de la película, la casa de producción, etc y, basándose en esta información, busque películas similares a “The Prestige”.
Desventajas
- Los diferentes productos no obtienen mucho exposición al usuario.
- Los negocios no se pueden expandir porque el usuario no lo intenta diferentes tipos de productos.
-
Filtración colaborativa
Esta estrategia de filtración se basa en la combinación del comportamiento del usuario y compararlo y contrastarlo con otros usuarios comportamiento en la base de datos. La historia de todos los usuarios juega un papel importante en este algoritmo. La principal diferencia entre el filtrado basado en contenido y el filtrado colaborativo es que en este último, el interacción de todos los usuarios con los artículos influye en el algoritmo de recomendación, mientras que para el filtrado basado en contenido solo datos del usuario interesado es tomado en cuenta.
Hay varias formas de implementar el filtrado colaborativo, pero el concepto principal que se debe comprender es que en el filtrado colaborativo múltiple Los datos del usuario influyen en el resultado de la recomendación. y no depende de solo datos de un usuario para modelar.
Hay 2 tipos de algoritmos de filtrado colaborativo:
-
Filtrado colaborativo basado en el usuario
La idea básica aquí es encontrar usuarios que tengan patrones de preferencias anteriores similares como ha tenido el usuario ‘A’ y luego recomendarle elementos que le gusten a aquellos usuarios similares que ‘A’ aún no ha encontrado. Esto se logra haciendo un matriz de elementos que cada usuario ha calificado, visto, me gusta o ha hecho clic dependiendo de la tarea en cuestión, y luego calcular el puntaje de similitud entre los usuarios y finalmente recomendar elementos que el usuario en cuestión no conoce, pero que a usuarios similares a él / ella sí les gusta.
Por ejemplo, si al usuario ‘A’ le gustan ‘Batman Begins’, ‘Justice League’ y ‘The Avengers’ mientras que al usuario ‘B’ le gustan ‘Batman Begins’, ‘Justice League’ y ‘Thor’, entonces tienen intereses similares porque sabemos que estas películas pertenecen al género de superhéroes. Por lo tanto, existe una alta probabilidad de que al usuario ‘A’ le guste ‘Thor’ y al usuario ‘B’ le gusten Los Vengadores ‘.
Desventajas
- La gente es voluble es decir, su gusto cambia de vez en cuando y como este algoritmo se basa en la similitud del usuario, puede detectar patrones de similitud inicial entre 2 usuarios que después de un tiempo pueden tener preferencias completamente diferentes.
- Hay muchos más usuarios que elementos por lo tanto, resulta muy difícil mantener matrices tan grandes y, por lo tanto, es necesario volver a calcularlas con mucha regularidad.
- Este algoritmo es muy susceptible a ataques de chelín donde se utilizan perfiles de usuarios falsos que consisten en patrones de preferencias sesgados para manipular decisiones clave.
-
Filtrado colaborativo basado en elementos
El concepto en este caso es buscar películas similares en lugar de usuarios similares y luego recomendar películas similares a las que ‘A’ ha tenido en sus preferencias pasadas. Esto se ejecuta encontrando cada par de elementos que fueron calificados / vistos / les gustó / hizo clic por el mismo usuario, luego midiendo la similitud de aquellos calificados / vistos / gustados / cliqueados en todos los usuarios que calificaron / vieron / me gustaron / hicieron clic en ambos, y finalmente recomendándolos en función de las puntuaciones de similitud.
Aquí, por ejemplo, tomamos 2 películas ‘A’ y ‘B’ y verificamos sus calificaciones de todos los usuarios que han calificado ambas películas y basándonos en la similitud de estas calificaciones, y en base a esta similitud de calificación por parte de los usuarios que han calificado ambas encontramos películas similares. Entonces, si los usuarios más comunes han calificado ‘A’ y ‘B’ de manera similar y es muy probable que ‘A’ y ‘B’ sean similares, por lo tanto, si a alguien ha visto y le ha gustado ‘A’, se le debería recomendar ‘B’ y viceversa.
Ventajas sobre el filtrado colaborativo basado en el usuario
- A diferencia del gusto de la gente, las películas no cambian.
