Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Detección de anomalías de series temporales
Todo el proceso de detección de anomalías para una serie temporalUna serie temporal es un conjunto de datos recogidos o medidos en momentos sucesivos, generalmente en intervalos de tiempo regulares. Este tipo de análisis permite identificar patrones, tendencias y ciclos en los datos a lo largo del tiempo. Su aplicación es amplia, abarcando áreas como la economía, la meteorología y la salud pública, facilitando la predicción y la toma de decisiones basadas en información histórica.... se lleva a cabo en 3 pasos:
- Descomponer la serie de tiempo en las variables subyacentes; Tendencia, estacionalidad, residuo.
- Cree umbrales superior e inferior con algún valor de umbral
- Identifique los puntos de datos que están fuera de los umbrales como anomalías.
Caso de estudio
Descarguemos el conjunto de datos del sitio web del gobierno de Singapur que es de fácil acceso. Consumo total de electricidad en los hogares por tipo de vivienda. El sitio web de datos del gobierno de Singapur se cae con bastante facilidad. Este conjunto de datos muestra el consumo total de electricidad de los hogares por tipo de vivienda (en GWh).
Gestionado por la Autoridad del Mercado de la Energía
Frecuencia Anual
Fuente (s) Autoridad del Mercado de Energía
Licencia Licencia de datos abiertos de Singapur
Instalar y cargar paquetes R
En este ejercicio, trabajaremos con 2 paquetes clave para la detección de anomalías de series temporales en R: anómalo y timetk. Estos requieren que el objeto se cree como un tibble de tiempo, por lo que también cargaremos los paquetes de tibble. Primero instalemos y carguemos estas bibliotecas.
pkg <- c('tidyverse','tibbletime','anomalize','timetk')
install.packages(pkg)
library(tidyverse)
library(tibbletime)
library(anomalize)
library(timetk)
Cargar datos
En el paso anterior, hemos descargado el archivo de consumo total de electricidad por tipo de vivienda (en GWh) del sitio web del Gobierno de Singapur. Carguemos el archivo CSV en un marco de datos R.
df <- read.csv("C:Anomaly Detection in Rtotal-household-electricity-consumption.csv")
head(df,5)
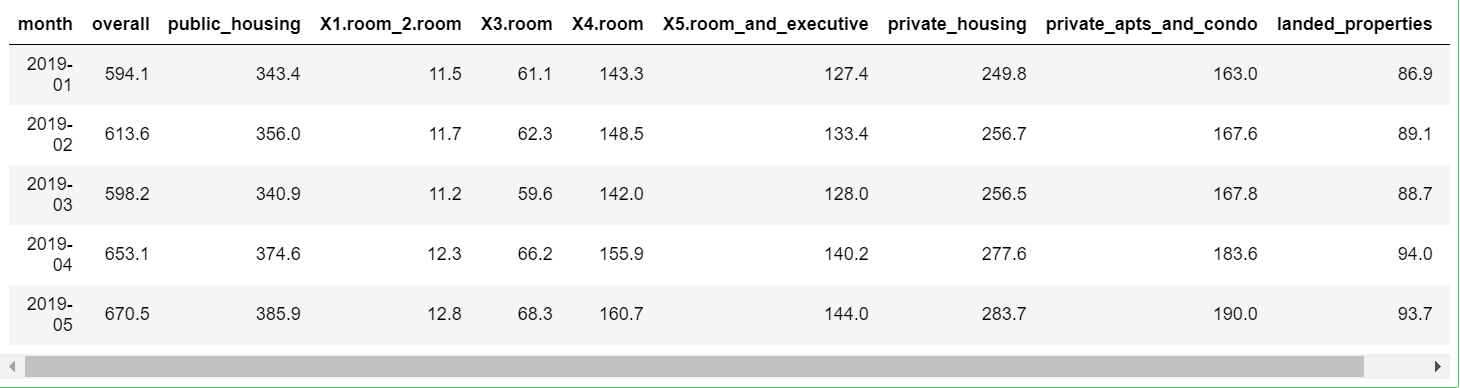
Procesamiento de datos
Antes de que podamos aplicar cualquier algoritmo de anomalía en los datos, tenemos que cambiarlo a un formato de fecha.
