Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Visión general
- Cada componente básico y fundamental que se requiere para el análisis de sentimientos.
- He utilizado un enfoque sencillo para explicar todos los conceptos básicos, de modo que incluso un lector principiante pueda obtener una comprensión completa de todos los conceptos.
- Temas: Preprocesamiento de texto, Corpus de vocabulario, Extracción de características (Representación dispersa y Diccionario de frecuencias), Modelo de regresión logística para análisis de sentimientos.
El análisis de sentimientos es una técnica supervisada de aprendizaje automático que se utiliza para analizar y predecir la polaridad de los sentimientos dentro de un texto (ya sea positivo o negativo).
A menudo es utilizado por empresas y empresas para comprender la experiencia de sus usuarios, emociones, respuestas, etc. para que puedan mejorar la calidad y flexibilidad de sus productos y servicios.
Ahora, profundicemos en la comprensión de cómo los ingenieros de aprendizaje automático utilizan esta técnica de análisis de sentimientos para examinar los sentimientos de varios textos.
Reuniendo datos
”¡MÁS DATOS, MEJOR! «
Hay tantas fuentes de datos abiertas que se pueden usar para entrenar modelos de AA, por lo que es una elección personal recopilar datos usted mismo o usar conjuntos de datos abiertos para entrenar nuestro algoritmo.
Los conjuntos de datos basados en texto se distribuyen generalmente como JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software... o CSV formatos, por lo que para usarlos, podemos recuperar los datos en una lista de Python o en un diccionario / objeto de marco de datos.
Los datos deben dividirse en el tren, la validación y los conjuntos de prueba de una manera común de 60% 20% 20% o 70% 15% 15%.
El popular conjunto de datos de Twitter se puede descargar desde aquí.
Tubería
Cada tarea de Machine Learning debe tener un PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, por ejemplo, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los.... Las canalizaciones se utilizan para dividir sus flujos de trabajo de aprendizaje automático en partes modulares independientes, reutilizables que luego se pueden canalizar juntas para mejorar continuamente la precisión del modelo y lograr un algoritmo exitoso.
Seguiremos una estructura de canalización básica para nuestro problema, de modo que un lector pueda comprender fácilmente cada parte de la canalización utilizada en nuestro flujo de trabajo. Nuestro pipeline incluirá los siguientes pasos:
- Procesamiento previo de texto y construcción de vocabulario: Eliminación de textos no deseados (palabras vacías), puntuación, URLs, identificadores, etc. que no tengan ningún valor sentimental. Y luego agregar palabras únicas preprocesadas a un vocabulario.
- Extracción de características: Iterando a través de cada ejemplo de datos para extraer características usando un diccionario de frecuencia y finalmente crear una matriz de características.
- Modelo de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....: Luego usaremos nuestra matriz de características para entrenar un modelo de regresión logística con el fin de usar ese modelo para predecir sentimientos.
- Modelo de prueba: Uso de nuestro modelo entrenado para obtener las predicciones de datos que nunca vio.
Procesamiento previo de datos
Es un paso importante en nuestra cartera de proyectos. El preprocesamiento de texto se puede utilizar para eliminar las palabras y las puntuaciones de los datos de texto que no tienen ningún valor sentimental, ya que el preprocesamiento de texto puede mejorar significativamente nuestro tiempo de entrenamiento, ya que el tamaño de nuestros datos se reducirá y se limitará a las palabras que tengan algún valor sentimental. El preprocesamiento incluye el manejo de
-
Para las palabras