- Suelen haber muchas menos artículos que personas, por lo tanto, es más fácil mantener y calcular las matrices.
- Los ataques de chelín son mucho más difíciles porque los artículos no pueden ser falsificados.
-
Comencemos a codificar nuestro propio sistema de recomendación de películas.
En esta implementación, cuando el usuario busque una película, recomendaremos las 10 mejores películas similares utilizando nuestro sistema de recomendación de películas. Nosotros usaremos un filtrado colaborativo basado en elementos algoritmo para nuestro propósito. El conjunto de datos utilizado en esta demostración es el conjunto de datos movielens-small.
Poner los datos en funcionamiento
Primero, necesitamos importar bibliotecas que usaremos en nuestro sistema de recomendación de películas. Además, importaremos el conjunto de datos agregando la ruta del CSV archivos.
import pandas as pd import numpy as np from scipy.sparse import csr_matrix from sklearn.neighbors import NearestNeighbors import matplotlib.pyplot as plt import seaborn as sns movies = pd.read_csv("../input/movie-lens-small-latest-dataset/movies.csv") ratings = pd.read_csv("../input/movie-lens-small-latest-dataset/ratings.csv")
Ahora que hemos agregado los datos, echemos un vistazo a los archivos usando el dataframe.head () comando para imprimir las primeras 5 filas del conjunto de datos.
Echemos un vistazo al conjunto de datos de películas:
movies.head()
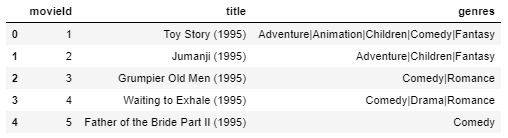
El conjunto de datos de la película tiene
- movieId: una vez que se realiza la recomendación, obtenemos una lista de todos los movieId similares y obtenemos el título de cada película de este conjunto de datos.
- géneros – que es no requerido para este enfoque de filtrado.
ratings.head()
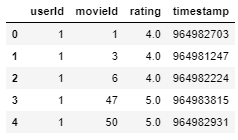
El conjunto de datos de calificaciones tiene
- userId: único para cada usuario.
- movieId: con esta función, tomamos el título de la película del conjunto de datos de películas.
- rating – Calificaciones otorgadas por cada usuario a todas las películas usando esto, vamos a predecir las 10 mejores películas similares.
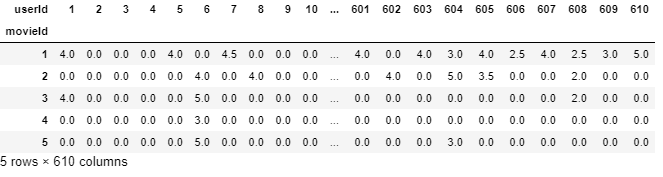
Aquí, podemos ver que userId 1 tiene Visto movieId 1 y 3 y ambos calificaron con 4.0, pero tiene no calificado movieId 2 en absoluto. Esta interpretación es más difícil para extraer de este marco de datos. Por lo tanto, para hacer las cosas más fáciles de entender y trabajar, vamos a crear un nuevo marco de datos donde cada columna representaría cada ID de usuario único y cada fila representaría cada ID de película único.
final_dataset = ratings.pivot(index='movieId',columns="userId",values="rating") final_dataset.head()
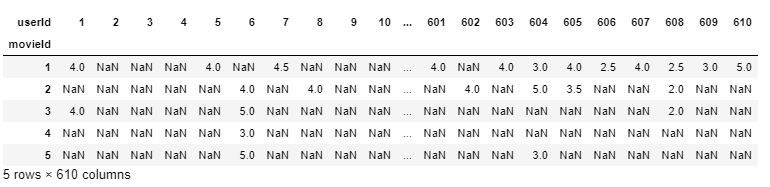
Ahora, es mucho más fácil interpretar que userId 1 ha calificado movieId 1 & 3 4.0 pero no ha calificado movieId 3,4,5 en absoluto (por lo tanto, se representan como NaN) y, por lo tanto, faltan sus datos de calificación.