La columna ‘mes’ está originalmente en formato factorial con muchos niveles. Permítanos convertirlo a un tipo de fecha y seleccionar solo las columnas relevantes en el marco de datos.
str(df)
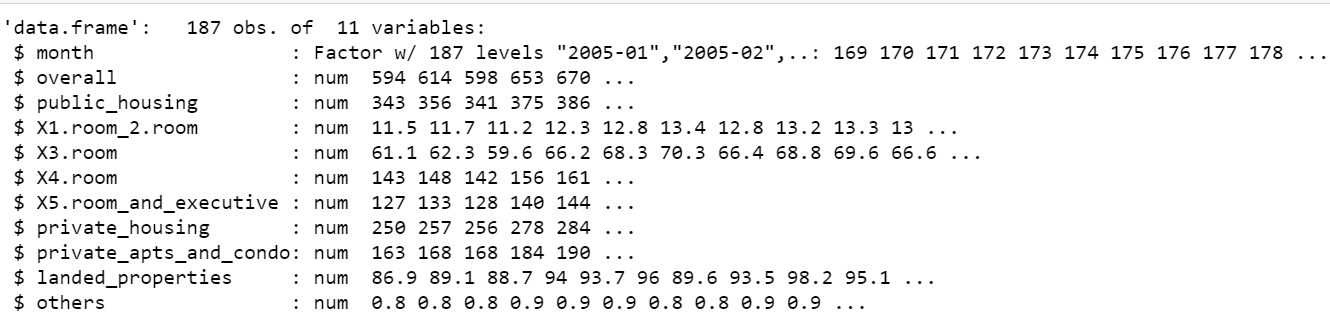
# Change Factor to Date format df$month <- paste(df$month, "01", sep="-") # Select only relevant columns in a new dataframe df$month <- as.Date(df$month,format="%Y-%m-%d")
df <- df %>% select(month,overall)
# Convert df to a tibble df <- as_tibble(df) class(df)

Usando el paquete ‘anomalize’
El paquete R ‘anomalize’ habilita un flujo de trabajo para detectar anomalías en los datos. Las funciones principales son time_decompose (), anomalizar (), y time_recompose ().
df_anomalized <- df %>%
time_decompose(overall, merge = TRUE) %>%
anomalize(remainder) %>%
time_recompose()
df_anomalized %>% glimpse()
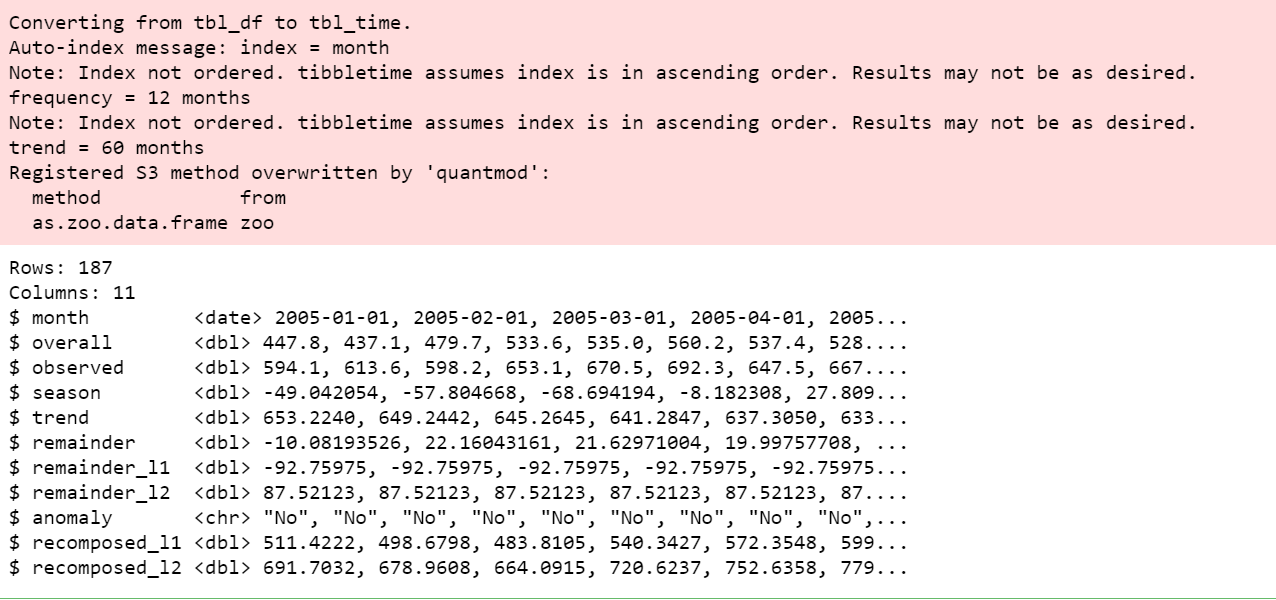
Visualiza las anomalías
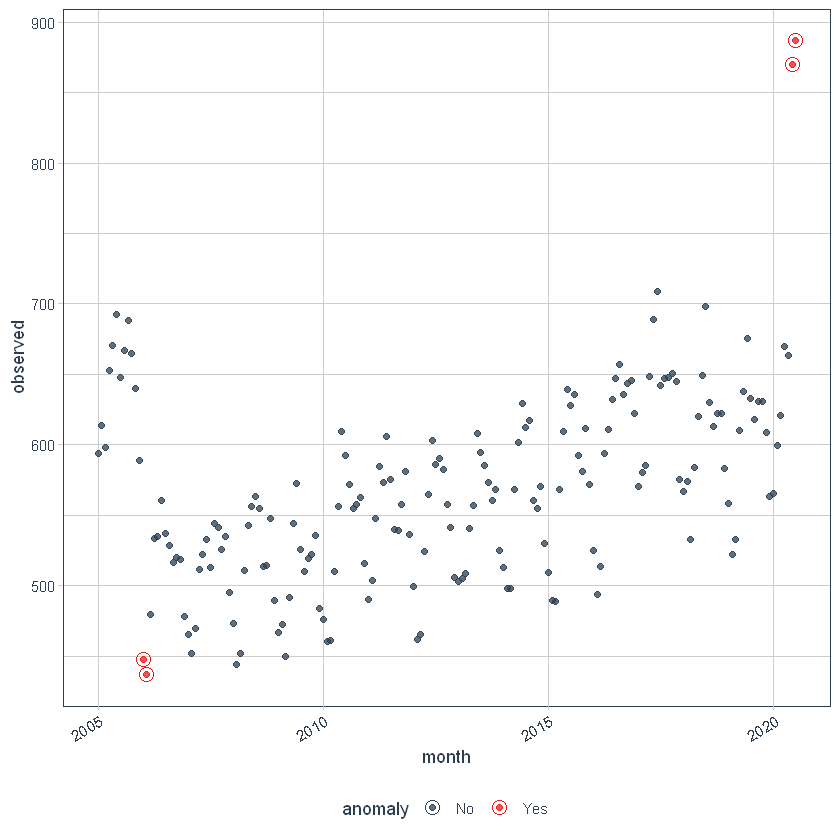
Luego podemos visualizar las anomalías usando el plot_anomalies () función.
df_anomalized %>% plot_anomalies(ncol = 3, alpha_dots = 0.75)
Ajuste de tendencia y estacionalidad