Palabras que no tienen ningún valor / peso semántico o sentimental en una oración. por ejemplo: y, es, el, usted, etc.
¿Cómo procesarlos? Crearemos una lista que incluya todas las posibles palabras vacías como
[‘ourselves’, ‘hers’, ‘between’, ‘yourself’, ‘but’, ‘again’, ‘there’, ‘about’, ‘once’, ‘during’, ‘out’, ‘very’, ‘having’, ‘with’, ‘they’, ‘own’, ‘an’, ‘be’, ‘some’, ‘for’, ‘do’, ‘its’, ‘yours’, ‘such’, ‘into’, ‘of’, ‘most’, ‘itself’, ‘other’, ‘off’, ‘is’, ‘s’, ‘am’, ‘or’, ‘who’, ‘as’, ‘from’, ‘him’, ‘each’, ‘the’, ‘themselves’, ‘until’, ‘below’, ‘are’, ‘we’, ‘these’, ‘your’, ‘his’, ‘through’, ‘don’, ‘nor’, ‘me’, ‘were’, ‘her’, ‘more’, ‘himself’, ‘this’, ‘down’, ‘should’, ‘our’, ‘their’, ‘while’, ‘above’, ‘both’, ‘up’, ‘to’, ‘ours’, ‘had’, ‘she’, ‘all’, ‘no’, ‘when’, ‘at’, ‘any’, ‘before’, ‘them’, ‘same’, ‘and’, ‘been’, ‘have’, ‘in’, ‘will’, ‘on’, ‘does’, ‘yourselves’, ‘then’, ‘that’, ‘because’, ‘what’, ‘over’, ‘why’, ‘so’, ‘can’, ‘did’, ‘not’, ‘now’, ‘under’, ‘he’, ‘you’, ‘herself’, ‘has’, ‘just’, ‘where’, ‘too’, ‘only’, ‘myself’, ‘which’, ‘those’, ‘i’, ‘after’, ‘few’, ‘whom’, ‘t’, ‘being’, ‘if’, ‘theirs’, ‘my’, ‘against’, ‘a’, ‘by’, ‘doing’, ‘it’, ‘how’, ‘further’, ‘was’, ‘here’, ‘than’]
Ahora iteraremos a través de cada ejemplo en nuestros datos y eliminaremos cada palabra de nuestros datos que esté presente en la lista de palabras vacías.
-
Puntuaciones
Los signos de puntuación son símbolos que usamos para enfatizar nuestro texto. por ejemplo:! , @, #, $, etc.
¿Cómo procesarlos? Los procesaremos de manera similar a como hemos procesado las palabras vacías, crearemos una lista de ellos y procesaremos cada ejemplo con esa lista.
-
URL y identificadores
Las URL son los enlaces que comienzan con la declaración del protocolo Http, por ejemplo. ‘https: //….’ y los identificadores se utilizan para mencionar personas en las redes sociales, por ejemplo. ‘@usuario’ ambos comparten un significado sentimental nulo.
¿Cómo procesarlos? Procéselos creando alguna función ‘process_handles_urls ()’ que tomará los datos de nuestro tren y eliminará las palabras que comiencen con ‘https: //’ o ‘@’ de cada ejemplo.
-
Derivado
La derivación es un proceso de reducción de una palabra a su palabra raíz base. Por ejemplo, ‘turn’ es una palabra raíz de turn, turn, turn, etc. Dado que la palabra raíz ofrece el mismo valor sentimental para todas sus palabras con sufijo, podemos reducir cada palabra a su raíz base, lo que puede reducir el tamaño de nuestro vocabulario y el tiempo de entrenamiento. así como.
¿Cómo procesarlos? Procéselos creando alguna función ‘do_stemming ()’ que tomará los datos y derivará las palabras de cada ejemplo.
-
Carcasa inferior
Debemos usar mayúsculas y minúsculas similares para cada palabra en los datos para representar ‘Word’, ‘WORD’, ‘word’ solo debe haber un caso a seguir, es decir, minúsculas, esto también puede ayudar a reducir el tamaño del vocabulario y eliminar la repetición de palabras.
¿Cómo procesarlos? iterar a través de cada ejemplo, use el método .lower () para convertir cada fragmento de texto en minúsculas.
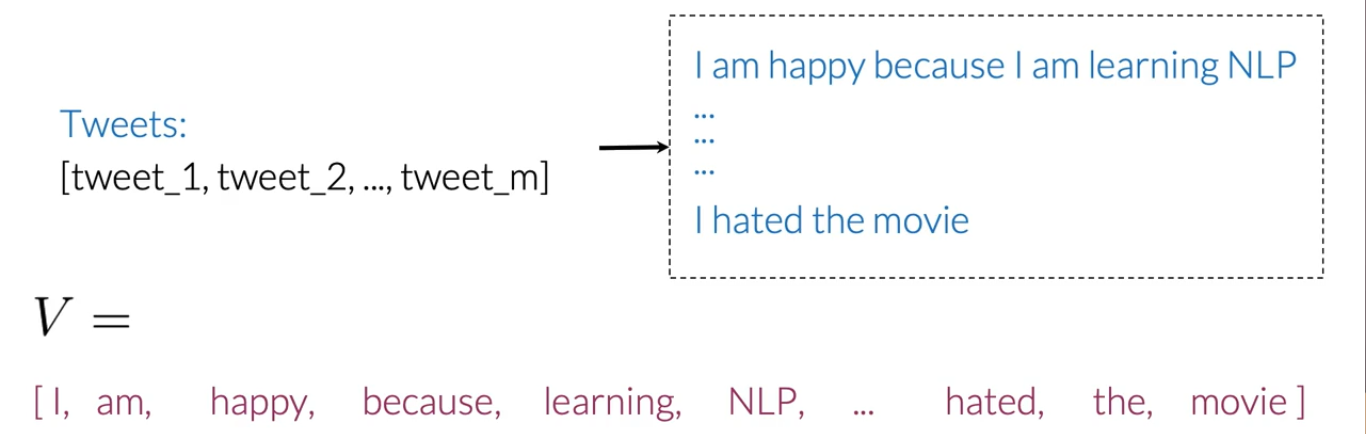
Corpus de vocabulario
Después de preprocesar los datos, es hora de crear un vocabulario que almacene cada palabra única y asigne algún valor numérico a cada palabra distinta (esto también se denomina tokenización).
Usaremos este diccionario de vocabulario para la extracción de características.
Extracción de características
Uno de los problemas, al trabajar con el procesamiento del lenguaje, es que los algoritmos de aprendizaje automático no pueden trabajar directamente en el texto sin procesar. Entonces, necesitamos algunas técnicas de extracción de características para convertir texto en una matriz (o vector) de características numéricas.
Tomemos algunos ejemplos de tweets positivos y negativos:

NOTE: The above example is not processed so we'll process it first before moving on to further steps.
Representación escasa
Es un enfoque ingenuo para extraer características de un texto. De acuerdo con la representación dispersa, podemos crear una matriz de características iterando a través de datos completos, y para cada palabra, en el ejemplo de texto asignaremos 1 en la posición de esa palabra en la lista de vocabulario y para las palabras que no ocurren, nosotros ‘ Asignaré 0. Entonces, nuestra matriz de características tendrá filas = oraciones totales en nuestros datos y columnas = palabras totales en el vocabulario.

Desventajas:
- Gran tiempo de entrenamiento
- Gran tiempo de predicción
Diccionario de frecuencia
Un diccionario de frecuencia realiza un seguimiento de las frecuencias positivas y negativas de cada palabra en nuestros datos.

Frecuencia positiva: los Número de veces que aparece una palabra en oraciones con sentimiento positivo.
Frecuencia negativa: los Número de veces que aparece una palabra en oraciones con sentimiento negativo.
Extracción de características con diccionario de frecuencia:
Usando el Diccionario de frecuencia para la extracción de características, podemos reducir las dimensiones de cada fila que representa cada oración de una matriz de características (es decir, igual al número de palabras en el vocabulario en caso de representación escasa) a tres dimensiones.
Las características de los datos de un texto se extraen con el diccionario de características utilizando las siguientes fórmulas:

El proceso casi se parece a:


Ahora tenemos un vector de características tridimensional para nuestro tweet que se ve así:
Xm = [1,8,11]
Ahora iteraremos a través de cada ejemplo para extraer características de cada ejemplo y luego usaremos esas características para crear la matriz de características que podemos usar para el entrenamiento. Al final, tenemos una matriz de características como:

Regresión logística para análisis de sentimientos
La regresión logística modela las probabilidades de problemas de clasificación con dos posibles resultados. Es una extensión del modelo de regresión lineal para problemas de clasificación.
Usos de regresión logística una función sigmoidea para mapear la salida de nuestra función lineal (θTx) entre 0 y 1 con algún umbral (generalmente 0.5) para diferenciar entre dos clases, de modo que si h> 0.5 es una clase positiva, y si h <0.5 es una clase negativa. (Explicar la regresión logística completa está más allá del alcance de este artículo)