Arreglemos esto y imputar NaN con 0 para hacer las cosas comprensibles para el algoritmo y también hacer que los datos sean más tranquilizadores para la vista.
final_dataset.fillna(0,inplace=True) final_dataset.head()
Eliminar ruido de los datos
En el mundo real, las calificaciones son muy escaso y los puntos de datos se recopilan principalmente de muy películas populares y usuarios muy comprometidos. No queremos películas que hayan sido calificadas por un número reducido de usuarios porque es no creíble suficiente. Del mismo modo, los usuarios que han calificado solo un puñado de películas tampoco debe tenerse en cuenta.
Entonces, con todo eso tomado en cuenta y algunos experimentos de prueba y error, reduciremos el ruido agregando algunos filtros para el conjunto de datos final.
- Para calificar una película, un mínimo de 10 los usuarios deberían haber votado una película.
- Para calificar a un usuario, un mínimo de 50 las películas deberían haber votado por el usuario.
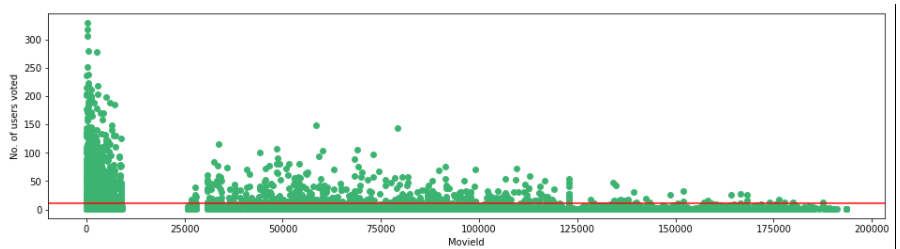
Visualicemos cómo se ven estos filtros
Sumando el número de usuarios que votaron y el número de películas que se votaron.
no_user_voted = ratings.groupby('movieId')['rating'].agg('count')
no_movies_voted = ratings.groupby('userId')['rating'].agg('count')
Visualicemos la cantidad de usuarios que votaron con nuestro umbral de 10.
f,ax = plt.subplots(1,1,figsize=(16,4))
# ratings['rating'].plot(kind='hist')
plt.scatter(no_user_voted.index,no_user_voted,color="mediumseagreen")
plt.axhline(y=10,color="r")
plt.xlabel('MovieId')
plt.ylabel('No. of users voted')
plt.show()
Realizar las modificaciones necesarias según el umbral establecido.
final_dataset = final_dataset.loc[no_user_voted[no_user_voted > 10].index,:]
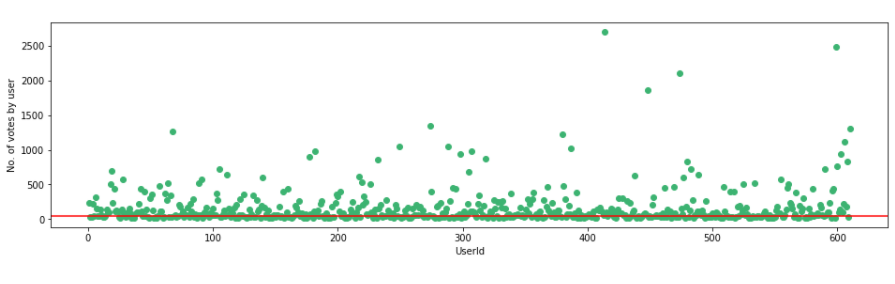
Visualicemos el número de votos de cada usuario con nuestro umbral de 50.
f,ax = plt.subplots(1,1,figsize=(16,4))
plt.scatter(no_movies_voted.index,no_movies_voted,color="mediumseagreen")
plt.axhline(y=50,color="r")
plt.xlabel('UserId')
plt.ylabel('No. of votes by user')
plt.show()
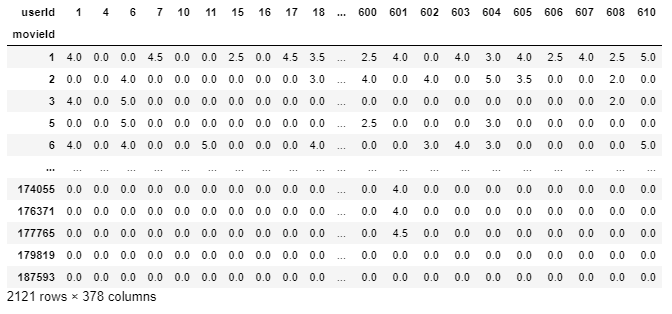
Realización de las modificaciones necesarias según el umbral establecido.