Con anomalize, es sencillo realizar ajustes porque todo se hace con una fecha o información de fecha y hora, por lo que puede seleccionar intuitivamente incrementos por períodos de tiempo que tengan sentido (por ejemplo, “5 minutos” o “1 mes”).
Primero, observe que una frecuencia y una tendencia se seleccionaron automáticamente para nosotros. Esto es por diseño. Los argumentos frecuencia = «auto» y tendencia = «auto» son los valores predeterminados. Podemos visualizar esta descomposición usando plot_anomaly_decomposition ().
p1 <- df_anomalized %>%
plot_anomaly_decomposition() +
ggtitle("Freq/Trend = 'auto'")
p1
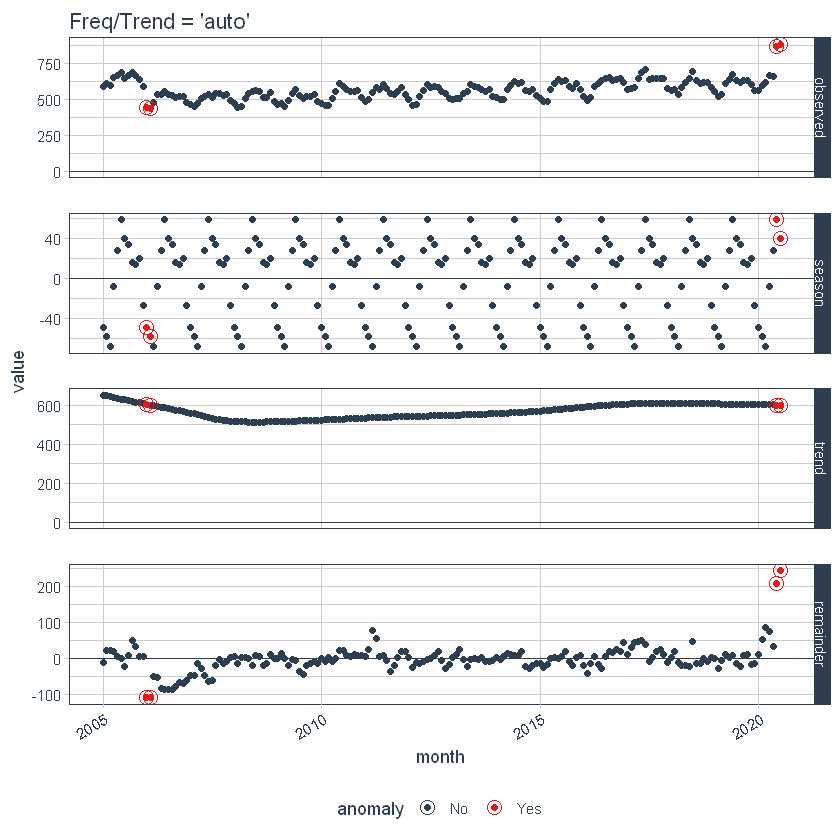
Cuando se utiliza «auto», get_time_scale_template () se utiliza para determinar la frecuencia lógica y los intervalos de tendencia en función de la escala de los datos. Puedes descubrir la lógica:
get_time_scale_template()

Esto implica que si la escala es de 1 día (lo que significa que la diferencia entre cada punto de datos es de 1 día), entonces la frecuencia será de 7 días (o 1 semana) y la tendencia será de alrededor de 90 días (o 3 meses). Esta lógica se puede ajustar fácilmente de dos formas: ajuste de parámetro local y ajuste de parámetro global.