Modelo de análisis de sentimiento de formación
El entrenamiento de nuestro modelo seguirá los siguientes pasos:
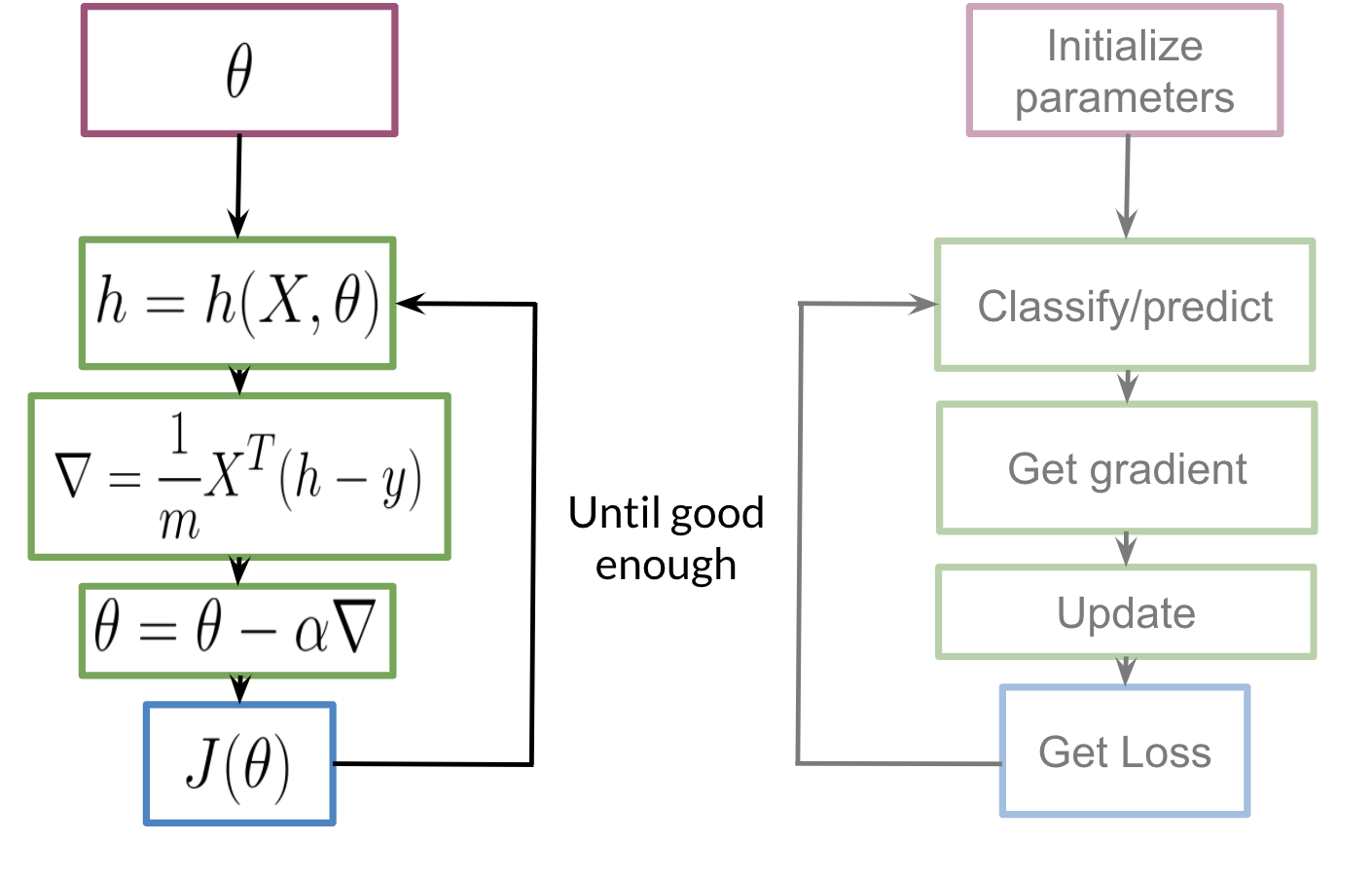
Inicializamos nuestro parámetro θ, que podemos usar en nuestro sigmoide, luego calculamos el gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... que usaremos para actualizar θ y luego calculamos el costo. Seguiremos repitiendo los pasos hasta que el costo se minimice / converja.
Probando nuestro modelo
Para probar nuestro modelo usaremos nuestro conjunto de validación y seguiremos los siguientes pasos:
- Divida los datos en X_validation (texto) e Y_validation (sentimiento).
- Utilice la extracción de características para X_validation para transformar textos en características numéricas.
- Encuentre el vector h (= sigmoide (θTX)) para cada texto del conjunto de validación.
- Asigne alguna función para obtener las clases reales mientras se compara con un umbral.
- Encuentre la precisión de nuestras predicciones.

Resumen
¡Me alegro de que hayas llegado hasta aquí! Si eres un principiante en el procesamiento del lenguaje natural, espero poder darte una idea de cómo funcionan las cosas debajo del capó y hacerte capaz de cubrir más temas más complejos y avanzados y, si eres un profesional, espero poder pudo repasar sus conceptos básicos.
El procesamiento del lenguaje natural es un vasto dominio de la inteligencia artificial, sus aplicaciones se utilizan en varios paradigmas, como chatbots, análisis de sentimientos, traducción automática, autocorrección, etc. Hay varias plataformas de e-learning y artículos, trabajos, etc. de distribución gratuita que pueden ser útiles para avanzar más en el viaje.
Referencias: Especialización en procesamiento de lenguaje natural