final_dataset=final_dataset.loc[:,no_movies_voted[no_movies_voted > 50].index] final_dataset
Eliminar la escasez
Nuestro final_dataset tiene dimensiones de 2121 * 378 donde la mayoría de los valores son escasos. Estamos usando solo un pequeño conjunto de datos, pero para el gran conjunto de datos original de lentes de película que tiene más de 100000 características, nuestro sistema puede quedarse sin recursos computacionales cuando se alimentan al modelo. Para reducir la dispersión usamos la función csr_matrix de la biblioteca scipy.
Daré un ejemplo de cómo funciona:
sample = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]]) sparsity = 1.0 - ( np.count_nonzero(sample) / float(sample.size) ) print(sparsity)

csr_sample = csr_matrix(sample) print(csr_sample)

Como puede ver, no hay un valor escaso en csr_sample y los valores se asignan como índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de filas y columnas. para la fila 0 y la segunda columna, el valor es 3.
Aplicando el método csr_matrix al conjunto de datos:
csr_data = csr_matrix(final_dataset.values) final_dataset.reset_index(inplace=True)
Hacer el modelo del sistema de recomendación de películas
Usaremos el algoritmo KNN para calcular la similitud con distancia coseno métrica que es muy rápida y más preferible que coeficiente de pearson.
knn = NearestNeighbors(metric="cosine", algorithm='brute', n_neighbors=20, n_jobs=-1) knn.fit(csr_data)
Haciendo la función de recomendación
El principio de funcionamiento es muy sencillo. Primero comprobamos si la entrada del nombre de la película está en la base de datos y si lo es usamos nuestro sistema de recomendaciones para encontrar películas similares y ordenarlos en función de su distancia de similitud y generar solo el top 10 películas con sus distancias de la película de entrada.
def get_movie_recommendation(movie_name):
n_movies_to_reccomend = 10
movie_list = movies[movies['title'].str.contains(movie_name)]
if len(movie_list):
movie_idx= movie_list.iloc[0]['movieId']
movie_idx = final_dataset[final_dataset['movieId'] == movie_idx].index[0]
distances , indices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1)
rec_movie_indices = sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda x: x[1])[:0:-1]
recommend_frame = []
for val in rec_movie_indices:
movie_idx = final_dataset.iloc[val[0]]['movieId']
idx = movies[movies['movieId'] == movie_idx].index
recommend_frame.append({'Title':movies.iloc[idx]['title'].values[0],'Distance':val[1]})
df = pd.DataFrame(recommend_frame,index=range(1,n_movies_to_reccomend+1))
return df
else:
return "No movies found. Please check your input"
¡Finalmente, recomendaremos algunas películas!
get_movie_recommendation('Iron Man')
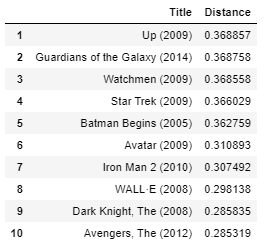
Personalmente, creo que los resultados son bastante buenos. Todas las películas en la parte superior son superhéroe o animación películas que son ideales para niños como es la película de entrada «Iron Man».
Probemos con otro:
get_movie_recommendation('Memento')
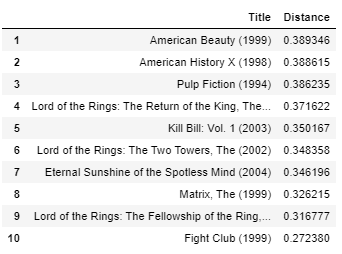
Todas las películas del top 10 son serio y consciente películas como “Memento” en sí, por lo que creo que el resultado, en este caso, también es bueno.
Nuestro modelo funciona bastante bien: un sistema de recomendación de películas basado en el comportamiento del usuario. Por lo tanto, concluimos nuestro filtrado colaborativo aquí. Puede obtener el cuaderno de implementación completo aquí.