Ajuste de los parámetros locales
El ajuste de los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... locales se realiza ajustando los parámetros en función. A continuación, ajustamos la tendencia = «2 semanas», lo que lo convierte en una tendencia bastante sobreajustada.
p2 <- df %>%
time_decompose(overall,
frequency = "auto",
trend = "2 weeks") %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
ggtitle("Trend = 2 Weeks (Local)")
# Show plots
p1
p2
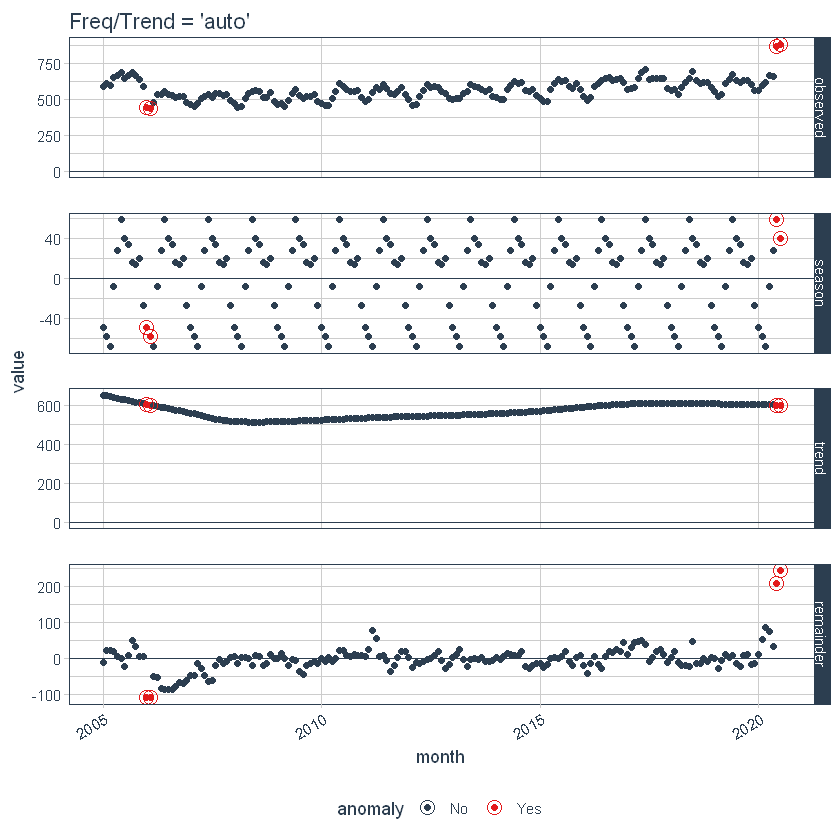
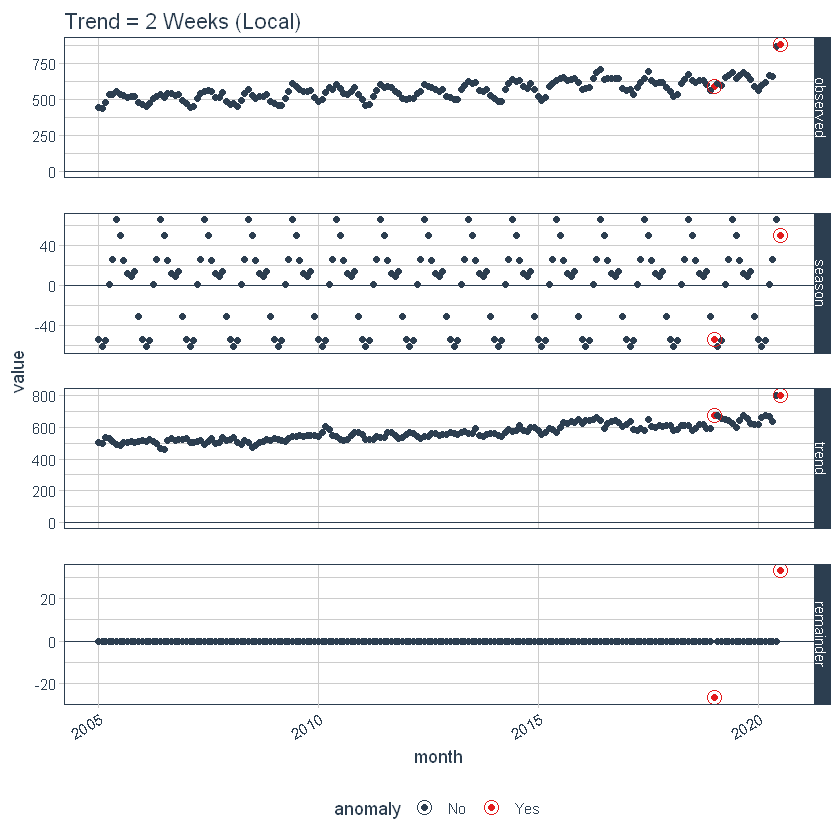
Ajuste del parámetro global
También podemos ajustarnos globalmente usando set_time_scale_template () para actualizar la plantilla predeterminada a una que prefiramos. Cambiaremos la tendencia de «3 meses» a «2 semanas» para la escala de tiempo = «día». Usar time_scale_template () para recuperar la plantilla de escala de tiempo con la que comienza la anomalía, mute () el campo de tendencia en la ubicación deseada y use set_time_scale_template () para actualizar la plantilla en las opciones globales. Podemos recuperar la plantilla actualizada usando get_time_scale_template () para verificar que el cambio se haya ejecutado correctamente.
time_scale_template() %>%
mutate(trend = ifelse(time_scale == "day", "2 weeks", trend)) %>%
set_time_scale_template()
get_time_scale_template()

Finalmente, podemos volver a ejecutar el time_decompose () con valores predeterminados, y podemos ver que la tendencia es de “2 semanas”.
p3 <- df %>%
time_decompose(overall) %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
ggtitle("Trend = 2 Weeks (Global)")
p3
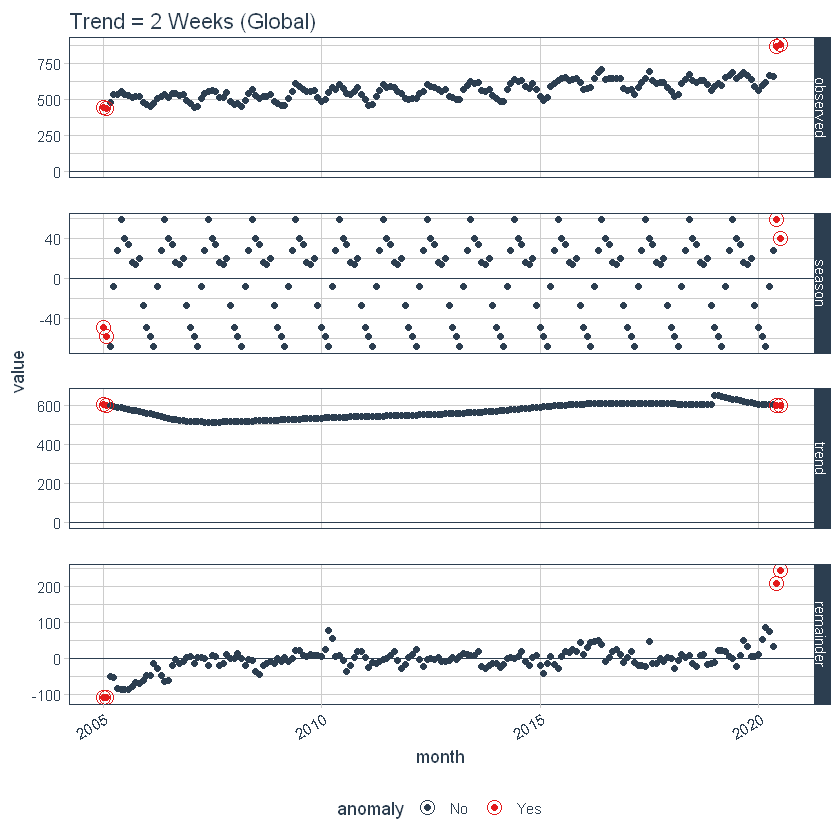
Restablezcamos los valores predeterminados de la plantilla de escala de tiempo a los valores predeterminados originales.
time_scale_template() %>%
set_time_scale_template()
# Verify the change
get_time_scale_template()

Extraer los puntos de datos anómalos
Ahora, podemos extraer los puntos de datos reales que son anomalías. Para eso, se puede ejecutar el siguiente código.
df %>% time_decompose(overall) %>% anomalize(remainder) %>% time_recompose() %>% filter(anomaly == 'Yes')

Ajustando Alpha y Max Anoms
los alfa y max_anoms son los dos parámetros que controlan la anomalizar () función. H
Alfa
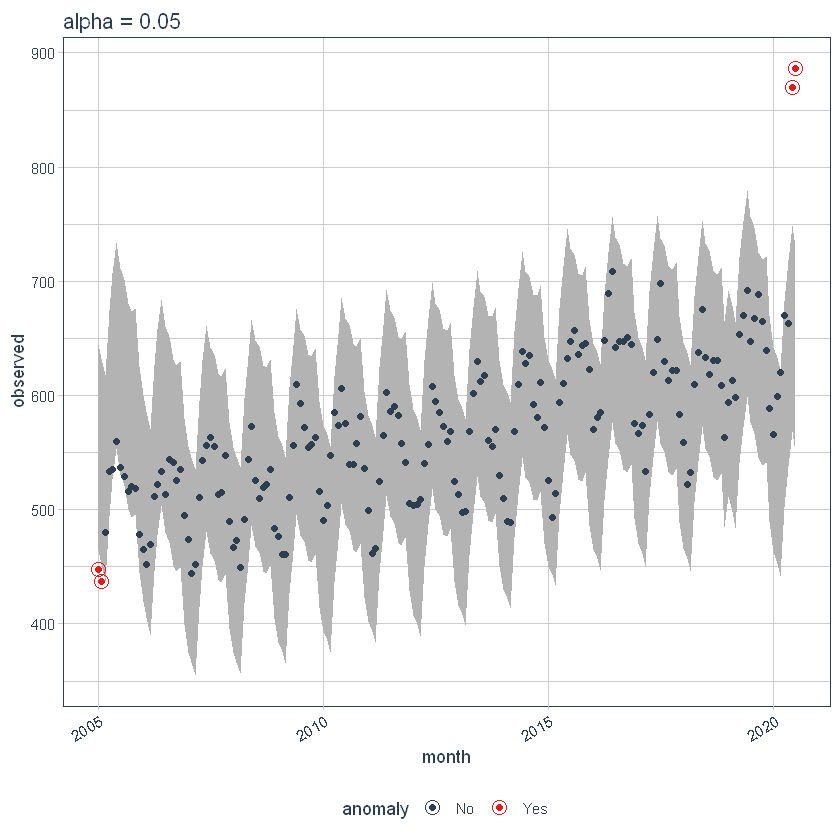
Podemos ajustar el alfa, que está configurado en 0.05 por defecto. De forma predeterminada, las bandas solo cubren el exterior del rango.
p4 <- df %>%
time_decompose(overall) %>%
anomalize(remainder, alpha = 0.05, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("alpha = 0.05")
#> frequency = 7 days
#> trend = 91 days
p4
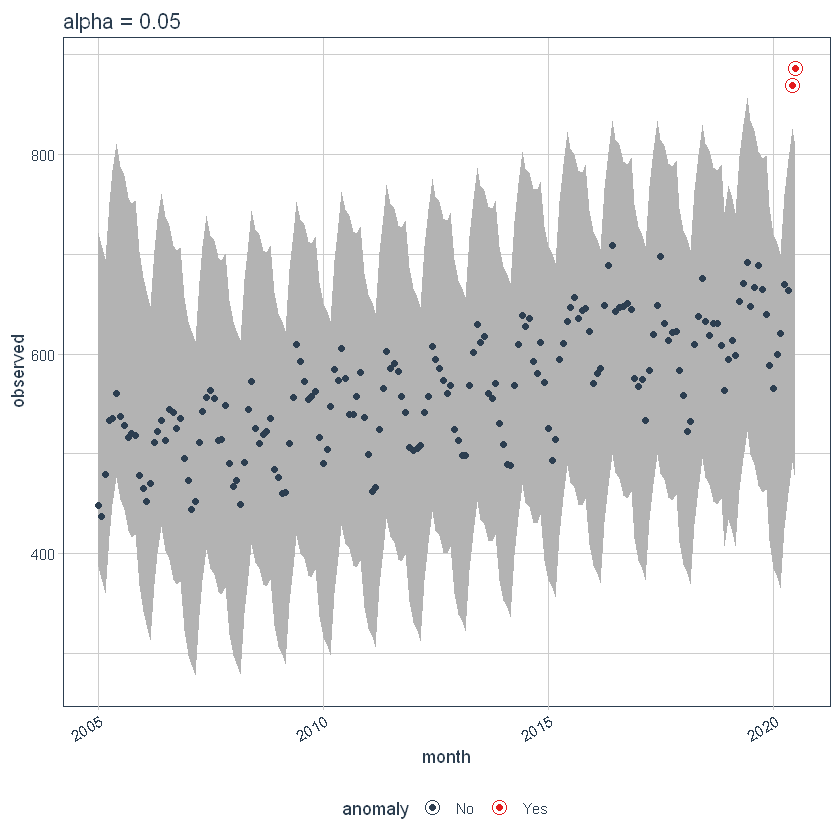
Si disminuimos el alfa, aumenta las bandas, lo que hace más difícil ser un valor atípico. Aquí, puede ver que las bandas se han vuelto dos veces más grandes.
p5 <- df %>%
time_decompose(overall) %>%
anomalize(remainder, alpha = 0.025, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("alpha = 0.05")
#> frequency = 7 days
#> trend = 91 days
p5
Max Anoms
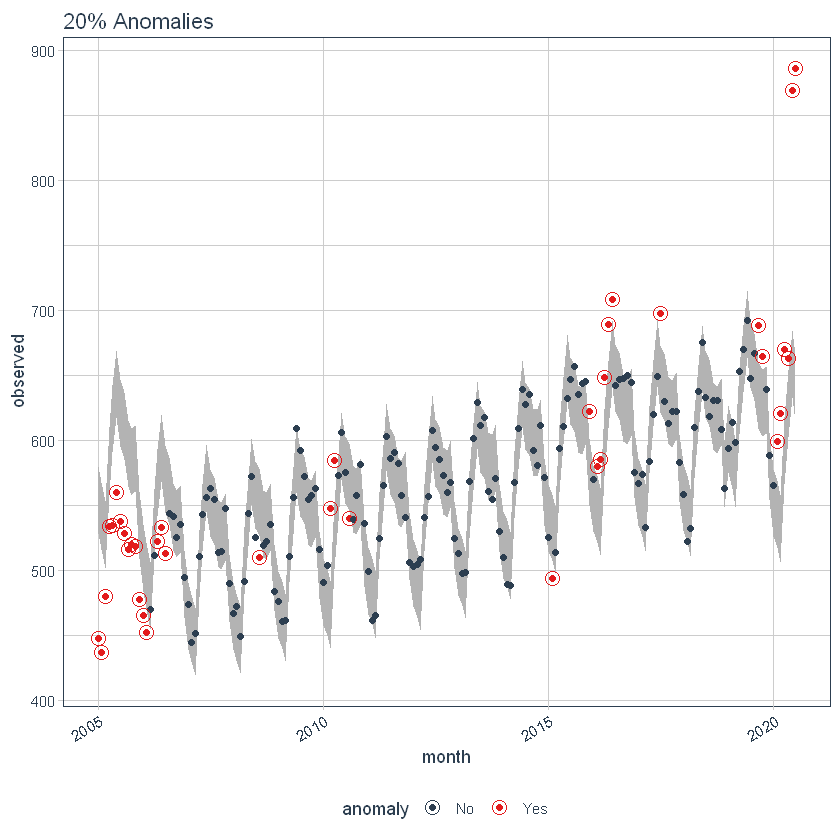
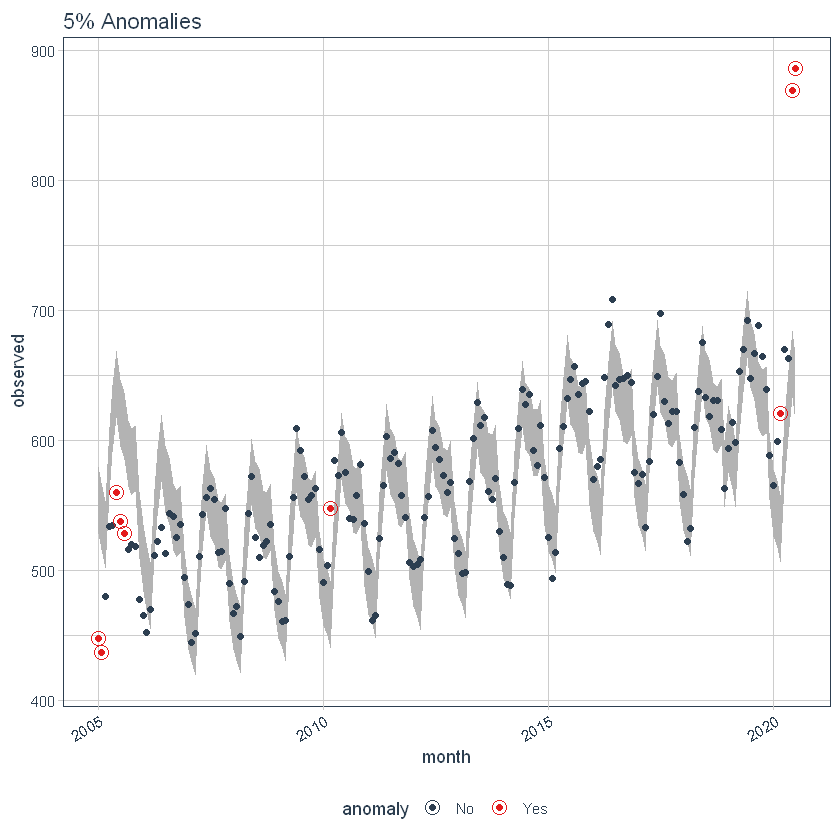
los max_anoms El parámetro se usa para controlar el porcentaje máximo de datos que pueden ser una anomalía. Ajustemos alfa = 0.3 para que prácticamente cualquier cosa sea un valor atípico. Ahora intentemos una comparación entre max_anoms = 0.2 (20% de anomalías permitidas) y max_anoms = 0.05 (5% de anomalías permitidas).
p6 <- df %>%
time_decompose(overall) %>%
anomalize(remainder, alpha = 0.3, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("20% Anomalies")
#> frequency = 7 days
#> trend = 91 days
p7 <- df %>%
time_decompose(overall) %>%
anomalize(remainder, alpha = 0.3, max_anoms = 0.05) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("5% Anomalies")
#> frequency = 7 days
#> trend = 91 days
p6
p7
Usando el paquete ‘timetk’
Es un kit de herramientas para trabajar con series temporales en R, para trazar, discutir y presentar datos de series de tiempo del ingeniero para realizar pronósticos y predicciones de aprendizaje automático.
Visualización interactiva de anomalías
Aquí, timetk’s La función plot_anomaly_diagnostics () permite modificar algunos de los parámetros sobre la marcha.
df %>% timetk::plot_anomaly_diagnostics(month,overall, .facet_ncol = 2)
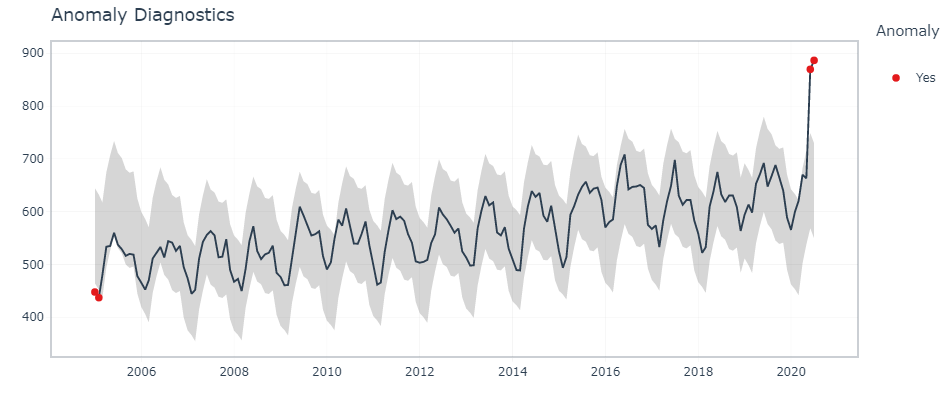
Detección interactiva de anomalías
Para encontrar los puntos de datos exactos que son anomalías, usamos tk_anomaly_diagnostics () función.
df %>% timetk::tk_anomaly_diagnostics(month, overall) %>% filter(anomaly=='Yes')

Conclusión
En este artículo, hemos visto algunos de los paquetes populares en R que se pueden usar para identificar y visualizar anomalías en una serie de tiempo. Para ofrecer algo de claridad sobre las técnicas de detección de anomalías en R, hicimos un estudio de caso en un conjunto de datos disponible públicamente. Existen otros métodos para detectar valores atípicos y también se pueden explorar.





